Hive之同比环比的计算
Hive系列文章
- Hive表的基本操作
- Hive中的集合数据类型
- Hive动态分区详解
- hive中orc格式表的数据导入
- Java通过jdbc连接hive
- 通过HiveServer2访问Hive
- SpringBoot连接Hive实现自助取数
- hive关联hbase表
- Hive udf 使用方法
- Hive基于UDF进行文本分词
- Hive窗口函数row number的用法
- 数据仓库之拉链表
关注公众号:
大数据技术派,回复:资料,领取1024G资料。
同比环比的计算
测试数据
1,2020-04-20,420
2,2020-04-04,800
3,2020-03-28,500
4,2020-03-13,100
5,2020-02-27,300
6,2020-01-07,450
7,2019-04-07,800
8,2019-03-15,1200
9,2019-02-17,200
10,2019-02-07,600
11,2019-01-13,300
CREATE TABLE ods_saleorder (
order_id int ,
order_time date ,
order_num int
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
;
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/workspace/hive/saleorder.txt' OVERWRITE INTO TABLE ods.ods_saleorder;
销售量的月年占比
关联实现
select
a.m_num,a.cmonth,b.y_num,b.cyear,round( m_num / y_num, 2 ) AS ratio
from(
select
sum(order_num) as m_num,
DATE_FORMAT(order_time,'yyyy-MM') as cmonth
from
ods_saleorder
group by
DATE_FORMAT(order_time,'yyyy-MM')
) a
inner join
(
select
sum(order_num) as y_num,
DATE_FORMAT(order_time,'yyyy') as cyear
from
ods_saleorder
group by
DATE_FORMAT(order_time,'yyyy')
) b
on
substring(a.cmonth,1,4)=b.cyear
;
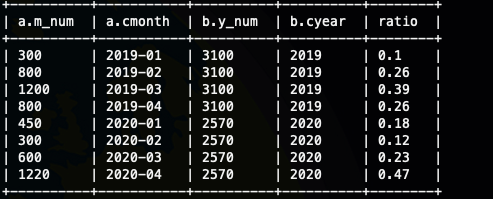
窗口实现
SELECT
order_month,
num,
total,
round( num / total, 2 ) AS ratio
FROM
(
select
substr(order_time, 1, 7) as order_month,
sum(order_num) over (partition by substr(order_time, 1, 7)) as num,
sum(order_num) over (partition by substr( order_time, 1, 4 ) ) total,
row_number() over (partition by substr(order_time, 1, 7)) as rk
from ods_saleorder
) temp
where rk = 1;
同比环比
与上年度数据对比称"同比",与上月数据对比称"环比"。
相关公式如下:
同比增长率计算公式
(当年值-上年值)/上年值x100%
环比增长率计算公式
(当月值-上月值)/上月值x100%
lead lag 的实现
这里我们就用环比做个例子,同比类似
select
now_month,
now_num,
last_num,
round( (now_num-last_num) / last_num, 2 ) as ratio
FROM(
select
now_month,
now_num,
lag( t1.now_num, 1) over (order by t1.now_month ) as last_num
from
(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) t1
) t2;
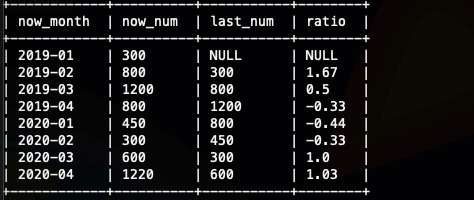
我们看到有null 值,这里我们可以使用,lag的默认值做一次优化
select
now_month,
now_num,
last_num,
-- 分母是0的话返回值是null
nvl(round( (now_num-last_num) / last_num, 2 ),0)as ratio
FROM(
select
now_month,
now_num,
lag( t1.now_num, 1,0) over (order by t1.now_month ) as last_num
from
(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) t1
) t2;
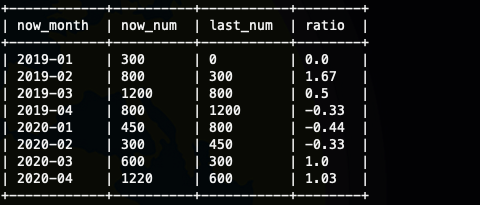
其实到这里我们就处理完了,但是这样真的对吗,我们看到'2020-01' 的last_num 是800 也就是'2019-04',其实到这里我们就明白了,我们的数据是不连续的,所以我们这样计算是不行的,如果每个月都齐全,都有数据lag(num,12)就可以。
那就只能做自关联了,这样的话我们可以对时间做精准的限制
自关联的实现
with a as (
select
now_month,
now_num,
substr(date(concat(now_month,'-','01')) - INTERVAL '1' month, 1, 7) as last_month
from(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) tmp
)
select
a1.now_month,a1.now_num,a1.last_month,a2.now_num,
nvl(round( (a1.now_num-a2.now_num) / a2.now_num, 2 ),0) as ratio
from
a a1
inner join
a a2
on
a1.last_month=a2.now_month
;
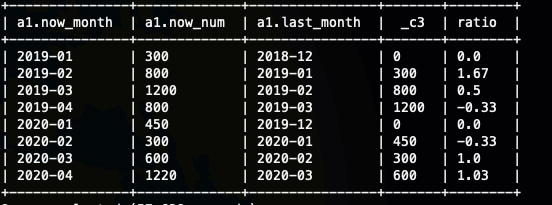
这里的时间计算INTERVAL 你也可以换成其他函数
with a as (
select
now_month,
now_num,
substr(add_months(concat(now_month,'-','01'),-1), 1, 7) as last_month
from(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) tmp
)
select
a1.now_month,a1.now_num,a1.last_month,nvl(a2.now_num,0),
nvl(round( (a1.now_num-a2.now_num) / a2.now_num, 2 ),0) as ratio
from
a a1
left join
a a2
on
a1.last_month=a2.now_month
;
猜你喜欢
Hive之同比环比的计算的更多相关文章
- 再谈Cognos利用FM模型来做同比环比
很早之前已经讲过 <Cognos利用DMR模型开发同比环比>这篇文章里说的是不利用过滤器,而是采用 except (lastPeriods (-9000,[订单数据分析].[日期维度].[ ...
- cognos report同比环比以及默认为当前月分析
现在的需求是按月份分析不同时期的余额数据,.(报表工具:cognos report:建模工具:FM) ------------------------------------------------- ...
- MySQL统计同比环比SQL
大体思路: MySQL没有类似oracle方便的统计函数,只能靠自己去硬计算:通过时间字段直接增加年份.月份,然后通过left join关联时间字段去计算环比.同比公式即可 原始表结构: 求同比SQL ...
- Oracle分析函数/排名函数/位移函数/同比环比
分析函数 作用:分析函数可以在数据中进行分组,然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值.统计函数:MAX(字段名).MIN(字段名).AVG(字段名).SUM(字段名).CO ...
- 【hive】关于用户留存率的计算
首先用户留存率一般是面向新增用户的概念,是指某一天注册后的几天还是否活跃,是以每天为单位进行计算的.一般收到的需求都是一个时间段内的新增用户的几天留存 (1)找到这个时间段内的新增用户(也可能含有地区 ...
- 数据可视化之DAX篇(十二)掌握时间智能函数,同比环比各种比,轻松搞定!
https://zhuanlan.zhihu.com/p/55841964 时间可以说是数据分析中最常用的独立变量,工作中也常常会遇到对时间数据的对比分析.假设要计算上年同期的销量,在PowerBI中 ...
- MDX 占比同比环比
http://blog.csdn.net/hero_hegang/article/details/9072889
- 实现同比、环比计算的N种姿势
在做数据分析时,我们会经常听到同比.环比同比的概念.各个企业和组织在发布统计数据时,通常喜欢用同比.环比来和之前的历史数据进行比较,用来说明数据的变化情况.例如,统计局公布2022年1月份CPI同比增 ...
- 同比 VS 环比
同比(YoY=year on year):与历史同时期比较,例如2014年7月份与2013年7月份相比,叫同比 环比(MoM=month on month):是本期统计数据与上期比较,例如2014年7 ...
随机推荐
- Servlet初级学习加入数据库操作(二)
源代码地址:https://url56.ctfile.com/f/34653256-527822631-2e255a(访问密码:7567) 将页面中的数据逐步替换为数据库管理 准备一个连接数据库的类 ...
- [转]axios请求超时,设置重新请求的完美解决方法
自从使用Vue2之后,就使用官方推荐的axios的插件来调用API,在使用过程中,如果服务器或者网络不稳定掉包了, 你们该如何处理呢? 下面我给你们分享一下我的经历. 具体原因 最近公司在做一个项目, ...
- 2018HPU暑期集训第四次积分训练赛 K - 方框 题解(图形打印)
思路分析:题目已经明确透露了这道题的解法:就是画框.当 输入的边长 的话,就表示可以在内层继续嵌套一个方框.废话就不多说了,直接上代码吧! 代码如下: #include <iostream&g ...
- HDU 2099 整除的尾数(枚举 & 暴搜)
原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=2099 思路分析:这道题的解法可以说是相当暴力了,但也有一些小坑,以下几点萌新们值得留意一下: 1. 仔 ...
- Hello world.java
Hello world 1.随便新建一个文件夹,存放源代码 2.新建一个Java文件 文件后缀名为.java Hello.java [注意点]系统可能显示没有后缀名,我们需要手动打开 3.编写代码 p ...
- [MAUI] 在.NET MAUI中结合Vue实现混合开发
在MAUI微软的官方方案是使用Blazor开发,但是当前市场大多数的Web项目使用Vue,React等技术构建,如果我们没法绕过已经积累的技术,用Blazor重写整个项目并不现实. Vue是当前流 ...
- RHCSA 第二天
1.Linux中的文件类型以及符号的表示 (1) 普通文件: 使用 ls -l 命令后,第一列第一个字符为 "-" 的文件为普通文件,如上图所示,普通文件一般为灰色字体,绿色字体的 ...
- vivo推送平台架构演进
本文根据Li Qingxin老师在"2021 vivo开发者大会"现场演讲内容整理而成.公众号回复[2021VDC]获取互联网技术分会场议题相关资料. 一.vivo推送平台介绍 1 ...
- Solon Web 开发,九、跨域处理
Solon Web 开发 一.开始 二.开发知识准备 三.打包与运行 四.请求上下文 五.数据访问.事务与缓存应用 六.过滤器.处理.拦截器 七.视图模板与Mvc注解 八.校验.及定制与扩展 九.跨域 ...
- zabbix安装 报错 socket '/var/lib/mysql/mysql.sock' (13)]
安装界面提示: Error connecting to database: Can't connect to local MySQL server through socket '/var/lib/m ...