我用MRS-ClickHouse构建的用户画像系统,让老板拍手称赞
摘要:在移动互联网时代,用户数量庞大,标签数量众多,用户标签的数据量巨大。用户画像系统中,对于标签的存储和查询,不同的企业有不同的实现方案。当前主流的实现方案采用ElasticSearch方案。但基于ElasticSearch构建用户画像平台,往往面临灵活性不足、资源开销大、无SQL接口开发不便等问题。为此,本文提供了一种基于华为MRS ClickHouse构建用户画像系统的方法。
本文分享自华为云社区《基于MRS-ClickHouse构建用户画像系统方案介绍》,作者:hourongqi 。
1. 业务场景
用户画像是对用户信息的标签化。用户画像系统通过对收集的各维度数据,进行深度的分析和挖掘,给不同的用户打上不同的标签,从而刻画出客户的全貌。通过用户画像系统,可以对各个用户进行精准定位,从而将其应用于个性化推荐、精准营销等业务场景中。用户画像系统已经被各个企业广泛采用,是大数据落地的重要方式之一。
在移动互联网时代,用户数量庞大,标签数量众多,用户标签的数据量巨大。用户画像系统中,对于标签的存储和查询,不同的企业有不同的实现方案。当前主流的实现方案采用ElasticSearch方案。但基于ElasticSearch构建用户画像平台,往往面临灵活性不足、资源开销大、无SQL接口开发不便等问题。为此,本文提供了一种基于华为MRS ClickHouse构建用户画像系统的方法。
2. 为什么基于MRS-ClickHouse构建标签查询系统
2.1 MRS-ClickHouse简介
MRS-ClickHouse是一款面向联机分析处理的列式数据库。其最核心的特点是极致压缩率和极速查询性能。MRS-ClickHouse支持SQL查询,且查询性能好,特别是基于大宽表的聚合分析查询性能非常优异,比其他分析型数据库速度快一个数量级。
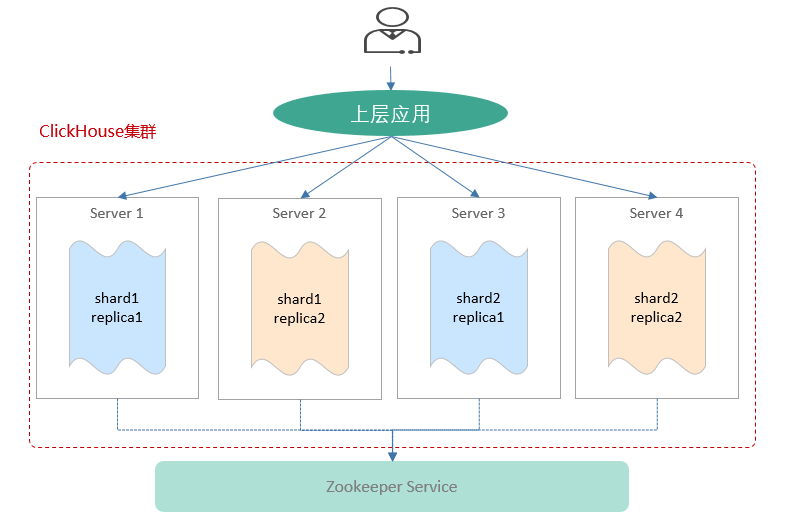
ClickHouse有如下特点:
- 完备的DBMS功能
ClickHouse拥有完备的数据库管理功能,具备一个DBMS基本的功能,包括DDL、DML、权限控制、数据备份与恢复、分布式管理。 - 列式存储与数据压缩
ClickHouse是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存。在执行数据查询时,列式存储可以减少数据扫描范围和数据传输时的大小,提高了数据查询的效率。 - 向量化执行引擎
ClickHouse利用CPU的SIMD指令实现了向量化执行。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据,通过数据并行以提高性能的一种实现方式,它的原理是在CPU寄存器层面实现数据的并行操作。 - 关系模型与SQL查询
ClickHouse完全使用SQL作为查询语言,提供了标准协议的SQL查询接口,使得现有的第三方分析可视化系统可以轻松与它集成对接。
同时ClickHouse使用了关系模型,所以将构建在传统关系型数据库或数据仓库之上的系统迁移到ClickHouse的成本会变得更低。 - 数据分片与分布式查询
ClickHouse集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限取决于节点数量(1个分片只能对应1个服务节点)。
ClickHouse提供了本地表 (Local Table)与分布式表 (Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
2.2 位图索引介绍
位图是一种通过数组下标与某些特定的值进行关联的数据结构。在位图中,每一个元素占用1个比特位。比特位为1时,表示对应的元素有该特定的值。反之则表示没有。
举例:
ID集合:[0,1,4,5,6,7,9,10,13,14]
通过位图可以表示为:11001111 01100110
如下图所示:

位图索引是一种使用位图的特殊索引,主要针对大量相同值的列而创建。位图中位置编码中的每一位表示对应的数据行的有无。位图索引适合固定值的列,如性别、婚姻状况、行政区等等。而不适合像身份证号、消费金额这种离散值的列。用户画像场景中,每一个标签,对应大量的人群。标签的数量是有限的枚举值,这一特点非常适合位图索引。
举例:
假设有两个标签,一个是标签1-持有贵金属,另一个是标签2-持有保险。各个持卡人拥有的标签情况如下表所示。
从中,我们可以看到,有标签1-持有贵金属的持卡人ID集合是:[0,1,4,5,6,7,9,10,13,14]。有标签2-持有保险的持卡人ID集群是:[2,3,5,7,8,11,12,13,15]。
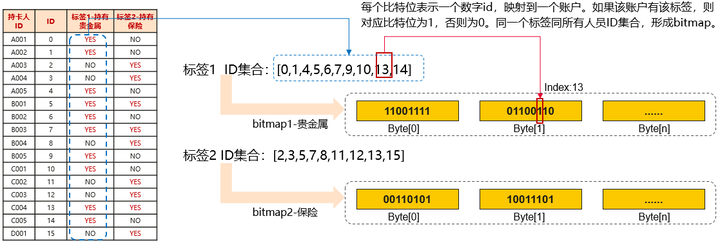
当我们需要查询同时有这个标签的用户时,基于位图索引,只需要将两个标签相应的位图进行位运算,即可得到最终结果。这样,标签数据的存储空间占用非常小,标签计算的速度非常快。

2.3 MRS-ClickHouse原生支持位图索引
在ClickHouse出现之前,如果要将位图索引应用于用户画像场景,需要自己构建位图数据结构、管理位图索引,使用门槛较高。好消息是,MRS-ClickHouse原生提供了对位图数据结构和位置索引的支持,将位图的构建及维护封装在ClickHouse内部。使用者基于ClickHouse构建位图索引变成非常的简单。
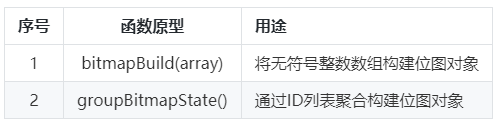
ClickHouse位图构造函数:
ClickHouse位置操作函数:
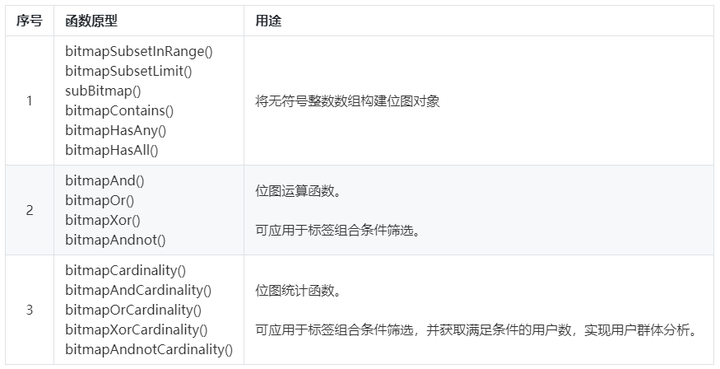
ClickHouse位图运算结果获取函数:

综上,为什么是选择基于ClickHouse构建标签查询系统?
- ClickHouse查询速度快,最快可达亚秒级响应;
- ClickHouse内置位图数据结构,方便构建位图索引,提升标签查询性能;
- 基于JDBC/SQL接口,开发更简单;
- 基于MPP架构,可横向扩展;
3. 如何基于MRS-ClickHouse构建标签查询系统
在ClickHouse中创建一张原始标签表,将原始标签数据导入其中。然后基于标签原始表构建标签位图表,并创建对应的分布式表。上层标签查询应用基于标签位图表(分布式表)进行标签查询。
流程如下图所示:
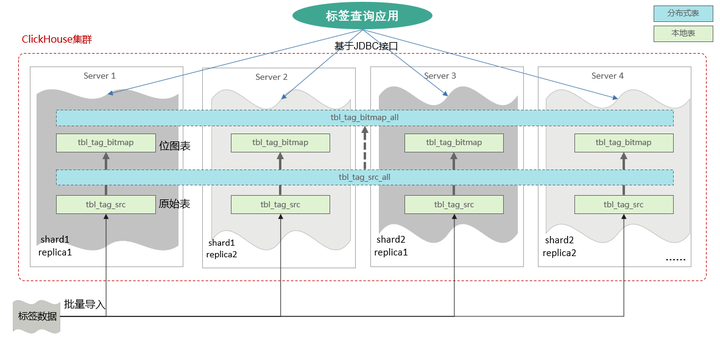
详细过程如下文所述。
Step 1:创建标签原始表,导入标签原始数据
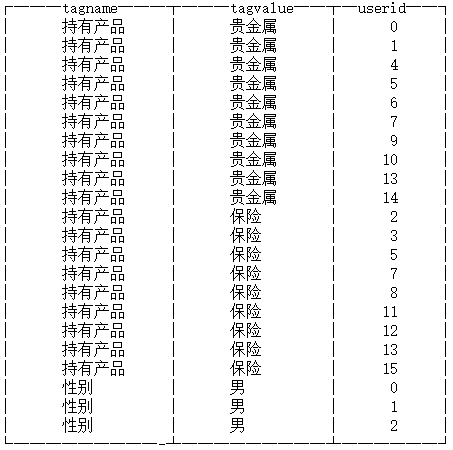
首先,创建一张标签原始表,保存标签原始数据。上游系统计算出的标签结果数据,写入本表中。本表为本地表。其建表语句如下:
CREATE TABLE IF NOT EXISTS tbl_tag_src ON CLUSTER default_cluster(
tagname String, --标签名称
tagvalue String, --标签值
userid UInt64
)ENGINE = ReplicatedMergeTree('/clickhouse/default/tables/{shard}/tbl_tag_src ','{replica}')
PARTITION BY tagname
ORDER BY tagvalue;
然后创建分布式表:
CREATE TABLE IF NOT EXISTS default.tbl_tag_src_all ON CLUSTER default_cluster
AS tbl_tag_src
ENGINE = Distributed(default_cluster, default, tbl_tag_src, rand());
数据预览如下:
Step 2:创建标签位图表,构建标签位图
创建一张标签位图表,先创建本地表。本地表用于保存标签位图数据。其创建语句如下:
-- 创建位图表,先创建本地表
CREATE TABLE IF NOT EXISTS tbl_tag_bitmap ON CLUSTER default_cluster
(
tagname String, --标签名称
tagvalue String, --标签值
tagbitmap AggregateFunction(groupBitmap, UInt64 ) --userid集合
)
ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/default/tables/{shard}/ tbl_tag_bitmap ','{replica}')
PARTITION BY tagname
ORDER BY (tagname, tagvalue)
SETTINGS index_granularity = 128;
然后再创建对应的分布式表。分布式表用于上层应用查询标签。其建表语句如下:
CREATE TABLE IF NOT EXISTS default.tbl_tag_bitmap_all ON CLUSTER default_cluster
(
tagname String, --标签名称
tagvalue String, --标签值
tagbitmap AggregateFunction(groupBitmap, UInt64 ) --userid集合
)
ENGINE = Distributed(default_cluster, default, tbl_tag_bitmap, rand());
将标签原始表的数据导入标签位图表中。并在导入过程中,使用groupBitmapState()函数构建位图。SQL语句如下:
-- 导入数据, 将同一个标签的所有userid使用groupBitmapState函数合并成一个bitmap
INSERT INTO tbl_tag_bitmap_all
SELECT tagname,tagvalue,groupBitmapState(userid)
FROM tbl_tag_src_all
GROUP BY tagname,tagvalue;
Step 3:基于分布式表快速检索标签
查询持有贵金属产品,并且性别是男的userid列表:
WITH
(
SELECT tagbitmap FROM tbl_tag_bitmap_all WHERE tagname = '持有产品' AND tagvalue = '贵金属' LIMIT 1
) AS bitmap1,
(
SELECT tagbitmap FROM tbl_tag_bitmap_all WHERE tagname = '性别' AND tagvalue = '男' LIMIT 1
) AS bitmap2
SELECT bitmapToArray(bitmapAnd(bitmap1, bitmap2)) AS res
分别统计持有保险的客户中,男性和女性的总人数:
---- 查询持有保险的客户中,男性人数:
WITH
(
SELECT tagbitmap FROM tbl_tag_bitmap_all WHERE tagname = '持有产品' AND tagvalue = '保险' LIMIT 1
) AS bitmap1,
(
SELECT tagbitmap FROM tbl_tag_bitmap_all WHERE tagname = '性别' AND tagvalue = '男' LIMIT 1
) AS bitmap2
SELECT bitmapCardinality(bitmapAnd(bitmap1, bitmap2)) AS res ---- 查询持有保险的客户中,女性人数:
WITH
(
SELECT tagbitmap FROM tbl_tag_bitmap_all WHERE tagname = '持有产品' AND tagvalue = '保险' LIMIT 1
) AS bitmap1,
(
SELECT tagbitmap FROM tbl_tag_bitmap_all WHERE tagname = '性别' AND tagvalue = '女' LIMIT 1
) AS bitmap2
SELECT bitmapCardinality(bitmapAnd(bitmap1, bitmap2)) AS res
4.总结
针对用户画像场景中的海量标签查询,传统的方案存在灵活性不足、资源消耗大、缺少SQL接口开发难度大等问题。基于华为MRS-ClickHouse,可以非常方便的构建位图索引,实现海量标签数据的实时检索。MRS-ClickHouse让开发成本大幅降低,标签查询更快响应,让精准营销更便捷。
华为云FusionInsight MRS云原生数据湖已广泛应用于政府、金融、运营商、大企业、互联网等行业,携手800+合作伙伴,服务于全球60+国家和地区3000+政企客户。
我用MRS-ClickHouse构建的用户画像系统,让老板拍手称赞的更多相关文章
- 基于MRS-ClickHouse构建用户画像系统方案介绍
业务场景 用户画像是对用户信息的标签化.用户画像系统通过对收集的各维度数据,进行深度的分析和挖掘,给不同的用户打上不同的标签,从而刻画出客户的全貌.通过用户画像系统,可以对各个用户进行精准定位,从而将 ...
- 用SparkSQL构建用户画像
用SparkSQL构建用户画像 二. 前言 大数据时代已经到来,企业迫切希望从已经积累的数据中分析出有价值的东西,而用户行为的分析尤为重要. 利用大数据来分析用户的行为与消费习惯,可以预测商品的发展 ...
- 一点做用户画像的人生经验(一):ID强打通
1. 背景 在构建精准用户画像时,面临着这样一个问题:日志采集不能成功地收集用户的所有ID,且每条业务线有各自定义的UID用来标识用户,从而造成了用户ID的零碎化.因此,为了做用户标签的整合,用户ID ...
- 个推用户画像产品(个像)iOS集成实践
最近业务方给我们部门提了新的需求,希望能构建精准用户画像.我们尝试使用的是个推(之前专门做消息推送的公司)旗下新推出的产品“个像·用户画像”.根据官方的说法,个像能够为APP开发者提供丰富的用户画像数 ...
- 一点做用户画像的人生经验:ID强打通
1. 背景 在构建精准用户画像时,面临着这样一个问题:日志采集不能成功地收集用户的所有ID,且每条业务线有各自定义的UID用来标识用户,从而造成了用户ID的零碎化.因此,为了做用户标签的整合,用户ID ...
- Spark(二)—— 标签计算、用户画像应用
一.标签计算 数据 86913510 {"reviewPics":[],"extInfoList":null,"expenseList":n ...
- 大数据时代下的用户洞察:用户画像建立(ppt版)
大数据是物理世界在网络世界的映射,是一场人类空前的网络画像运动.网络世界与物理世界不是孤立的,网络世界是物理世界层次的反映.数据是无缝连接网络世界与物理世界的DNA.发现数据DNA.重组数据DNA是人 ...
- 用Mirror,搞定用户画像
Mirror产品概述 Mirror是专为金融行业设计的全面用户画像管理系统.该系统基于星环多年来为多个金融企业客户构建用户画像的经验,深入契合业务需求,实现对用户全方位全维度的刻画.Mirror内置银 ...
- 用户画像,知乎Live总结
ttps://www.zhihu.com/lives/889189116527403008/messages 用户画像两层含义:单个标签:用户的分布 标签体系要与时俱进,如果标签被下游强依赖,则不轻易 ...
随机推荐
- ant的copy标签使用方法
对于ant里拷贝用的标签的用法,此文(来自 http://electiger.blog.51cto.com/112940/39575 )讲得很好,注意其中黑体字部分,今天被这个问题耽误了20分钟. A ...
- 你认为的.NET数据库连接池,真的是全部吗?
一般我们的项目中会使用1到2个数据库连接配置,同程艺龙的数据库连接配置被收拢到统一的配置中心,由DBA统一配置和维护,业务方通过某个字符串配置拿到的是Connection对象. DBA能在对业务方无侵 ...
- 结合场景使用Redis缓存与数据库同步
Redis缓存与MySQL数据库与同步 什么场景用到了Redis缓存? 1.广告数据 2.搜索时,分类品牌名称,分类名称和规格数据 3.购物车 4.支付 问题:如何实现? 1.广告数据 先查询Redi ...
- Python之简单的神经网络
from sklearn import datasets from sklearn import preprocessing from sklearn.model_selection import t ...
- 设计模式:单例模式的使用和实现(JAVA)
单例模式的使用 jdk和Spring都有实现单例模式,这里举的例子是JDK中Runtime这个类 Runtime的使用 通过Runtime类可以获取JVM堆内存的信息,还可以调用它的方法进行GC. p ...
- Vulnhub -- DC4靶机渗透
用nmap扫描ip和端口,发现只开启了22ssh端口和80http端口 打开网页只有一个登录界面 目录爆破没有发现什么有用的,尝试对登录进行弱口令爆破 一开始使用burpsuite,使用一个小字典进行 ...
- noip34
因为改不动T3而来水博客的屑 昨晚没睡好,大致看了一遍题面后,选择了死亡231,然后就死的很惨. T1 一开始大致看题面的时候,就略了一眼,加上没读全题,啥思路也没有,最后四十分钟滚回来看了看,发现就 ...
- noip模拟6(T2更新
由于蒟弱目前还没调出T1和T2,所以先写T3和T4.(T1T2更完辣! update in 6.12 07:19 T3 大佬 题目描述: 他发现katarina大佬真是太强了,于是就学习了一下kata ...
- JavaWeb学习笔记(五)
本文内容 1. JSP: 1. 指令 2. 注释 3. 内置对象 2. MVC开发模式 3. EL表达式 4. JSTL标签 5. 三层架构 JSP: 1. 指令 * 作用:用于配置JSP页面,导入资 ...
- spring cloud 的hystrix 熔断器 和feign 调用的使用
1, 添加依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId&g ...