【机器学习】主成分分析法 PCA (I)
主成分分析算法是最常见的降维算法,在PCA中,我们要做的是找到一个方向向量,然后我们把所有的数都投影到该向量上,使得投影的误差尽可能的小。投影误差就是特征向量到投影向量之间所需要移动的距离。
PCA的目的是找到一个最下投影误差平方的低维向量,对原有数据进行投影,从而达到降维的目的。
下面给出主成分分析算法的描述:
问题是要将n维数据降至k维,目标是找出向量μ(k),使得投影误差最小。
主成分分析算法与线性回归类似,但区别是投影方式的不同。
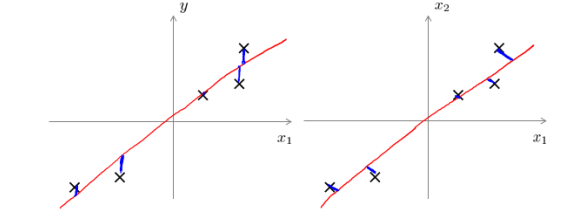
如图所示,的左边的图是垂直与x轴进行的投影,这是线性回归的误差,而右边的投影方法是垂直与回归直线进行投影。PCA将n个特征降维到k个,可以用来压缩数据,也可以用来使得数据可视化。‘
PCA技术最大的优点是对数据进行降维,在起到压缩数据的同时,最大程度的保持了原始数据。
而且它是完全无参数限制,在计算过程中,完全不需要人为的设定多余参数,对经验模型的计算进行干预。
如何通过PCA算法进行降维?
PCA算法减少n维到k维:
step 1: 均值归一化,我们需要计算出所有向量的均值,然后令x j = x j - μ j。如果特征是在不同的数量级上,我们还需要除以标准差δ 2.
step 2:计算协方差矩阵∑: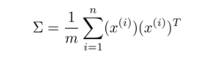
step 3:计算协方差矩阵的特征向量。
在octave(MATLAB)中 我们可以通过利用 ”奇异值分解“ 的方法来求解[U,S,V] = svd(sigma).
coeff = pca(X)
coeff = pca(X,Name,Value)
[coeff,score,latent] = pca(___)
[coeff,score,latent,tsquared] = pca(___)
[coeff,score,latent,tsquared,explained,mu] = pca(___)
coeff, ~, latent] = pca(X');
[~,i] = max(latent);
P = coeff(:,i);
Y = P'*X;
【机器学习】主成分分析法 PCA (I)的更多相关文章
- 【笔记】主成分分析法PCA的原理及计算
主成分分析法PCA的原理及计算 主成分分析法 主成分分析法(Principal Component Analysis),简称PCA,其是一种统计方法,是数据降维,简化数据集的一种常用的方法 它本身是一 ...
- 【机器学习】主成分分析法 PCA (II)
主成分分析法(PAC)的优化——选择主成分的数量 根据上一讲,我们知道协方差为① 而训练集的方差为②. 我们希望在方差尽可能小的情况下选择尽可能小的K值. 也就是说我们需要找到k值使得①/②的值尽可能 ...
- 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA)
主要内容: 一.降维与PCA 二.PCA算法过程 三.PCA之恢复 四.如何选取维数K 五.PCA的作用与适用场合 一.降维与PCA 1.所谓降维,就是将数据由原来的n个特征(feature)缩减为k ...
- 机器学习——主成分分析(PCA)
1 前言 PCA(Principal Component Analysis)是一种常用的无监督学习方法,是一种常用的数据分析方法. PCA 通过利用 正交变换 把由 线性相关变量 表示的观测数据转换为 ...
- 特征脸是怎么提取的之主成分分析法PCA
机器学习笔记 多项式回归这一篇中,我们讲到了如何构造新的特征,相当于对样本数据进行升维. 那么相应的,我们肯定有数据的降维.那么现在思考两个问题 为什么需要降维 为什么可以降维 第一个问题很好理解,假 ...
- 主成分分析法PCA原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 主成分分析法(PCA)答疑
问:为什么要去均值? 1.我认为归一化的表述并不太准确,按统计的一般说法,叫标准化.数据的标准化过程是减去均值并除以标准差.而归一化仅包含除以标准差的意思或者类似做法.2.做标准化的原因是:减去均值等 ...
- 降维之主成分分析法(PCA)
一.主成分分析法的思想 我们在研究某些问题时,需要处理带有很多变量的数据,比如研究房价的影响因素,需要考虑的变量有物价水平.土地价格.利率.就业率.城市化率等.变量和数据很多,但是可能存在噪音和冗余, ...
- 机器学习回顾篇(14):主成分分析法(PCA)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
随机推荐
- python大法好——操作mysql
python操作mysql数据库 Python 标准数据库接口为 Python DB-API,Python DB-API为开发人员提供了数据库应用编程接口. Python 数据库接口支持非常多的数据库 ...
- laravel框架memcached的使用
在laravel配置及使用使用 Memcached 缓存要求安装了Memcached PECL 包,即 PHP Memcached 扩展.你可以在配置文件 config/cache.php 中列出所有 ...
- Delphi中Chrome Chromium、Cef3学习笔记(四)
原文 http://blog.csdn.net/xtfnpgy/article/details/48155323 一.遍历网页元素并点击JS: 下面代码为找到淘宝宝贝页面,成交记录元素的代码: ...
- 聚类-31省市居民家庭消费水平-city
===分三类的===== ======分四类的======== 直接写文件名,那么你的那个txt文件应该是和py文件在同一个路径的 ============code=========== import ...
- cpanm Plack相关
1.curl -L https://cpanmin.us | perl - --sudo App::cpanminus 参考:https://metacpan.org/pod/App::cpanmin ...
- Hadoop学习笔记记录
NameNode的介绍: NameNode是HDFS的核心,也称为master,它仅存储元数据(文件系统中所有文件的目录树) NameNode不存储实际的数据或数据集,数据本身存储在DateNodes ...
- javascript中如何判断变量类型
typeof 只能判断基本类型,如number.string.boolean.当遇上引用类型变量就没那么好用了,结果都是object.使用Object.prototype.toString.call( ...
- ftp的主动模式和被动模式的配置和区别
原文链接: https://www.cnblogs.com/lnlvinso/p/8947369.html ftp模式分为主动模式(active mode)和被动模式(passive mode),ft ...
- 【练习】Python第一,二次
练习一 1,执行Python脚本的两种方式 a,Python解释器 b,Python 1.py 2,简述位和字节的关系 一个字节等于8位 3,简述ascii,unicode,utf-8,gbk的关系 ...
- FM(Factorization Machines)模型详解
优点 FM模型可以在非常稀疏的数据中进行合理的参数估计,而SVM做不到这点 在FM模型的复杂度是线性的,优化效果很好,而且不需要像SVM一样依赖于支持向量. FM是一个通用模型,它可以用于任何特征为实 ...