Kubernetes使用Keda进行弹性伸缩,更合理利用资源
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶!
1 简介
Kubernetes自带的HPA是只支持CPU/MEM的,很多时候我们并不根据这两项指标来进行伸缩资源。比如消费者不断处理MQ的消息,我们希望MQ如果堆积过多,就启动更多的消费者来处理任务。而Keda给了我们很多选择。
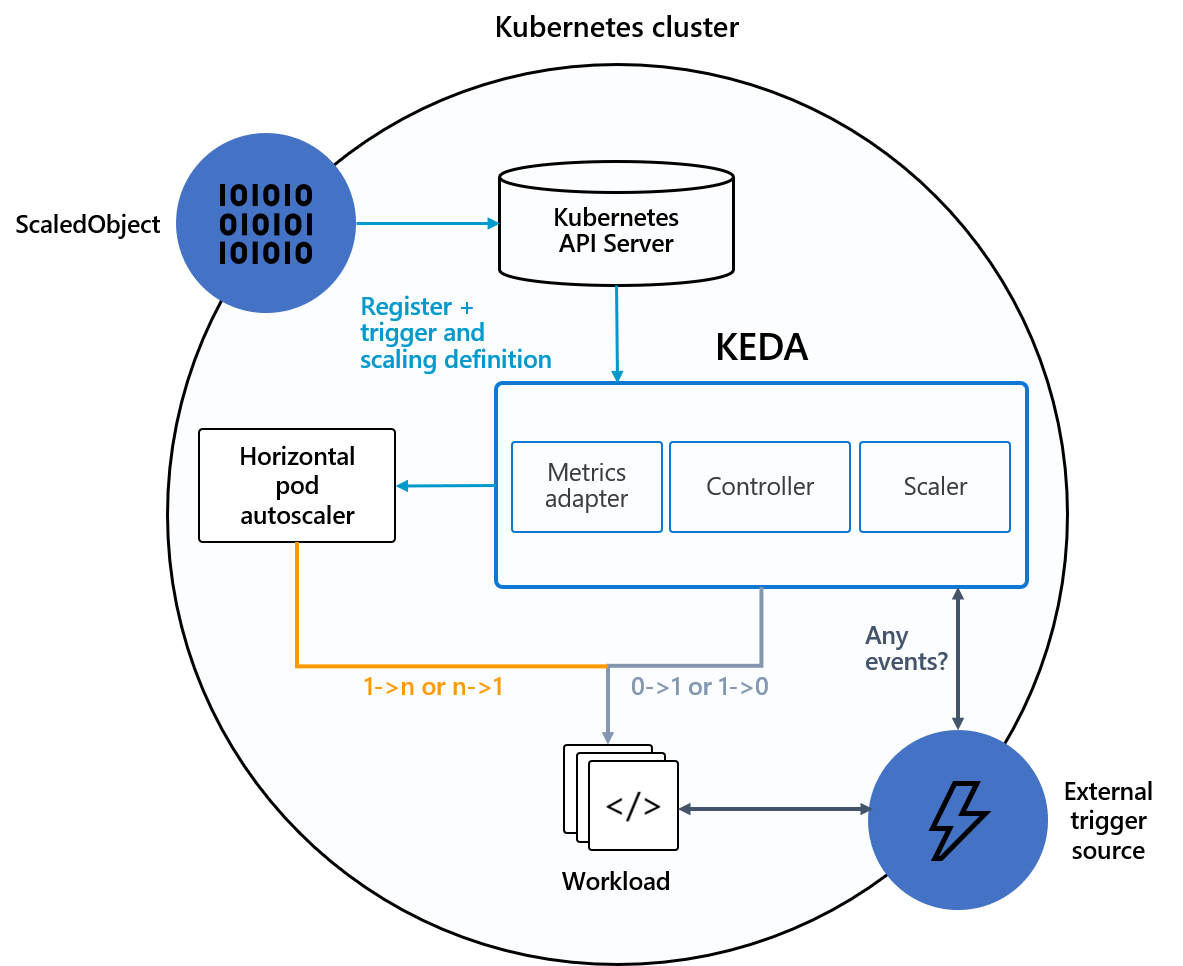
KEDA 是 Kubernetes 基于事件驱动的自动伸缩工具,通过 KEDA 我们可以根据需要处理的事件数量来驱动 Kubernetes 中任何容器的扩展。KEDA 可以直接部署到任何 Kubernetes 集群中和标准的组件一起工作。
Keda所支持的事件源非常丰富,本文我们以RabbitMQ为例进行演示。

2 安装Keda
安装的方法很多,我们直接通过yaml文件来安装,这样还可以修改镜像地址等。先从( https://github.com/kedacore/keda/releases/download/v2.2.0/keda-2.2.0.yaml )下载yaml文件,然后执行:
$ kubectl apply -f ~/Downloads/keda-2.2.0.yaml
namespace/keda created
customresourcedefinition.apiextensions.k8s.io/clustertriggerauthentications.keda.sh created
customresourcedefinition.apiextensions.k8s.io/scaledjobs.keda.sh created
customresourcedefinition.apiextensions.k8s.io/scaledobjects.keda.sh created
customresourcedefinition.apiextensions.k8s.io/triggerauthentications.keda.sh created
serviceaccount/keda-operator created
clusterrole.rbac.authorization.k8s.io/keda-external-metrics-reader created
clusterrole.rbac.authorization.k8s.io/keda-operator created
rolebinding.rbac.authorization.k8s.io/keda-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/keda-hpa-controller-external-metrics created
clusterrolebinding.rbac.authorization.k8s.io/keda-operator created
clusterrolebinding.rbac.authorization.k8s.io/keda:system:auth-delegator created
service/keda-metrics-apiserver created
deployment.apps/keda-metrics-apiserver created
deployment.apps/keda-operator created
apiservice.apiregistration.k8s.io/v1beta1.external.metrics.k8s.io created
检查一下是否都已经启动完成:
$ kubectl get all -n keda
NAME READY STATUS RESTARTS AGE
pod/keda-metrics-apiserver-55dc9f9498-smc2d 1/1 Running 0 2m41s
pod/keda-operator-59dcf989d6-pxcbb 1/1 Running 0 2m41s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-metrics-apiserver ClusterIP 10.104.255.44 <none> 443/TCP,80/TCP 2m41s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-metrics-apiserver 1/1 1 1 2m42s
deployment.apps/keda-operator 1/1 1 1 2m42s
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-metrics-apiserver-55dc9f9498 1 1 1 2m42s
replicaset.apps/keda-operator-59dcf989d6 1 1 1 2m42s
也可以看到镜像多了:
$ docker images | grep keda
ghcr.io/kedacore/keda-metrics-apiserver 2.2.0 a43d40453368 6 weeks ago 95.3MB
ghcr.io/kedacore/keda 2.2.0 42b88f042914 6 weeks ago 83MB
如果要卸载请执行:
$ kubectl delete -f ~/Downloads/keda-2.2.0.yaml
3 安装RabbitMQ
为了快速安装,也方便日后删除,我们通过Helm来安装RabbitMQ。
查看可用的chart:
$ helm search repo rabbit
执行安装:
$ helm install azure-rabbitmq azure/rabbitmq
检查一下:
$ helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
azure-ingress default 1 2021-02-14 01:21:07.212107 +0800 CST deployed nginx-ingress-1.41.3 v0.34.1
azure-rabbitmq default 1 2021-05-05 11:29:06.979437 +0800 CST deployed rabbitmq-6.18.2 3.8.2
用户名为user,密码获取如下:
$ echo "Password : $(kubectl get secret --namespace default azure-rabbitmq -o jsonpath="{.data.rabbitmq-password}" | base64 --decode)"
Password : YNsEayx8w2
4 测试
部署消费者,注意这里有个MQ连接信息和加密,要根据自己情况修改。
$ kubectl apply -f src/main/kubernetes/deploy-consumer.yaml
secret/rabbitmq-consumer-secret created
deployment.apps/rabbitmq-consumer created
scaledobject.keda.sh/rabbitmq-consumer created
triggerauthentication.keda.sh/rabbitmq-consumer-trigger created
查看deployment,发现是没有Pod创建,因为还不需要处理,MQ现在的队列为0。
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
azure-ingress-nginx-ingress-controller 1/1 1 1 80d
azure-ingress-nginx-ingress-default-backend 1/1 1 1 80d
rabbitmq-consumer 0/0 0 0 131m
部署生产者,往MQ发送消息:
$ kubectl apply -f src/main/kubernetes/deploy-publisher-job.yaml
job.batch/rabbitmq-publish created
可以看到,慢慢消费者就起来了,并且创建了越来越多的Pod来处理MQ:
$ kubectl get deployments rabbitmq-consumer
NAME READY UP-TO-DATE AVAILABLE AGE
rabbitmq-consumer 1/1 1 1 167m
$ kubectl get deployments rabbitmq-consumer
NAME READY UP-TO-DATE AVAILABLE AGE
rabbitmq-consumer 3/4 4 3 168m
$ kubectl get deployments rabbitmq-consumer
NAME READY UP-TO-DATE AVAILABLE AGE
rabbitmq-consumer 4/8 8 4 168m
$ kubectl get deployments rabbitmq-consumer
NAME READY UP-TO-DATE AVAILABLE AGE
rabbitmq-consumer 6/8 8 6 169m
$ kubectl get deployments rabbitmq-consumer
NAME READY UP-TO-DATE AVAILABLE AGE
rabbitmq-consumer 0/0 0 0 171m
查看Deployment的Event也可以看到结果:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m55s (x2 over 172m) deployment-controller Scaled up replica set rabbitmq-consumer-7b477f78b4 to 1
Normal ScalingReplicaSet 5m6s deployment-controller Scaled up replica set rabbitmq-consumer-7b477f78b4 to 4
Normal ScalingReplicaSet 4m6s deployment-controller Scaled up replica set rabbitmq-consumer-7b477f78b4 to 8
Normal ScalingReplicaSet 3m5s deployment-controller Scaled up replica set rabbitmq-consumer-7b477f78b4 to 16
Normal ScalingReplicaSet 3m3s (x2 over 172m) deployment-controller Scaled down replica set rabbitmq-consumer-7b477f78b4 to 0
处理完成后,又会回到0了。
总结
代码请查看:https://github.com/LarryDpk/pkslow-samples
欢迎关注微信公众号<南瓜慢说>,将持续为你更新...

多读书,多分享;多写作,多整理。
Kubernetes使用Keda进行弹性伸缩,更合理利用资源的更多相关文章
- Docker(三):利用Kubernetes实现容器的弹性伸缩
一.前言 前两章有的介绍docker与Kubernetes.docker是项目运行的容器,Kubernetes则是随着微服务架构的演变docker容器增多而进行其编排的重要工具.Kubernetes不 ...
- 使用 tke-autoscaling-placeholder 实现秒级弹性伸缩
背景 当 TKE 集群配置了节点池并启用了弹性伸缩,在节点资源不够时可以触发节点的自动扩容 (自动买机器并加入集群),但这个扩容流程需要一定的时间才能完成,在一些流量突高的场景,这个扩容速度可能会显得 ...
- kubernetes 降本增效标准指南| 容器化计算资源利用率现象剖析
作者:詹雪娇,腾讯云容器产品经理,目前主要负责腾讯云集群运维中心的产品工作. 张鹏,腾讯云容器产品工程师,拥有多年云原生项目开发落地经验.目前主要负责腾讯云TKE集群和运维中心开发工作. 引言 降本增 ...
- Kubernetes 弹性伸缩全场景解读(五) - 定时伸缩组件发布与开源
作者| 阿里云容器技术专家刘中巍(莫源) 导读:Kubernetes弹性伸缩系列文章为读者一一解析了各个弹性伸缩组件的相关原理和用法.本篇文章中,阿里云容器技术专家莫源将为你带来定时伸缩组件 kub ...
- Kubernetes 弹性伸缩全场景解析(三) - HPA 实践手册
在上一篇文章中,给大家介绍和剖析了 HPA 的实现原理以及演进的思路与历程.本文我们将会为大家讲解如何使用 HPA 以及一些需要注意的细节. autoscaling/v1 实践 v1 的模板可能是大家 ...
- Kubernetes 弹性伸缩全场景解读(二)- HPA 的原理与演进
前言 在上一篇文章 Kubernetes 弹性伸缩全场景解析 (一):概念延伸与组件布局中,我们介绍了在 Kubernetes 在处理弹性伸缩时的设计理念以及相关组件的布局,在今天这篇文章中,会为大家 ...
- Kubernetes 弹性伸缩HPA功能增强Advanced Horizontal Pod Autoscaler -介绍部署篇
背景 WHAT(做什么) Advanced Horizontal Pod Autoscaler(简称:AHPA)是kubernetes中HPA的功能增强. 在兼容原生HPA功能基础上,增加预测.执行模 ...
- Kubernetes弹性伸缩全场景解读(五) - 定时伸缩组件发布与开源
前言 容器技术的发展让软件交付和运维变得更加标准化.轻量化.自动化.这使得动态调整负载的容量变成一件非常简单的事情.在kubernetes中,通常只需要修改对应的replicas数目即可完成.当负载的 ...
- Kubernetes 弹性伸缩全场景解析 (四)- 让核心组件充满弹性
前言 在本系列的前三篇中,我们介绍了弹性伸缩的整体布局以及HPA的一些原理,HPA的部分还遗留了一些内容需要进行详细解析.在准备这部分内容的期间,会穿插几篇弹性伸缩组件的最佳实践.今天我们要讲解的是 ...
随机推荐
- [网络编程之客户端/服务器架构,互联网通信协议,TCP协议]
[网络编程之客户端/服务器架构,互联网通信协议,TCP协议] 引子 网络编程 客户端/服务器架构 互联网通信协议 互联网的本质就是一系列的网络协议 OSI七层协议 tcp/ip五层模型 客户端/服务器 ...
- MSSQL·查看数据库编码格式
阅文时长 | 0.67分钟 字数统计 | 837.6字符 主要内容 | 1.引言&背景 2.声明与参考资料 『MSSQL·查看数据库编码格式』 编写人 | SCscHero 编写时间 | 20 ...
- [bug] Springboot JPA使用Sort排序时的问题
参考 https://blog.csdn.net/qq_44039966/article/details/102713779
- curl: (35) SSL connect error
curl: (35) SSL connect error weixin_34212762 2018-02-23 20:16:23 230 收藏 文章标签: 运维 版权 阿里云的机器,昨晚githu ...
- Linux进阶之seq,pidof,wget,curl,tr,grep命令
本节内容 seq pidof wget curl tr grep 1.seq(sequence) 生成数列 例子1:指定结束位置 [root@renyz ~]# seq 5 1 2 3 4 ...
- HTML的一些标签以及表单
HTML的一些标签以及表单 图片标签 属性 说明 src 图像的路径 alt 图像不能显示时的替换文字 title 鼠标悬停时显示的内容 border 设置图像边框的宽度 align 对齐方式 相对路 ...
- xss-代码角度理解与绕过filter
0x00 原理 xss全称为cross site scripting,中文为跨站脚本攻击.它允许web用户将恶意代码植入到提供给用户使用的页面.代码包括HTML代码和客户端脚本. 0x01 危害 ...
- .Net RabbitMQ实战指南——RabbitMQ相关概念介绍
什么是消息中间件 消息(Message)是指在应用间传送的数据.消息可以非常简单,比如只包含文本字符串.JSON等,也可以很复杂,比如内嵌对象. 消息队列中间件(Message Queue Middl ...
- App自动化测试之Appium环境安装(涉及雷电模拟器和真机)
1.安装Microsoft .NET Framework 4.5 及以上版本 2.安装Appium 官方网站地址:http://appium.io/ 我装了1.17.0版本 3.安装JDK 1.8及以 ...
- 使用ubuntu charmed kubernetes 部署一套生产环境的集群
官方文档: https://ubuntu.com/kubernetes/docs 搭建一个基本的集群 集群ip规划 hostname ip ubuntu-1 10.0.0.10 juju-contro ...