Scrapy 框架 安装
Scrapy 框架
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy架构图(绿线是数据流向):
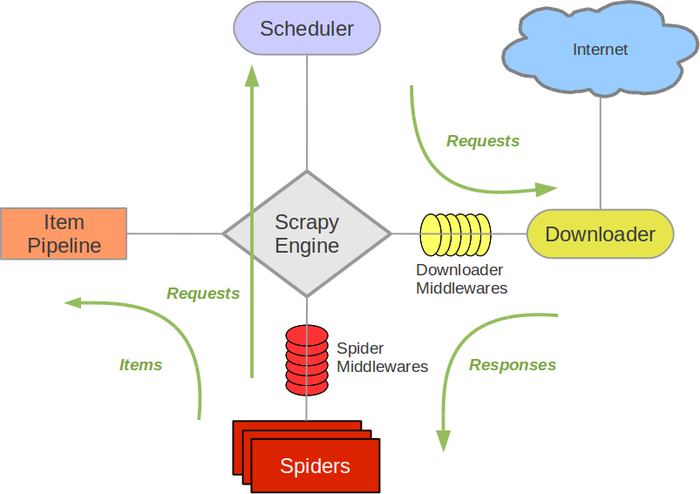
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
制作 Scrapy 爬虫
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy安装
一、Linux 的安装方式
pip install scrapy
二、Windows的安装
- 注册: python3 licence3.py 程序
- 下载符合系统版本的 pywin32 程序:https://sourceforge.net/projects/pywin32/files/ 或 pip3 install pywin32 直接安装
- pip3 install wheel
- 下载符合系统版本的twisted文件 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 进入文件所在目录:pip3 install Twisted-17.9.0-cp36-cp36m-win_amd64.whl
- pip3 install scrapy
注:安装后检查系统是否有 scraoy.ext 命令
Scrapy 框架 安装的更多相关文章
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架安装及使用
一.Windows安装 Twisted下载及安装 在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的Twisted的版本文件 在命令行进入到Twist ...
- Scrapy框架——安装以及新建scrapy文件
一.安装 conda install Scrapy :之后在按y 表示允许安装相关的依赖库(下载速度慢的话也可以借助镜像源),安装的前提是安装了anaconda作为python , 测试scr ...
- Scrapy框架安装与使用(基于windows系统)
"人生苦短,我用python".最近了解到一个很好的Spider框架--Scrapy,自己就按着官方文档装了一下,出了些问题,在这里记录一下,免得忘记. Scrapy的安装是基于T ...
- python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中 2.安装pywin32 在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/p ...
- Scrapy框架安装失败解决办法
安装报错信息 正常安装: pip3 install scrapy 出现报错信息如下: 两种解决办法 第一种方法 最根本得解决办法 需要我们安装 Microsoft Visual C++ 14.0 ...
- 浅谈scrapy框架安装使用
Scrapy笔记: 一 安装: pip3 install wheel pip3 install lxml pip3 install pyopenssl pip3 install -i https:// ...
随机推荐
- python3字典中items()和python2.x中iteritems()有什么不同?
在Python2.x中: items() 用于返回一个字典的拷贝列表[Returns a copy of the list of all items (key/value pairs) in D],占 ...
- TCP连接的TIME_WAIT和CLOSE_WAIT 状态解说【转】
相信很多运维工程师遇到过这样一个情形: 用户反馈网站访问巨慢, 网络延迟等问题, 然后就迫切地登录服务器,终端输入命令"netstat -anp | grep TIME_WAIT | wc ...
- Jetbrain系列软件配置文件同步
https://intellij-support.jetbrains.com/hc/en-us/articles/206544519-Directories-used-by-the-IDE-to-st ...
- 搭建Unity安卓开发环境
原文见 https://blog.csdn.net/chenggong2dm/article/details/20654075 tiny教程 https://docs.unity3d.com/Pack ...
- hibernate框架学习之数据查询(QBC)
lQBC(Query By Criteria)是一种Hibernate中使用面向对象的格式进行查询的计数 lQBC查询方式步骤 •获取Session对象 •初始化Criteria对象(使用Sessio ...
- ubuntu 16.04 修正网卡与ifname对应关系
一台工控机,含有6个网口,但是名称 enp3s0 等等与网口顺序对应不起来. 现在修改脚本 /etc/udev/rules.d/70-persistent-net.rules ,如果文件不存在,可以 ...
- Mac 系统重新安装的几种方法
转:https://blog.csdn.net/feibozhulang/article/details/43734109 苹果官网说明: https://support.apple.com/en-u ...
- 分析Vue框架源码心得
1.在封装一个公用组件,比如button按钮,我们多个地方使用,不同类型的button调用不同的方法,我们就可以这样用 代码片段: <lin-button v-for="(item,i ...
- Windows&Word 常用快捷键
Win:显示开始菜单 Win + E:打开文件管理器 Win + D:显示桌面 Win + L:锁定计算机 Win + I:打开设置 Win + M:最小化所有窗口 Alt + F4:1.用来关闭当前 ...
- Confluence 6 任务的类型
下面是有关你可以调整的计划任务列表. Confluence 备份(Back Up Confluence) 对 Confluence 站点执行备份操作. 每集群(Per cluster) At 2am ...