Scrapy 框架 安装
Scrapy 框架
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy架构图(绿线是数据流向):
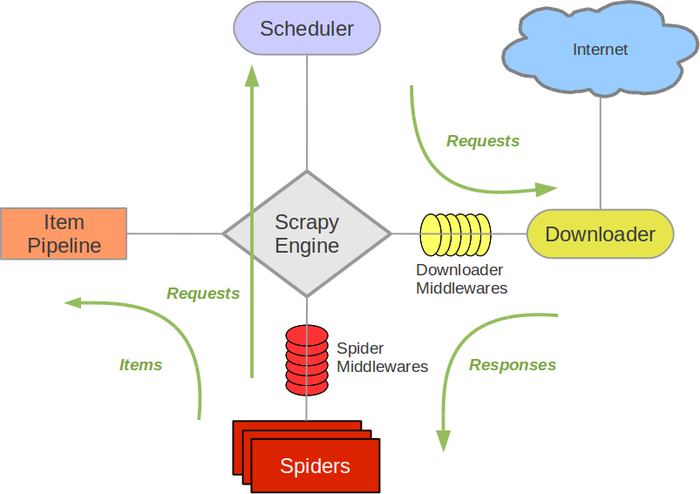
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
制作 Scrapy 爬虫
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy安装
一、Linux 的安装方式
pip install scrapy
二、Windows的安装
- 注册: python3 licence3.py 程序
- 下载符合系统版本的 pywin32 程序:https://sourceforge.net/projects/pywin32/files/ 或 pip3 install pywin32 直接安装
- pip3 install wheel
- 下载符合系统版本的twisted文件 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 进入文件所在目录:pip3 install Twisted-17.9.0-cp36-cp36m-win_amd64.whl
- pip3 install scrapy
注:安装后检查系统是否有 scraoy.ext 命令
Scrapy 框架 安装的更多相关文章
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架安装及使用
一.Windows安装 Twisted下载及安装 在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件 在命令行进入到Twist ...
- Scrapy框架——安装以及新建scrapy文件
一.安装 conda install Scrapy :之后在按y 表示允许安装相关的依赖库(下载速度慢的话也可以借助镜像源),安装的前提是安装了anaconda作为python , 测试scr ...
- Scrapy框架安装与使用(基于windows系统)
"人生苦短,我用python".最近了解到一个很好的Spider框架--Scrapy,自己就按着官方文档装了一下,出了些问题,在这里记录一下,免得忘记. Scrapy的安装是基于T ...
- python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中 2.安装pywin32 在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/p ...
- Scrapy框架安装失败解决办法
安装报错信息 正常安装: pip3 install scrapy 出现报错信息如下: 两种解决办法 第一种方法 最根本得解决办法 需要我们安装 Microsoft Visual C++ 14.0 ...
- 浅谈scrapy框架安装使用
Scrapy笔记: 一 安装: pip3 install wheel pip3 install lxml pip3 install pyopenssl pip3 install -i https:// ...
随机推荐
- NOIP2018 20天训练
Day 0 2018.10.20 其实写的时候已经是Day 1了--(凌晨两点) 终于停课了,爽啊 get树状数组+线段树(延迟标记) 洛谷:提高组所有nlogn模板+每日一道搜索题(基本的图的遍历题 ...
- (转载)深度剖析 | 可微分学习的自适配归一化 (Switchable Normalization)
深度剖析 | 可微分学习的自适配归一化 (Switchable Normalization) 作者:罗平.任家敏.彭章琳 编写:吴凌云.张瑞茂.邵文琪.王新江 转自:知乎.原论文参考arXiv:180 ...
- aiojobs
import asyncio import aiojobs async def coro(timeout): print(timeout) await asyncio.sleep(timeout) p ...
- ES6学习笔记四(类和对象)
{ // 构造函数和实例 class Parent{ constructor(name='mukewan'){ this.name=name; } } let v_parent=new Parent( ...
- 【转】浅析SkipList跳跃表原理及代码实现
SkipList在Leveldb以及lucence中都广为使用,是比较高效的数据结构.由于它的代码以及原理实现的简单性,更为人们所接受.首先看看SkipList的定义,为什么叫跳跃表? "S ...
- Linux中error while loading shared libraries错误解决办法
默认情况下,编译器只会使用/lib和/usr/lib这两个目录下的库文件,通常通过源码包进行安装时,如果不指定--prefix,会将库安装在/usr/local/lib目录下:当运行程序需要链接动态库 ...
- HDU contest808 ACM多校第7场 Problem - 1008: Traffic Network in Numazu
首先嘚瑟一下这场比赛的排名:59 (第一次看到这么多 √ emmmm) 好了进入正文QAQ ...这道题啊,思路很清晰啊. 首先你看到树上路径边权和,然后还带修改,不是显然可以想到 树剖+线段树 维护 ...
- python结合pyvmomi 监控esxi的磁盘等信息
1.安装python3.6.6 # 安装依赖,一定要安装,否则后面可能无法安装一些python插件 yum -y install zlib-devel bzip2-devel openssl-deve ...
- SSH localhost免密不成功 + 集群状态显示Configured Capacity: 0 (0 KB)
前一天运行hadoop一切安好,今天重新运行出现BUG.下面对遇到的bug.产生原因以及解决方法进行一下简单总结记录. [bug1]用ssh localhost免密登录时提示要输入密码. 原因分析:之 ...
- Ex 2_14 去掉数组中所有重复的元素..._第二次作业
首先利用归并排序算法对数组进行排序,时间复杂度为O(nlogn),接着再利用时间复杂度为O(n) 的去重复算法去掉数组中的重复元素.总的时间复杂度为O(nlogn). (这题应该用分支算法解决)以下为 ...