练习推导一个最简单的BP神经网络训练过程【个人作业/数学推导】
写在前面
各式资料中关于BP神经网络的讲解已经足够全面详尽,故不在此过多赘述。本文重点在于由一个“最简单”的神经网络练习推导其训练过程,和大家一起在练习中一起更好理解神经网络训练过程。
一、BP神经网络
1.1 简介
BP网络(Back-Propagation Network) 是1986年被提出的,是一种按误差逆向传播算法训练的
多层前馈网络,是目前应用最广泛的神经网络模型之一,用于函数逼近、模型识别分类、数据压缩和时间序列预测等。
一个典型的BP网络应该包括三层:输入层、隐藏层和输出层。各层之间全连接,同层之间无连接。隐藏层可以有很多层。
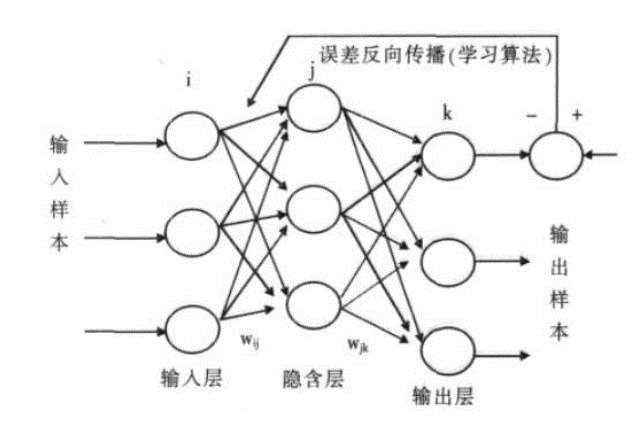
Fig 1 数字图像与对应矩阵图示
1.2 训练(学习)过程
每一次迭代(Interation)意味着使用一批(Batch)数据对模型进行一次更新过程,被称为“一次训练”,包含一个正向过程和一个反向过程。
具体过程可以概括为如下过程:
- 准备样本信息(数据&标签)、定义神经网络(结构、初始化参数、选取激活函数等)
- 将样本输入,正向计算各节点函数输出
- 计算损失函数
- 求损失函数对各权重的偏导数,采用适当方法进行反向过程优化
- 重复2~4直至达到停止条件
以下训练将使用均值平方差(Mean Squared Error, MSE)作为损失函数,sigmoid函数作为激活函数、梯度下降法作为优化权重方法进行推导
二、实例推导练习作业
2.1 准备工作
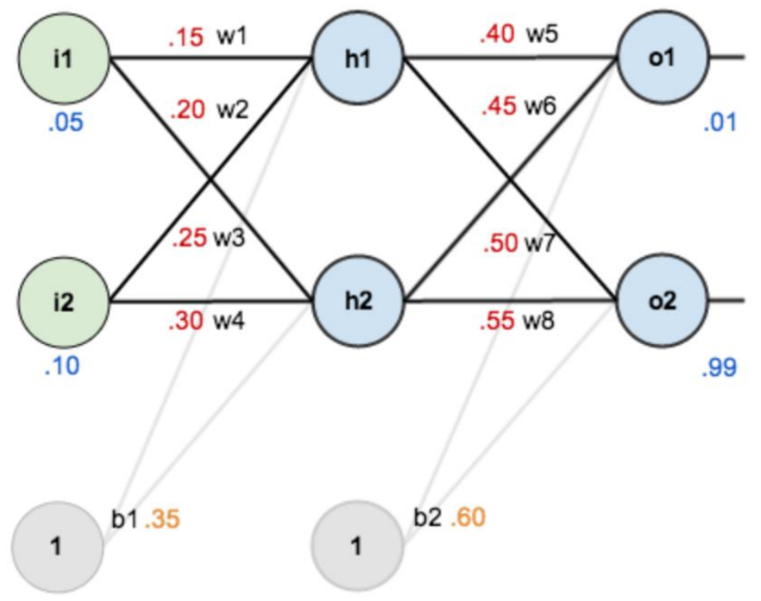
Fig 2 所定义神经网络、初始化参数、样本信息等
- 第一层是输入层,包含两个神经元: i1, i2 和偏置b1
- 第二层是隐藏层,包含两个神经元: h1, h2 和偏置项b2
- 第三层是输出: o1, o2
- 每条线上标的 wi 是层与层之间连接的权重
- 激活函数是 sigmod 函数
- 我们用 z 表示某神经元的加权输入和,用 a 表示某神经元的输出
2.2 第一次正向过程【个人推导】
根据上述信息,我们可以得到另一种表达一次迭代的“环形”过程的图示如下:
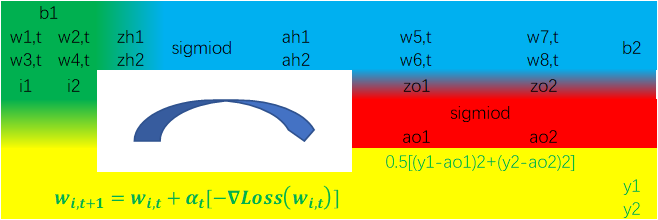
Fig 3 bp神经网络数量关系“环”图示
我们做一次正向过程(由于需多次迭代,因此我们将第一次正向过程标记为t=0),得各项数值如下:
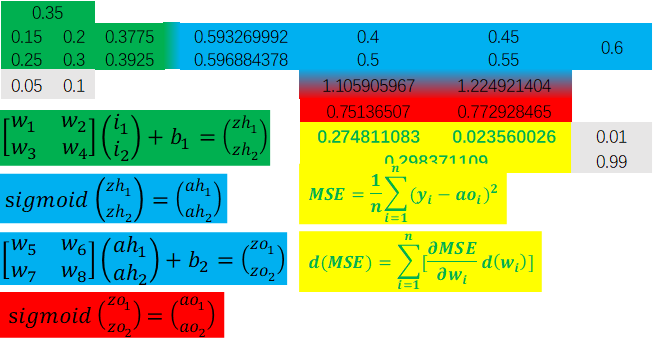
Fig 4 初始数值“环”图示(附函数关系表达式)
由此我们可得损失函数值为MSE=0.298371109,假设这超出了我们对损失值的要求,那么我们就需要对各个权重(wi,t=0)进行更新, 作为t=1的初始权重。
2.3 推导计算∂/∂wi【个人推导】
2.3.1 均值平方差损失函数的全微分推导
\(dMSE=\frac{\partial MSE}{\partial ao_{1}}dao_{1}+\frac{\partial MSE}{\partial ao_{2}}dao_{2}\)
\({\color{white}{dMSE}}=\frac{\partial MSE}{\partial ao_{1}}\frac{\partial ao_{1}}{\partial zo_{1}} dzo_{1}
+\frac{\partial MSE}{\partial ao_{2}}\frac{\partial ao_{2}}{\partial zo_{2}} dzo_{2}\)
\({\color{white}{dMSE}}=\frac{\partial MSE}{\partial ao_{1}}\frac{\partial ao_{1}}{\partial zo_{1}}\left ( \frac{\partial zo_{1}}{\partial ah_{1}}dah_{1}
+\frac{\partial zo_{1}}{\partial ah_{2}}dah_{2}
+
\frac{\partial zo_{1}}{\partial w\omega _{5}}d\omega _{5}
+\frac{\partial zo_{1}}{\partial w\omega _{6}}d\omega _{6}
\right )\)
\({\color{white}{dMSE=}}+\frac{\partial MSE}{\partial ao_{2}}\frac{\partial ao_{2}}{\partial zo_{2}}\left ( \frac{\partial zo_{2}}{\partial ah_{1}}dah_{1}
+\frac{\partial zo_{2}}{\partial ah_{2}}dah_{2}
+
\frac{\partial zo_{2}}{\partial w\omega _{7}}d\omega _{7}
+\frac{\partial zo_{2}}{\partial w\omega _{8}}d\omega _{8}
\right )\)
\({\color{white}{dMSE}}=\frac{\partial MSE}{\partial ao_{1}}\frac{\partial ao_{1}}{\partial zo_{1}}\left ( \frac{\partial zo_{1}}{\partial ah_{1}}\frac{\partial ah_{1}}{\partial zh_{1}}dzh_{1}
+\frac{\partial zo_{1}}{\partial ah_{2}}\frac{\partial ah_{2}}{\partial zh_{2}}dzh_{2}
+
\frac{\partial zo_{1}}{\partial w\omega _{5}}d\omega _{5}
+\frac{\partial zo_{1}}{\partial w\omega _{6}}d\omega _{6}
\right )\)
\({\color{white}{dMSE=}}+\frac{\partial MSE}{\partial ao_{2}}\frac{\partial ao_{2}}{\partial zo_{2}}\left ( \frac{\partial zo_{2}}{\partial ah_{1}}\frac{\partial ah_{1}}{\partial zh_{1}}dzh_{1}
+\frac{\partial zo_{2}}{\partial ah_{2}}\frac{\partial ah_{2}}{\partial zh_{2}}dzh_{2}
+
\frac{\partial zo_{2}}{\partial w\omega _{7}}d\omega _{7}
+\frac{\partial zo_{2}}{\partial w\omega _{8}}d\omega _{8}
\right )\)
\({\color{white}{dMSE}}=\frac{\partial MSE}{\partial ao_{1}}\frac{\partial ao_{1}}{\partial zo_{1}}\left [ \frac{\partial zo_{1}}{\partial ah_{1}}\frac{\partial ah_{1}}{\partial zh_{1}}\left ( \frac{\partial zh_{1}}{\partial \omega _{1}}d\omega _{1}+\frac{\partial zh_{1}}{\partial \omega _{2}}d\omega _{2} \right )
+\frac{\partial zo_{1}}{\partial ah_{2}}\frac{\partial ah_{2}}{\partial zh_{2}}\left ( \frac{\partial zh_{2}}{\partial \omega _{3}}d\omega _{3}+\frac{\partial zh_{2}}{\partial \omega _{4}}d\omega _{4} \right )
+
\frac{\partial zo_{1}}{\partial w\omega _{5}}d\omega _{5}
+\frac{\partial zo_{1}}{\partial w\omega _{6}}d\omega _{6}
\right ]\)
\({\color{white}{dMSE=}}+\frac{\partial MSE}{\partial ao_{2}}\frac{\partial ao_{2}}{\partial zo_{2}}\left [ \frac{\partial zo_{2}}{\partial ah_{1}}\frac{\partial ah_{1}}{\partial zh_{1}}\left ( \frac{\partial zh_{1}}{\partial \omega _{1}}d\omega _{1}+\frac{\partial zh_{1}}{\partial \omega _{2}}d\omega _{2} \right )
+\frac{\partial zo_{2}}{\partial ah_{2}}\frac{\partial ah_{2}}{\partial zh_{2}}\left ( \frac{\partial zh_{2}}{\partial \omega _{3}}d\omega _{3}+\frac{\partial zh_{2}}{\partial \omega _{4}}d\omega _{4} \right )
+
\frac{\partial zo_{2}}{\partial w\omega _{7}}d\omega _{7}
+\frac{\partial zo_{2}}{\partial w\omega _{8}}d\omega _{8}
\right ]\)
2.3.2 这一次代入训练实例的数值和各数量名
\(dMSE=\frac{\partial \frac{1}{2}\left ( y_{1}-ao_{1} \right )^2}{\partial ao_{1}}dao_{1}+\frac{\partial \frac{1}{2}\left ( y_{2}-ao_{2} \right )^2}{\partial ao_{2}}dao_{2}\)
\({\color{white}{dMSE}}=-\left( y_{1}-ao_{1} \right )\frac{\partial ao_{1}}{\partial zo_{1}}dzo_{1}-\left( y_{2}-ao_{2} \right )\frac{\partial ao_{2}}{\partial zo_{2}}dzo_{2}\)
\({\color{white}{dMSE}}=-\left( y_{1}-ao_{1} \right )ao_{1}\left( 1-ao_{1} \right )\left ( \frac{\partial zo_{1}}{\partial ah_{1}}dah_{1}+\frac{\partial zo_{1}}{\partial ah_{2}}dah_{2}+\frac{\partial zo_{1}}{\partial \omega _{5}}d\omega _{5}+\frac{\partial zo_{1}}{\partial \omega _{6}}d\omega _{6} \right )\)
\({\color{white}{dMSE=}}-\left( y_{2}-ao_{2} \right )ao_{2}\left( 1-ao_{2} \right )\left ( \frac{\partial zo_{2}}{\partial ah_{1}}dah_{1}+\frac{\partial zo_{2}}{\partial ah_{2}}dah_{2}+\frac{\partial zo_{2}}{\partial \omega _{7}}d\omega _{7}+\frac{\partial zo_{2}}{\partial \omega _{8}}d\omega _{8} \right )\)
\({\color{white}{dMSE}}=-\left( y_{1}-ao_{1} \right )ao_{1}\left( 1-ao_{1} \right )\left ( \omega_{5}\frac{\partial ah_{1}}{\partial zh_{1}}dzh_{1}+\omega_{6}\frac{\partial ah_{2}}{\partial zh_{2}}dzh_{2}+ah_{1}d\omega _{5}+ah_{2}d\omega _{6} \right )\)
\({\color{white}{dMSE=}}-\left( y_{2}-ao_{2} \right )ao_{2}\left( 1-ao_{2} \right )\left ( \omega_{7}\frac{\partial ah_{1}}{\partial zh_{1}}dzh_{1}+\omega_{8}\frac{\partial ah_{2}}{\partial zh_{2}}dzh_{2}+ah_{1}d\omega _{7}+ah_{2}d\omega _{8} \right )\)
\({\color{white}{dMSE}}=-\left ( y_{1}-ao_{1} \right )ao_{1}\left( 1-ao_{1} \right )\left [ \omega_{5}\cdot ah_{1}\left ( 1- ah_{1} \right )\left (\frac{\partial zh_{1}}{\partial \omega_{1}}\omega_{1}+\frac{\partial zh_{1}}{\partial \omega_{2}}\omega_{2} \right )
+\omega_{6}\cdot ah_{2}\left ( 1- ah_{2} \right )\left (\frac{\partial zh_{2}}{\partial \omega_{3}}\omega_{3}+\frac{\partial zh_{2}}{\partial \omega_{4}}\omega_{4} \right )+ah_{1}d\omega _{5}+ah_{2}d\omega _{6} \right ]\)
\({\color{white}{dMSE=}}-\left ( y_{2}-ao_{2} \right )ao_{2}\left( 1-ao_{2} \right )\left [ \omega_{7}\cdot ah_{1}\left ( 1- ah_{1} \right )\left (\frac{\partial zh_{1}}{\partial \omega_{1}}\omega_{1}+\frac{\partial zh_{1}}{\partial \omega_{2}}\omega_{2} \right )
+\omega_{8}\cdot ah_{2}\left ( 1- ah_{2} \right )\left (\frac{\partial zh_{2}}{\partial \omega_{3}}\omega_{3}+\frac{\partial zh_{2}}{\partial \omega_{4}}\omega_{4} \right )+ah_{1}d\omega _{7}+ah_{2}d\omega _{8} \right ]\)
\({\color{white}{dMSE}}=-\left ( y_{1}-ao_{1} \right )ao_{1}\left( 1-ao_{1} \right )\left[ \omega_{5} \cdot ah_{1}\left ( 1-ah_{1} \right )\left ( {\color{green}{i_{1}d\omega_{1}}}+{\color{green}{i_{2}d\omega_{2}}} \right )
+\omega_{6} \cdot ah_{2}\left ( 1-ah_{2} \right )\left ( {\color{green}{i_{1}d\omega_{3}}}+{\color{green}{i_{2}d\omega_{4}}} \right )
+{\color{blue}{ah_{1}d\omega_{5}}}+{\color{blue}{ah_{2}d\omega_{6}}}\right ]\)
\({\color{white}{dMSE=}}-\left ( y_{2}-ao_{2} \right )ao_{2}\left( 1-ao_{2} \right )\left[ \omega_{7} \cdot ah_{1}\left ( 1-ah_{1} \right )\left ( {\color{green}{i_{1}d\omega_{1}}}+{\color{green}{i_{2}d\omega_{2}}} \right )
+\omega_{8} \cdot ah_{2}\left ( 1-ah_{2} \right )\left ( {\color{green}{i_{1}d\omega_{3}}}+{\color{green}{i_{2}d\omega_{4}}} \right )
+{\color{blue}{ah_{1}d\omega_{7}}}+{\color{blue}{ah_{2}d\omega_{8}}}\right ]\)
2.3.3 由此我们得到∂/∂wi的表达式
\(\frac {\partial MSE}{\partial \omega_{1}}=-\left [ \left( y_{1}-ao_{1} \right )ao_{1}\left ( 1-ao_{1} \right )\cdot \omega_{5}\cdot ah_{1}\left ( 1-ah_{1} \right )+\left( y_{2}-ao_{2} \right )ao_{2}\left ( 1-ao_{2} \right )\cdot \omega_{7}\cdot ah_{1}\left ( 1-ah_{1} \right ) \right ]\cdot i_{1}\)
\(\frac {\partial MSE}{\partial \omega_{2}}=-\left [ \left( y_{1}-ao_{1} \right )ao_{1}\left ( 1-ao_{1} \right )\cdot \omega_{5}\cdot ah_{1}\left ( 1-ah_{1} \right )+\left( y_{2}-ao_{2} \right )ao_{2}\left ( 1-ao_{2} \right )\cdot \omega_{7}\cdot ah_{1}\left ( 1-ah_{1} \right ) \right ]\cdot i_{2}\)
\(\frac {\partial MSE}{\partial \omega_{3}}=-\left [ \left( y_{1}-ao_{1} \right )ao_{1}\left ( 1-ao_{1} \right )\cdot \omega_{6}\cdot ah_{2}\left ( 1-ah_{2} \right )+\left( y_{2}-ao_{2} \right )ao_{2}\left ( 1-ao_{2} \right )\cdot \omega_{8}\cdot ah_{2}\left ( 1-ah_{2} \right ) \right ]\cdot i_{1}\)
\(\frac {\partial MSE}{\partial \omega_{4}}=-\left [ \left( y_{1}-ao_{1} \right )ao_{1}\left ( 1-ao_{1} \right )\cdot \omega_{6}\cdot ah_{2}\left ( 1-ah_{2} \right )+\left( y_{2}-ao_{2} \right )ao_{2}\left ( 1-ao_{2} \right )\cdot \omega_{8}\cdot ah_{2}\left ( 1-ah_{2} \right ) \right ]\cdot i_{2}\)
\(\frac {\partial MSE}{\partial \omega_{5}}=-\left( y_{1}-ao_{1} \right )ao_{1}\left ( 1-ao_{1} \right )\cdot ah_{1}\)
\(\frac {\partial MSE}{\partial \omega_{6}}=-\left( y_{1}-ao_{1} \right )ao_{1}\left ( 1-ao_{1} \right )\cdot ah_{2}\)
\(\frac {\partial MSE}{\partial \omega_{7}}=-\left( y_{2}-ao_{2} \right )ao_{2}\left ( 1-ao_{2} \right )\cdot ah_{1}\)
\(\frac {\partial MSE}{\partial \omega_{8}}=-\left( y_{2}-ao_{2} \right )ao_{2}\left ( 1-ao_{2} \right )\cdot ah_{2}\)
当然如果你喜欢用矩阵表示也可以:
(P.S. Markdown编辑器承受不住如此“巨大”的矩阵算式而崩溃,我只好转成svg图片贴上了,见谅~)


2.4 根据∂/∂wi梯度下降法优化wi【个人推导】
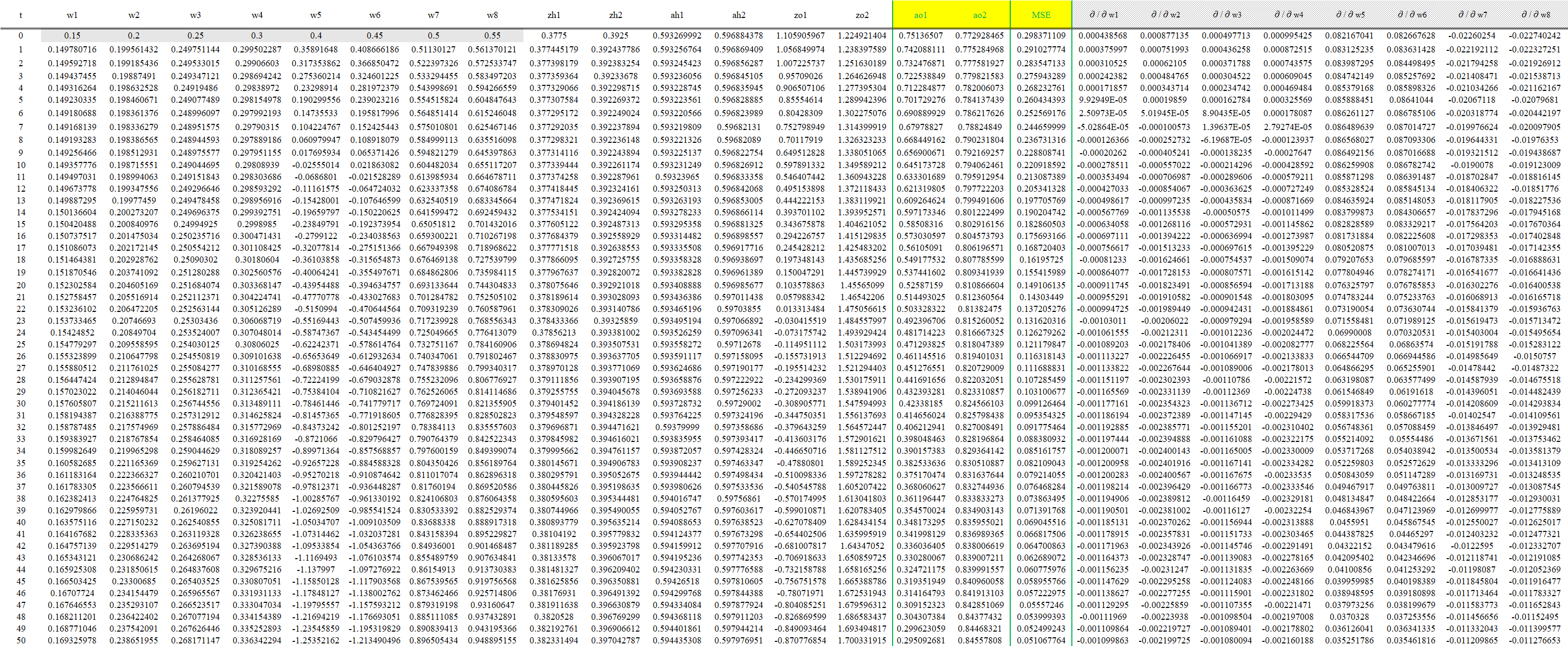
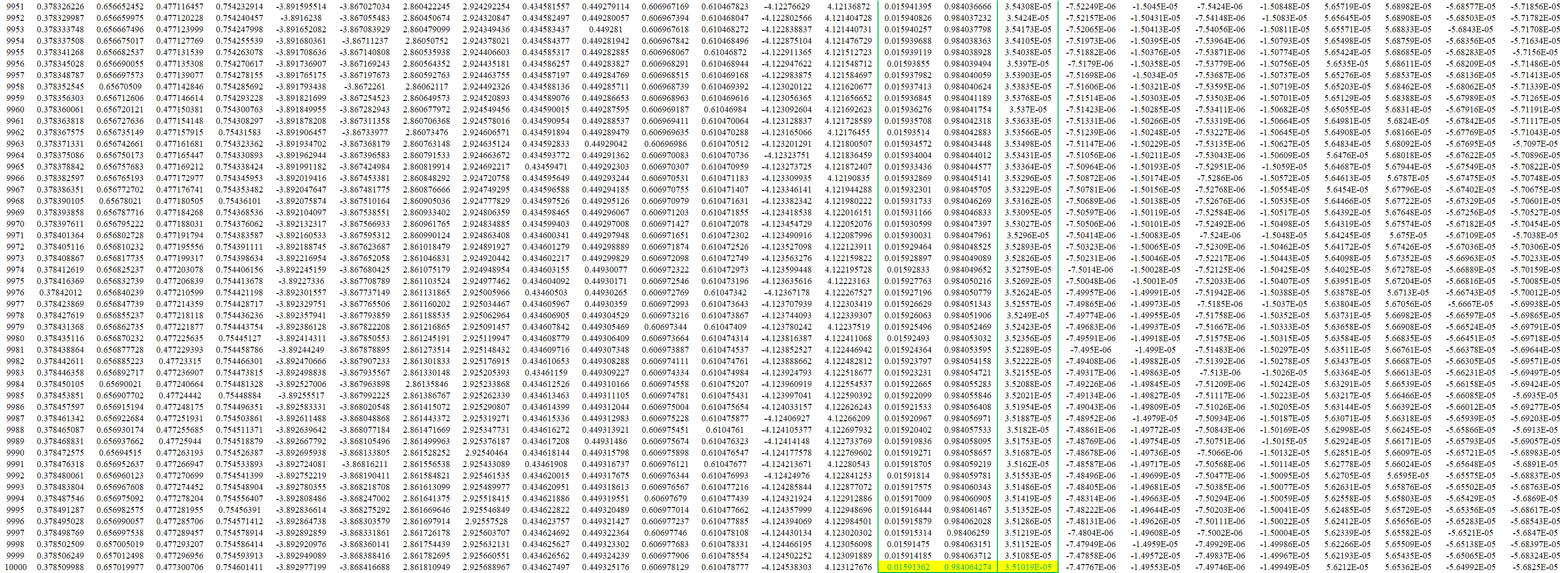
根据梯度下降法\({\color{purple}{\omega_{i,t+1}=\omega_{i,t}+\alpha_{t}\left [ -\triangledown Loss(\omega_{i,t}) \right ]}}\),设置学习率α=0.5,计算出wi,t+1,然后重新进行下一次正向过程。(可以将该过程在Excel中轻易实现,下表中为迭代数据截取)
可以看到,经过10001次迭代之后MSE(t=10001)=3.51019E-05已经足够小,可以停止迭代完成1代训练。
………………………………………………………………………………………………………………………………………………
sigmoid函数求导Tips(for于初级选手)
\(\because {\color{blue}{\frac{1}{1+e^{-x}}}}=\frac{1}{1+\frac{1}{e^{x}}}=\frac{e^{x}}{e^{x}+1}={\color{blue}{1-\frac{1}{1+e^{x}}}}\)
\(\therefore \frac{d\left( {\color{red}{\frac{1}{1+e^{-x}}}} \right )}{dx}=
d\left( 1-\frac{1}{e^{x}+1} \right )\frac{1}{dx}\)
\({\color{white}{\therefore \frac{d\left( \frac{1}{1+e^{-x}} \right )}{dx}}}=
(-1)\times (-1)(e^{x}+1)^{-2}d(e^{x}+1)\frac{1}{dx}\)
\({\color{white}{\therefore \frac{d\left( \frac{1}{1+e^{-x}} \right )}{dx}}}=
\frac{e^{x}}{(e^{x}+1)^2}\frac{1}{dx}=-\left[ \frac{1}{e^x+1}-\frac{1}{(e^x+1)^2} \right ]\frac{1}{dx}\)
\({\color{white}{\therefore \frac{d\left( \frac{1}{1+e^{-x}} \right )}{dx}}}=
\frac{1}{1+e^{x}}\left [ 1-\frac{1}{e^x+1} \right ]\frac{1}{dx}\)
\({\color{white}{\therefore \frac{d\left( \frac{1}{1+e^{-x}} \right )}{dx}}}=
\left ( {\color{red}{1-\frac{1}{1+e^{-x}}}} \right )\left [ {\color{red}{\frac{1}{1+e^x}}} \right ]\frac{1}{dx}\)
练习推导一个最简单的BP神经网络训练过程【个人作业/数学推导】的更多相关文章
- 模式识别之ocr项目---(模板匹配&BP神经网络训练)
摘 要 在MATLAB环境下利用USB摄像头采集字符图像,读取一帧保存为图像,然后对读取保存的字符图像,灰度化,二值化,在此基础上做倾斜矫正,对矫正的图像进行滤波平滑处理,然后对字符区域进行提取分割出 ...
- 字符识别OCR研究一(模板匹配&BP神经网络训练)
摘 要 在MATLAB环境下利用USB摄像头採集字符图像.读取一帧保存为图像.然后对读取保存的字符图像,灰度化.二值化,在此基础上做倾斜矫正.对矫正的图像进行滤波平滑处理,然后对字符区域进行提取切割出 ...
- 从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化
从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化 神经网络在训练过程中,为应对过拟合问题,可以采用正则化方法(regularization),一种常用的正则化方法是L2正则化. 神经网络中 ...
- 从MAP角度理解神经网络训练过程中的正则化
在前面的文章中,已经介绍了从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化,本次我们从最大后验概率点估计(MAP,maximum a posteriori point estimate)的 ...
- 简单单层bp神经网络
单层bp神经网络是解决线性可回归问题的. 该代码是论文:https://medium.com/technology-invention-and-more/how-to-build-a-simple-n ...
- 简单三层BP神经网络学习算法的推导
博客园不支持数学公式orz,我也很绝望啊!
- opencv BP神经网络使用过程
1.OpenCV中的神经网络 OpenCV中封装了类CvANN_MLP,因而神经网络利用很方便. 首先构建一个网络模型: CvANN_MLP ann; Mat structu ...
- 字符识别(模板匹配&BP神经网络训练)
http://blog.csdn.net/zhang11wu4/article/details/7585632
- 使用tensorflow下的GPU加速神经网络训练过程
下载CUDA8.0,安装 下载cuDNN v5.1安装.放置环境变量等. 其他版本就不装了.不用找其他版本的关系. 使用tensorflow-gpu1.0版本. 使用keras2.0版本. 有提示的. ...
随机推荐
- RHCSA 第八天
1.查询ip的几种方式: ip, ifconfig, nmcli,nmtui 2.nmcli命令使用: a.在ens160网卡上新建连接static_con,并配置静态ip b.在ens160网卡上新 ...
- 《剑指offer》面试题50. 第一个只出现一次的字符
问题描述 在字符串 s 中找出第一个只出现一次的字符.如果没有,返回一个单空格. 示例: s = "abaccdeff" 返回 "b" s = "&q ...
- 【记录一个问题】android opencl c++: 使用event.SetCallBack()方法后,在回调函数中要再使用event.wait()才能得到profile信息
如题:希望执行完成后得到各个阶段的执行时间,但是通过回调发现start, end, submit, queued等时间都是0 因此要在回调函数中再使用一次event.wait(),然后才能获得prof ...
- 带你学习Flood Fill算法与最短路模型
一.Flood Fill(连通块问题) 0.简介 Flood Fill(洪水覆盖) 可以在线性的时间复杂内,找到某个点所在的连通块! 注:基于宽搜的思想,深搜也可以做但可能会爆栈 flood fill ...
- Servlet虚拟路径匹配规则
当 Servlet 容器接收到请求后,容器会将请求的 URL 减去当前应用的上下文路径,使用剩余的字符串作为映射 URL 与 Servelt 虚拟路径进行匹配,匹配成功后将请求交给相应的 Servle ...
- springmvc请求处理过程
springmvc请求的处理流程 1)发起some.do 2)tomcat(web.xml-----url-pattern知道*.do的请求给DispatcherServlet) 3)Dispatch ...
- Filter的生命周期及FilterConfig类介绍
Filter的生命周期包含几个方法 1,构造器方法 2,init初始化方法 第1,2步,在web工程 3,doFilter过滤方法 每次拦截到请求,就会执行 4,destroy销毁方法 停止web工程 ...
- cp 不提示按y
yes|cp index.html.j2 yml -rf \cp index.html.j2 yml/ 两个效果是一样的
- 操作系统的发展史(并发与并行)<异步与同步>《进程与程序》[非堵塞与堵塞]
目录 一:一:手工操作 -- 穿孔卡片 1.简介 二:手工操作方式两个特点: 三:批处理 -- 磁带存储 1.联机批处理系统 2.脱机批处理系统 3.多道程序系统 4.多道批处理系统 四:总结发展史 ...
- mysql的innodb缓存使用率统计
show 方式去查看: show status like '%innodb_buffer_pool_pages%'; 计算方式: (total-free)/total * %100: sql方式查看: ...