Java 字符编码(三)Reader 中的编解码
Java 字符编码(三)Reader 中的编解码
我们知道 BufferedReader 可以将字节流转化为字符流,那它是如何编解码的呢?
try (BufferedReader reader = new BufferedReader(new FileReader(...));) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
}
一、Reader
1.1 Reader
Reader 中有四个重载的 read 方法:
// 读到 CharBuffer 中
public int read(java.nio.CharBuffer target) throws IOException {
int len = target.remaining();
char[] cbuf = new char[len];
int n = read(cbuf, 0, len);
if (n > 0)
target.put(cbuf, 0, n);
return n;
}
// 读一个字符
public int read() throws IOException {
char cb[] = new char[1];
if (read(cb, 0, 1) == -1)
return -1;
else
return cb[0];
}
// 读多个字符
public int read(char cbuf[]) throws IOException {
return read(cbuf, 0, cbuf.length);
}
// 由子类实现
public abstract int read(char cbuf[], int off, int len) throws IOException;
1.2 Reader 类图
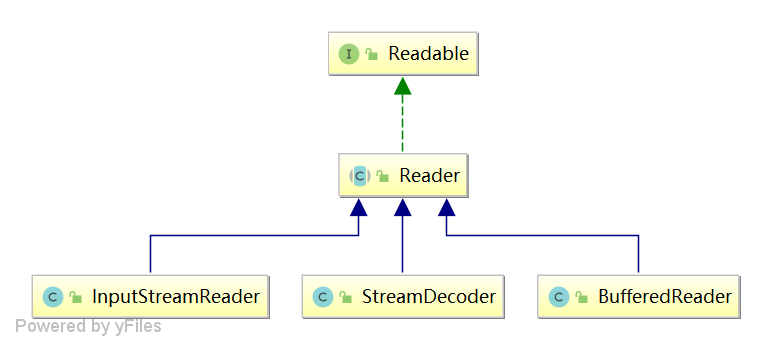
BufferedReader -> InputStreamReader -> StreamDecoder -> InputStream。真正处理编解码的是 StreamDecoder 类。
二、StreamDecoder
《StreamDecoder流源码》:https://blog.csdn.net/ai_bao_zi/article/details/81205286
2.1 read()方法
返回读取的一个字符,当读到文件末尾时返回 -1。
public int read() throws IOException {
return read0();
}
// read0 每次会读取 2 个字符,但 read0 只会返回一个字符
// 因此会将多读的另一个字符先存储在 leftoverChar 中
private int read0() throws IOException {
synchronized (lock) {
// 1. 如果上次读的两个字符还剩下的一个未返回,直接返回即可
if (haveLeftoverChar) {
haveLeftoverChar = false;
return leftoverChar;
}
// 2. 每次读取两个字符,返回第一个字符,另一个存储在 leftoverChar 中
char cb[] = new char[2];
int n = read(cb, 0, 2);
switch (n) {
// 2.1 文件流已读完,直接返回
case -1:
return -1;
// 2.2 如果读取到 2 个字符,则返回第一个,缓存第二个
case 2:
leftoverChar = cb[1];
haveLeftoverChar = true;
// FALL THROUGH
case 1:
return cb[0];
default:
assert false : n;
return -1;
}
}
}
read0 方法每次读 2 个字符,为什么不是 1 个或者多个?首先多个可以使用 read(char cbuf[], int offset, int length) 方法,其次当实际要读取的字符为 len=1 时会直接调用 read0 方法,即回调 read(cb[], 0, 2)。
2.2 read(char cbuf[], int offset, int length)方法
该方法最多读取 length 个字节放入字符数组中,从字符数组的偏移量 offset 开始存储,返回实际读取存储的字节数,当读取到文件末尾时,返回 -1。
public int read(char cbuf[], int offset, int length) throws IOException {
int off = offset;
int len = length;
synchronized (lock) {
ensureOpen();
if ((off < 0) || (off > cbuf.length) || (len < 0) ||
((off + len) > cbuf.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
}
if (len == 0)
return 0;
int n = 0;
// 1. 首先取出 leftoverChar
if (haveLeftoverChar) {
// Copy the leftover char into the buffer
cbuf[off] = leftoverChar;
off++; len--;
haveLeftoverChar = false;
n = 1;
if ((len == 0) || !implReady())
// Return now if this is all we can produce w/o blocking
return n;
}
// 2. 只读取一个则直接调用 read0 方法,即回调 read(cb[], 0, 2),如果 read0 的 length=1 会循环递归
// 这时 length=2 不会进入 if 分支,直接调用 implRead 方法
if (len == 1) {
// Treat single-character array reads just like read()
int c = read0();
if (c == -1)
return (n == 0) ? -1 : n;
cbuf[off] = (char)c;
return n + 1;
}
// 3. implRead 真正用于读取字节流到字符流 cbuf 中,返回实际读取的字符数
return n + implRead(cbuf, off, off + len);
}
}
2.3 implRead(cbuf, off, end)
读取字符到数组中,从数组的偏移量 offset 开始存储,最多存储到偏移量 end,返回实际读取存储的字符个数。
int implRead(char[] cbuf, int off, int end) throws IOException {
// 1. 每次最少读取 2 个字符
assert (end - off > 1);
//2. 将字符数组包装到缓冲区中,缓冲区修改,字符数组也会被修改
// cb 本质理解为一个数组,当前位置为 off,界限为 end-off
CharBuffer cb = CharBuffer.wrap(cbuf, off, end - off);
if (cb.position() != 0)
// Ensure that cb[0] == cbuf[off]
// slice 不会修改 cbuf 字符数组,只修改了 cb 指针位置,即忽略了 cubf[] 中已经有的字符
cb = cb.slice();
// 3. 将 readBytes 读到缓冲区 bb 中的字节解码到 cb 中
boolean eof = false;
for (;;) {
// 3.1 将字节缓冲区 bb 中解码到字符缓冲区 cb 中
CoderResult cr = decoder.decode(bb, cb, eof);
// 3.2 解码成功
if (cr.isUnderflow()) {
// 流中数据读取完毕或 cb 没有空间了就直接返回
if (eof)
break;
if (!cb.hasRemaining())
break;
// 如果流不能读取而 cb 已经有部分解码成功就直接返回,否则调用 readBytes 等待流的读取
if ((cb.position() > 0) && !inReady())
break; // Block at most once
// 从流中读取数据到 bb 中,如果 n<0 则数据读取完毕,但 bb 中还有数据的话会尽量再进行一次解码
int n = readBytes();
if (n < 0) {
eof = true;
if ((cb.position() == 0) && (!bb.hasRemaining()))
break;
decoder.reset();
}
continue;
}
// 3.3 cb 中没有空间了,返回由上层扩容处理
if (cr.isOverflow()) {
assert cb.position() > 0;
break;
}
// 3.4 解码异常
cr.throwException();
}
// 4. 清空 decoder 状态
if (eof) {
// ## Need to flush decoder
decoder.reset();
}
// 4. 返回读取的字节数
if (cb.position() == 0) {
if (eof)
return -1;
assert false;
}
return cb.position();
}
implRead 调用结束的的条件:一是流读取完毕;二是 cb 没有空间了,也就是达到了要读取的字符数。否则就会调用 readBytes 将数据中流读到 bb 中一直进行解码。
2.4 readBytes()
利用字节输入流尝试读取最多 8192 个字节到字节缓冲区中,此方法是核心点:读取字节到字节缓冲区才可以利用编码器编码字节成字符。
readBytes 方法真正与底层的流打交道,与之相关的属性如下:
// cs、decoder 字符集
private Charset cs;
private CharsetDecoder decoder;
// 从字节流中读取出的缓冲区,用于解码
private ByteBuffer bb;
// 可能为 bio 也可能为 nio,有且仅有一个字段不为空,只能选一个
private InputStream in;
private ReadableByteChannel ch;
private int readBytes() throws IOException {
// compact 丢弃了 position 之前的字节,这些字节已经解码完毕,可以丢弃
bb.compact();
try {
// 从 nio 中读取
if (ch != null) {
// Read from the channel
int n = ch.read(bb);
if (n < 0)
return n;
} else {
// 从 bio 中读取
int lim = bb.limit();
int pos = bb.position();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
assert rem > 0;
int n = in.read(bb.array(), bb.arrayOffset() + pos, rem);
if (n < 0)
return n;
if (n == 0)
throw new IOException("Underlying input stream returned zero bytes");
assert (n <= rem) : "n = " + n + ", rem = " + rem;
bb.position(pos + n);
}
} finally {
// Flip even when an IOException is thrown,
// otherwise the stream will stutter
bb.flip();
}
// 返回可以使用的字节数
int rem = bb.remaining();
assert (rem != 0) : rem;
return rem;
}
2.5 StreamDecoder 是如何保证数据流中的每一个字节都按顺序解码的呢?
以 sun.nio.cs.UTF_8 为例,这个类继承了 Charset,有两个内部类 Decoder 和 Encoder。每次解码完成后才会更新 Buffer 对应的字节,UTF_8#updatePositions 代码如下:
// 初始值: sp = src.arrayOffset() + src.position(); 每读处理一个字节 sp 都会递增
// 更新 src 和 dst 的实际 position 值
private static final void updatePositions(Buffer src, int sp,
Buffer dst, int dp) {
src.position(sp - src.arrayOffset());
dst.position(dp - dst.arrayOffset());
}
而每次重新读取数据前 StreamDecoder#readBytes 都会丢弃之前已经处理好的字节,这样就不会重复解码:
private int readBytes() throws IOException {
// compact 丢弃了 position 之前的字节,这些字节已经解码完毕,可以丢弃
bb.compact();
...
}
这样 StreamDecoder#readBytes 每次读取数据前调用 Buffer#compact 压缩 position 之前的数据,而 UTF_8#decodeLoop 解码完成后都会调用 UTF_8#updatePositions 更新字节码的 position 位置。
public ByteBuffer compact() {
// ix = offset + position()
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark();
return this;
}
每天用心记录一点点。内容也许不重要,但习惯很重要!
Java 字符编码(三)Reader 中的编解码的更多相关文章
- JAVA字符编码三:Java应用中的编码问题
第三篇:JAVA字符编码系列三:Java应用中的编码问题 这部分采用重用机制,引用一篇文章来完整本部分目标. 来源: Eceel东西在线 问题研究--字符集编码 地址:http://china.e ...
- Java 字符编码(二)Java 中的编解码
Java 字符编码(二)Java 中的编解码 java.nio.charset 包中提供了一套处理字符编码的工具类,主要有 Charset.CharsetDecoder.CharsetEncoder. ...
- 【JAVA编码专题】 JAVA字符编码系列三:Java应用中的编码问题
这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记录下来以便日后参考. 为了构成一个完整的对文字编码的认识和深入把握,以便处理在Java开发过程中遇到的各种问 ...
- java字符编码(转)
转载:http://blog.csdn.net/peach99999/article/details/7231247 深入讨论java乱码问题 几种常见的编码格式 为什么要编码 不知道大家有没有想过一 ...
- Java 字符编码归纳总结
String newStr = new String(oldStr.getBytes(), "UTF-8"); java中的String类是按照unicode进行编码的 ...
- 【JAVA编码专题】JAVA字符编码系列一:Unicode,GBK,GB2312,UTF-8概念基础
这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记录下来以便日后参考. 为了构成一个完整的对文字编码的认识和深入把握,以便处理在Java开发过程中遇到的各种问 ...
- Java 字符编码(一)Unicode 字符编码
Java 字符编码(一)Unicode 字符编码 Unicode(http://www.unicode.org/versions/#TUS_Latest_Version) 是一个编码方案,说白了希望给 ...
- JAVA字符编码一:Unicode,GBK,GB2312,UTF-8概念基础
第一篇:JAVA字符编码系列一:Unicode,GBK,GB2312,UTF-8概念基础 来源:holen'blog 对字符编码与Unicode,ISO 10646,UCS,UTF8,UTF16, ...
- java字符编码-Unicode编码问题刨根究底
博客搬家: java字符编码问题 前段时间在读<java核心技术卷一>,遇到一些名词:码点.代码单元等,其实字面意思不难理解,解释如下 码点(code point):Unicode编码表中 ...
随机推荐
- all-document
1.memorymanagement-whitepaper J2SE5.0 JVM 垃圾回收器相关英文 链接: https://pan.baidu.com/s/1mzkMxuFE82sfeVOToMb ...
- abc
无类型: 汇编弱类型.静态类型 : C/C++弱类型.动态类型检查: Perl/PHP强类型.静态类型检查 :Java/C#强类型.动态类型检查 :Python, Scheme静态显式类型 :Java ...
- Python paramiko模块基本使用(一)
使用paramiko模块登录远程主机,对日志进行统计分析. import paramiko def batch_count(days, hours, ips, user, passwd, source ...
- SnowFlake学习
分布式系统中生成全局唯一且趋势递增ID UUID - 太长,无序,数据库插入分裂性能不行 利用数据库自增序列,等步长生成 - 依赖数据库 SnowFlake:使用见下图 抄代码 https://www ...
- python开发之路:python数据类型(老王版)
python开发之路:python数据类型 你辞职当了某类似微博的社交网站的底层python开发主管,官还算高. 一次老板让你编写一个登陆的程序.咔嚓,编出来了.执行一看,我的妈,报错? 这次你又让媳 ...
- NPOI 修改已存在的excel文件,设置第一行行高
FileStream fileStream = new FileStream(@FileName, FileMode.Open, FileAccess.Read); FileStream fileSt ...
- Golang源码探索(二) 协程的实现原理(转)
Golang最大的特色可以说是协程(goroutine)了, 协程让本来很复杂的异步编程变得简单, 让程序员不再需要面对回调地狱,虽然现在引入了协程的语言越来越多, 但go中的协程仍然是实现的是最彻底 ...
- Idea安装lombok插件【转载】
参照:http://www.cnblogs.com/holten/p/5729226.html https://yq.aliyun.com/articles/59972 lombok是一个可以通过简单 ...
- centos7 根分区扩容
系统安装时候使用的默认分区,根分区只分了50G,使用的是LVM 想把home分区分出来660G给根分区 先查了点资料开搞 由于xfs分区只支持增大,不支持缩小,所以home目前是xfs格式无法进行缩小 ...
- CSS 文字太多用省略号表示
width:150px;/*要显示文字的宽度*/ overflow:hidden; /*超出的部分隐藏起来.*/ white-space:nowrap;/*不显示的地方用省略号...代替*/ text ...