Python+Selenium 利用ID,XPath,tag name,link text,partial link text,class name,css,name定位元素
使用firefox浏览器,查看页面元素,我们以“百度网页”为示例
一、ID定位元素 利用find_element_by_id()方法来定位网页元素对象
①、定位百度首页,输入框的元素

②、编写示例代码信息如下:
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页
#利用ID定位元素
try:
driver.find_element_by_id("kw") #在①中可以查看定位到输入框的id为“kw”
print('test pass : ID found')
except Exception as e:
print("Exception found",format(e))
driver.quit()
③ 运行代码后,会打印出 “test pass : ID found”的成功信息
二、Xpath定位元素 利用find_element_by_xpath()方法来定位网页元素对象,示例中,①我们先定位搜索输入框元素②在输入框输入selenium③再定位搜索按钮(百度一下)④在搜索结果中定位都selenium官网相关元素
①如下三个截图是分别定位的输入框元素、搜索按钮元素、搜索结果中selenium官网元素的xpath
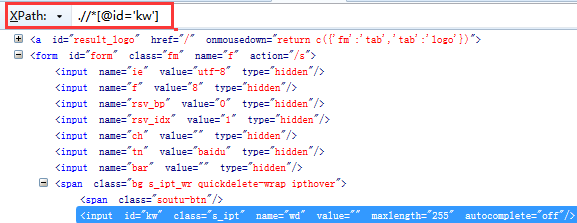
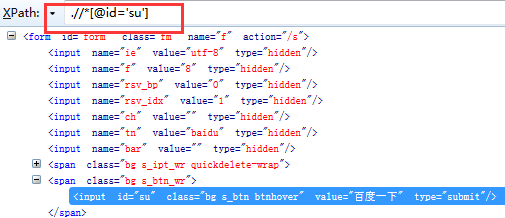
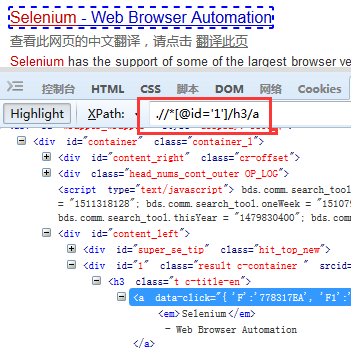
②编写示例代码信息如下:
#coding=utf-8
import time
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 #利用 xpath定位元素
driver.find_element_by_xpath(".//*[@id='kw']").send_keys("selenium") #定位搜索输入框,并在输入框输入selenium搜索信息
driver.find_element_by_xpath(".//*[@id='su']").click() #定位“百度一下”的搜索按钮,并点击
time.sleep(2)
#第一种断言方法
#这里通过元素xpath表达式来确定该元素显示在结果列表,从而判断Selenium官网这个连接显示在结果列表
#这里采用了相对元素定位方法/.../
#通过selenium方法is_displayed() 来判断我们的目标元素是否在页面显示
driver.find_element_by_xpath(".//*[@id='1']/h3/a").is_displayed()
#第二种判断方法
ele_string=driver.find_element_by_xpath(".//*[@id='1']/h3/a").text
if(ele_string==u"Selenium - Web Browser Automation"):
print("测试成功,结果和预期结果匹配")
driver.quit()
③上面代码运行后,会打印出“测试成功,结果和预期结果匹配”的成功信息
三、tag name 定位元素 利用 find_element_by_tag_name() 方法 来定位页面元素
①定位百度搜索输入框的tag name,如下截图

上面图片中红色圈选区域的标签名称都是tag name;实际上我们目标元素是输入框,应该是input这个tag name,在图中蓝色高亮区域。但是如果只是通过input这个tag name来定位,发现上面有很多input的选项。所以我们扩大节点的参照选择,我们选择上面这个form来作为我们tag name
②示例代码如下
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 #利用tag name定位元素
driver.find_element_by_tag_name("form")
print("test pass : tag name found")
driver.quit()
③代码运行后,打印“test pass : tag name found” 成功提示
四、link text 定位元素 利用find_element_by_link_text()方法 定位页面元素
①定位百度首页“新闻”这个文本字段来定义这个跳转链接元素

②示例代码如下:
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 #利用 link text定位元素
driver.find_element_by_link_text("新闻")
print("test pass ")
driver.quit()
运行代码成功,打印成功信息
五、partial link text定位元素,partial link text和link text有点类似,区别就是选择这个元素的link text中一部分字段, 利用find_element_by_partial_link_text()方法定义页面元素
①以下面截图中被选中的信息做目标元素

②示例代码如下:
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页
#利用partial link text 定位元素
driver.find_element_by_partial_link_text("设为主页").click()
print("test pass : Success")
time.sleep(10) #停留时间,是为了查看点击进入的页面,是否成功
driver.quit()
运行成功后,可以查看到进入的页面,和打印的成功信息
六、class name定位元素 ,利用find_element_by_class_name()方法来定义页面元素
①定义百度首页输入框元素,查看class如下截图

②示例代码如下:
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页
#利用class name定位元素
driver.find_element_by_class_name("s_ipt")
print("test pass :Success!!")
driver.quit()
运行代码后,打印成功信息
七、CSS 定位元素 利用find_element_by_css() 方法
示例代码如下:
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页
driver.find_element_by_css_selector("#su") # 找 百度一下 这个按钮
print ('test pass') driver.quit()
八、name定位 ,利用find_element_by_name()方法
①定位百度输入框元素的name

②示例代码如下:
#coding=utf-8
from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器
driver.maximize_window() #最大化浏览器窗口
driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页
driver.find_element_by_name("wd") # 这里百度搜索输入框有name = 'wd'这个节点信息
print ('test pass: element found by name value')
driver.quit()
运行代码后,打印出成功信息
Python+Selenium 利用ID,XPath,tag name,link text,partial link text,class name,css,name定位元素的更多相关文章
- Python selenium PO By.XPATH定位元素报错
Python selenium PO By.XPATH定位元素报错 如下代码经常报错: # 首页的“新建投放计划”按钮 new_ads_plan = (By.XPATH, "//*[tex ...
- python+selenium基础之XPATH定位(第一篇)
世界上最远的距离大概就是明明看到一个页面元素矗在那里,但是我却定位不到!! selenium定位元素的方法有很多种,像是通过id.name.class_name.tag_name.link_text等 ...
- python selenium ——— 动态id、class定位
什么样的是动态id呢? 动态id就是第一次点击显示的id与二次点击显示的不一样,一般是元素属性中包含一段数字的这种情况. 类似这种: 1 <input type="button&quo ...
- python+selenium基础之XPATH轴定位(第二篇)
第一篇讲了xpath定位的一些基本定位方法,这里再介绍一种:xpath轴定位,应用场景是当某个元素的各个属性及其组合都不足以定位时,那么可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位. 1. ...
- 1.python+selenium利用cookie,跳过验证码直接登录
方法1 在登录时,叫代码等待一段时间,然后手动输入验证码 # coding:utf-8 from selenium import webdriver import time url = 'http:/ ...
- python+selenium利用cookie记住密码
先上代码 1 from selenium import webdriver 2 from time import sleep 3 4 dr = webdriver.Chrome() 5 dr.get( ...
- python selenium right click on an href and choose Save link as... on Chrome.
From:https://stackoverflow.com/questions/42781483/right-click-on-an-href-and-choose-save-link-as-in- ...
- python selenium框架的Xpath定位元素
我们工作中经常用到的定位方式有八大种:id name class_name tag_name link_text partial_link_text xpath css_selector 本篇内容主要 ...
- python + selenium webdriver 从主窗口A跳转至主窗口B后,无法定位窗口B的元素的问题
在做登录脚本的时候,如果只是单纯从登录页面进行元素定位的话,并不存在这个问题 但实际情况是,从首页A进入到登录页面B(并非弹出框),这时候在页面B无法定位到该页面的元素 问题:从页面A进入页面B,无法 ...
随机推荐
- Spring 整合WebSocket, Error during WebSocket handshake: Unexpected response code: 302 还有200的错误
springboot 集成websocket 及其简单,,,但是管理端使用的是Spring,原生配置,发生这个错误,,,302 被重定向了...我起的是本地locallhost,把ip换成 local ...
- 关于Qrc文件的用法
在python文件xxx.py中调用资源文件,一般来说,需要将资源放在xxx.py的相同目录下:然而,当在xxx.py下建立一个统一目录/rec则需要建立xxx.qrc文件才能让xxx.py调用,调用 ...
- Mybatis级联:关联、集合和鉴别器的使用
Mybatis中级联有关联(association).集合(collection).鉴别器(discriminator)三种.其中,association对应一对一关系.collection对应一对多 ...
- Linux命令:pushd
语法 pushd [-n] [+N | -N | dir] 更改新目录并(或)压栈,或者把栈里的某个目录推到栈顶. 说明 pushd dir # 切换到目标目录dir,并将dir压栈. pushd # ...
- dbForge Studio for MySQL 中文乱码问题
设置一下编码格式就好了 第一步:右键点击连接的数据库,选择第二个 第二步:选择第二个选项卡,设置编码格式,点击OK 第三步:确认保存并从新连接 最后你就发现能正常显示中文啦
- Your branch and remoteBranchName have diverged solution
(zhuan)git pull时解决分支分叉(branch diverged)问题 git pull时出现分支冲突(branch diverged) $ git status # On branch ...
- Echars 地图属性详解
1.引入echarts库文件 <script charset="utf-8" type="text/javascript" language=" ...
- 第一周pta作业1总结
查找整数 本题要求从输入的N个整数中查找给定的X.如果找到,输出X的位置(从0开始数):如果没有找到,输出"Not Found". 输入格式: 输入在第一行中给出两个正整数N(≤2 ...
- asp.net mvc 使用NPOI插件导出excel
/// <summary> /// 交易账单 导出交易列表 /// </summary> /// <returns></returns> public ...
- 初步了解Spring
1.了解“控制反转” 控制反转也称为依赖注入,是面向对象编程中的一种设计理念,用来降低程序代码之间的耦合度. 下面是一个最简单的打印机实例 纸张接口,纸张有大小 继承它的有两个类,两种纸张大小的类 A ...