Python深度学习案例2--新闻分类(多分类问题)
本节构建一个网络,将路透社新闻划分为46个互斥的主题,也就是46分类
案例2:新闻分类(多分类问题)
1. 加载数据集
from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
将数据限定在10000个最常见出现的单词,8982个训练样本和2264个测试样本
len(train_data)
8982
len(test_data)
2246
train_data[10]
2. 将索引解码为新闻文本
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# Note that our indices were offset by 3
# because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
train_labels[10]
3. 编码数据
import numpy as np def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1
return results # 将训练数据向量化
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
# 将标签向量化,将标签转化为one-hot
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1
return results one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels) from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
4. 模型定义
from keras import models
from keras import layers model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
5. 编译模型
对于这个例子,最好的损失函数是categorical_crossentropy(分类交叉熵),它用于衡量两个概率分布之间的距离
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
6. 留出验证集
留出1000个样本作为验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
7. 训练模型
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size = 512, validation_data = (x_val, y_val))
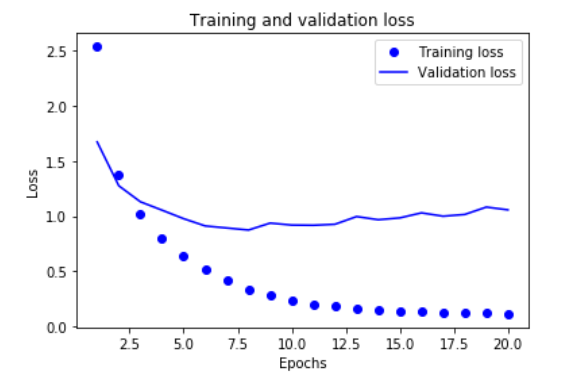
8. 绘制训练损失和验证损失
import matplotlib.pyplot as plt loss = history.history['loss']
val_loss = history.history['val_loss'] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend() plt.show()
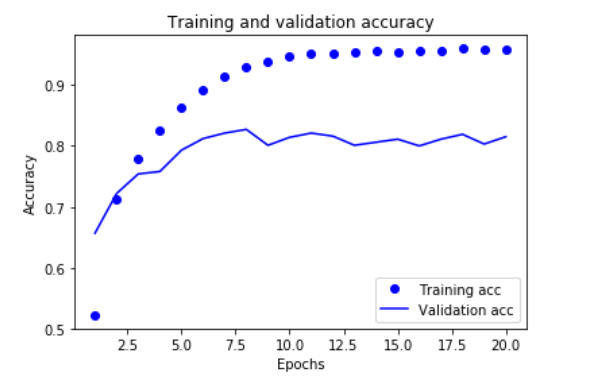
9. 绘制训练精度和验证精度
plt.clf() # 清除图像
acc = history.history['acc']
val_acc = history.history['val_acc'] plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend() plt.show()
10. 从头开始重新训练一个模型
中间层有64个隐藏神经元
# 从头开始训练一个新的模型
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=9, batch_size = 512, validation_data = (x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
results
[0.981157986054119, 0.790739091745149]
这种方法可以得到79%的精度
import copy test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
float(np.sum(np.array(test_labels) == np.array(test_labels_copy))) / len(test_labels)
0.19011576135351738 完全随机的精度约为19%
# 在新数据上生成预测结果
predictions = model.predict(x_test)
predictions[0].shape
np.sum(predictions[0])
np.argmax(predictions[0])
11. 处理标签和损失的另一种方法
y_train = np.array(train_labels)
y_test = np.array(test_labels)
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['acc'])
12. 中间层维度足够大的重要性
最终输出是46维的,本代码中间层只有4个隐藏单元,中间层的维度远远小于46
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=20, batch_size = 128, validation_data = (x_val, y_val))
Epoch 20/20
7982/7982 [==============================] - 2s 274us/step - loss: 0.4369 - acc: 0.8779 - val_loss: 1.7934 - val_acc: 0.7160
验证精度最大约为71%,比前面下降了8%。导致这一下降的主要原因在于,你试图将大量信息(这些信息足够回复46个类别的分割超平面)压缩到维度很小的中间空间
13. 实验
1. 中间层32个
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=20, batch_size = 128, validation_data = (x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
results
Epoch 20/20
7982/7982 [==============================] - 2s 231us/step - loss: 0.1128 - acc: 0.9564 - val_loss: 1.1904 - val_acc: 0.7970
2246/2246 [==============================] - 0s 157us/step
[1.4285533854925303, 0.7773820125196835]
精度大约在77%
1. 中间层128个
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=9, batch_size = 128, validation_data = (x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
results
Epoch 9/9
7982/7982 [==============================] - 2s 237us/step - loss: 0.1593 - acc: 0.9536 - val_loss: 1.0186 - val_acc: 0.8060
2246/2246 [==============================] - 0s 159us/step
[1.126946303426211, 0.790293855743544]
精度大约在79%
尝试了中间层128个,但是迭代20轮,准确率却只有77%,说明迭代次数过高,出现了过拟合。
Python深度学习案例2--新闻分类(多分类问题)的更多相关文章
- Python深度学习案例1--电影评论分类(二分类问题)
我觉得把课本上的案例先自己抄一遍,然后将书看一遍.最后再写一篇博客记录自己所学过程的感悟.虽然与课本有很多相似之处.但自己写一遍感悟会更深 电影评论分类(二分类问题) 本节使用的是IMDB数据集,使用 ...
- 参考分享《Python深度学习》高清中文版pdf+高清英文版pdf+源代码
学习深度学习时,我想<Python深度学习>应该是大多数机器学习爱好者必读的书.书最大的优点是框架性,能提供一个"整体视角",在脑中建立一个完整的地图,知道哪些常用哪些 ...
- 利用python深度学习算法来绘图
可以画画啊!可以画画啊!可以画画啊! 对,有趣的事情需要讲三遍. 事情是这样的,通过python的深度学习算法包去训练计算机模仿世界名画的风格,然后应用到另一幅画中,不多说直接上图! 这个是世界名画& ...
- 好书推荐计划:Keras之父作品《Python 深度学习》
大家好,我禅师的助理兼人工智能排版住手助手条子.可能非常多人都不知道我.由于我真的难得露面一次,天天给禅师做底层工作. wx_fmt=jpeg" alt="640? wx_fmt= ...
- UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络 1. 主要思路 本文要讨论的"UFLDL 建立分类用深度网络"基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使 ...
- 7大python 深度学习框架的描述及优缺点绍
Theano https://github.com/Theano/Theano 描述: Theano 是一个python库, 允许你定义, 优化并且有效地评估涉及到多维数组的数学表达式. 它与GPUs ...
- 基于python深度学习的apk风险预测脚本
基于python深度学习的apk风险预测脚本 为了有效判断安卓apk有无恶意操作,利用python脚本,通过解包apk文件,对其中xml文件进行特征提取,通过机器学习构建模型,预测位置的apk包是否有 ...
- 关于python深度学习网站
大数据文摘作品,转载要求见文末 编译团队|姚佳灵 裴迅 简介 ▼ 深度学习,是人工智能领域的一个突出的话题,被众人关注已经有相当长的一段时间了.它备受关注是因为在计算机视觉(Computer Vi ...
- Python深度学习 deep learning with Python
内容简介 本书由Keras之父.现任Google人工智能研究员的弗朗索瓦•肖莱(François Chollet)执笔,详尽介绍了用Python和Keras进行深度学习的探索实践,涉及计算机视觉.自然 ...
随机推荐
- python第七天,dict
在python里边创建字典的方法有如下几种: >>> dict1= dict(((),(),(),(),())) >>> print(dict1) {, , , , ...
- SpringSecurity基于数据库RBAC数据模型控制权限
⒈通用RBAC(Role - Based Access Control)数据模型 ⒉如何使用 1. package cn.coreqi.ssoserver.rbac; import org.sprin ...
- libevent学习笔记 一、基础知识【转】
转自:https://blog.csdn.net/majianfei1023/article/details/46485705 欢迎转载,转载请注明原文地址:http://blog.csdn.net/ ...
- VS2008中 ATL CLR MFC Win32 区别
ATL用于编写COM程序,CLR是.NET的公共语言运行库,MFC是指MFC类库,MFC程序是用这些类库做出的程序,WIN32常规就是不用MFC,使用API函数编的程序.MFC.ATL和CLR是VC2 ...
- ansible笔记(12):handlers的用法
ansible笔记():handlers的用法 这篇文章会介绍playbook中handlers的用法. 在开始介绍之前,我们先来描述一个工作场景: 当我们修改了某些程序的配置文件以后,有可能需要重启 ...
- matlab常用命令
clc; %清屏 clear; %清除变量 close all; %关闭 doc %查看文档 meshgrid%采样mesh %网格曲面surf %光滑曲面plot %ezplotdiff figur ...
- PHP导入导出csv文件 Summer-CSV
2017年11月9日09:25:56 根据项目实践总结的一个类文件, mac/win下没乱码 简体中文 默认从gb2312转到utf-8 https://gitee.com/myDcool/PHP-C ...
- PHP随机红包算法
2017年1月14日 14:19:14 星期六 一, 整体设计 算法有很多种, 可以自行选择, 主要的"架构" 是这样的, 用redis decr()命令去限流, 用mysql去记 ...
- ASP.NET如何下载大文件
关于此代码的几点说明: 1. 将数据分成较小的部分,然后将其移动到输出流以供下载,从而获取这些数据. 2. 根据下载的文件类型来指定 Response.ContentType .(参考OSChina的 ...
- Python split()
split翻译为分裂. split()就是将一个字符串分裂成多个字符串组成的列表. split()当不带参数时以空格进行分割,当代参数时,以该参数进行分割. //---当不带参数时 example: ...