python文件流
打开文件
文件的基本方法
迭代文件内容
打开文件
打开文件,可以使用自动导入的模块io中的函数open。函数open将文件名作为唯一必不可少的参数,并返回一个文件对象。如果只指定一个文件名,则获得一个可读取的文件对象。
如果当前目录中有此文件则可以打开,如果位于其他位置则需要指定完整的路径,如果指定文件不存在,则如下报错。

文件模式
如果需要写入文件,则需要通过指定模式。函数open的参数模式常见有如下:
|
模式 |
描述 |
|
'r' |
读取模式(默认) |
|
'w' |
写入模式(文件不存在时创建它) |
|
't' |
文本模式(默认,与其他模式结合使用) |
|
'x' |
独占写模式,新建一个文件,如果该文件已存在则会报错。 |
|
'a' |
附加模式(在既有文件末尾继续写入) |
|
'b' |
二进制模式(与其他模式结合使用) |
|
'+' |
打开一个文件进行更新(可读可写,与其他模式结合使用) |
默认模式为'rt',读取时将自动替换其他行尾字符('\r','\r\n'),写入时将'\n'替换为系统的默认行尾字符(os.linesep)
要打开一个文本文件进行读写,可使用'r+',但是会将既有内容删除,而'w+'不会。
文件的基本方法
读取和写入
管道重定向输出
随机存取
读取和写入行
关闭文件
文件最重要的功能就是提供和接收数据。在文本和二进制模式下,基本上分别将str和bytes类用作数据。
读取和写入:
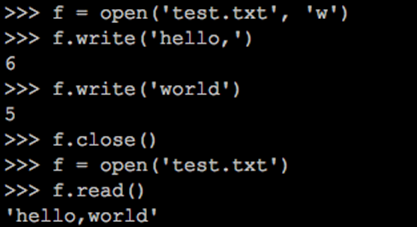
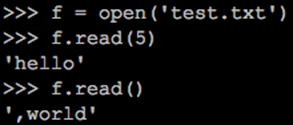
使用read读取数据,默认读取全部内容。还可以指定参数,然后读取剩下的全部内容:
管道重定向输出
将一个命令的标准输出链接到下个命令的标准输入:
#cat some.txt you are bad boy #cat some.py #!/usr/bin/evn python3 # 计算sys.stdin中包含多少个单词的脚本 import sys text = sys.stdin.read() words = text.split() wordcount = len(words) print(wordcount) #cat some.txt | python3 some.py 4
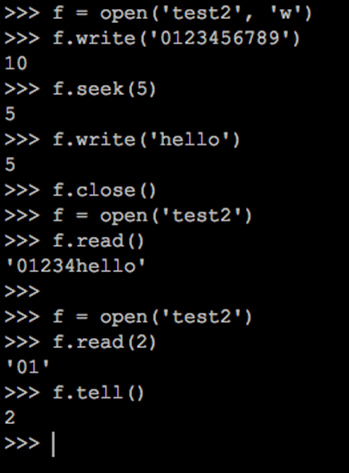
随机存取
可以使用方法seek和tell。
seek(offset,[, whence])将当前位置移到offset(指定字节数)和whence指定的地方(参数whence默认为io.SEEK_SET(0),偏移量是相对于文件开头的,而io.SEEK_SET(1),相对于当前位置进行移动,io.SEEK_SET(2),相对于文件末尾进行移动)
tell()返回当前位于文件的什么位置。
对行的读取和写入
可以使用方法readline,不指定参数默认读取一行并返回,指定参数为最多读取多少个字符。要读取文件中所有的行,并以列表的方式返回它们,可以使用方法readlines。方法writelines接受一个字符串列表写入文件中。


# 修改文件

关闭文件
避免锁定文件以防止修改,避免用完系统可能指定的文件打开配额。
确保文件关闭,可以使用try/finally语句。
try:
# 将数据写入到文件中
finally:
file.close()
# with语句可以让你打开一个文件并赋值到一个变量,到达该句末尾时,将自动关闭文件,即便出现异常。
with open('somefile.txt') as somefile
do_something(somefile)
迭代文件内容
def process(string):
print('Processing:', string) # 每次迭代一个字符
with open('fileone.txt') as f:
while True:
char = f.read(1)
if not char: break
process(char) #每次迭代一行字符
with open('fileone.txt') as f:
while True:
line = f.readline()
process(line) #读取所有内容,使用read
with open('fileone.txt') as f: for char in f.read():
process(char) #使用readlines
with open('fileone.txt') as f: for char in f.readlines():
process(char) # 使用fileinput实现延迟迭代,读取实际需要文本的部分
import fileinput
for line in fileinput.input('fileone.txt'):
process(line)
文件迭代器
迭代文件
with open('fileone.txt') as f:
for line in f:
process(line)
不将文件对象赋给变量迭代文件
for line in open(fileone.txt):
process(line)
对迭代器的操作也可以对文件做,如list(open(fileone.txt)):
>>> f = open('fileone.txt', 'w')
>>> print('First', 'line', file=f)
>>> print('Second', 'line', file=f)
>>> f.close()
>>> lines = list(open('fileone.txt'))
>>> lines
['First line\n', 'Second line\n']
python文件流的更多相关文章
- with open为什么会自动关闭文件流
操作文件我们通常需要手动关闭文件流,可是通过with open()的时候却可以自动关闭,这是为什么呢?其实这就是上下文管理器.我们来看一个例子 #!/usr/bin/env python # -*- ...
- 4、Python文件对象及os、os.path和pickle模块(0530)
文件系统和文件 1.文件系统是OS用于明确磁盘或分区上的文件的方法和数据结构---即在磁盘上组织文件的方法: 文件系统模块:os 2.计算机文件(称文件.电脑档案.档案),是存储在某种长期储存设备或临 ...
- python 文件 IO 操作
Python 的底层操作 * 其实Python的文件IO操作方法,和Linux底层的差不多 打开 f = open(filename , "r") 后面的 "r" ...
- python 文件读写操作(24)
以前的代码都是直接将数据输出到控制台,实际上我们也可以通过读/写文件的方式读取/输出到磁盘文件中,文件读写简称I/O操作.文件I/O操作一共分为四部分:打开(open)/读取(read)/写入(wri ...
- python文件的读写总结
读写文件是最常见的IO操作.Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘, ...
- Java 基础(四)| IO 流之使用文件流的正确姿势
为跳槽面试做准备,今天开始进入 Java 基础的复习.希望基础不好的同学看完这篇文章,能掌握泛型,而基础好的同学权当复习,希望看完这篇文章能够起一点你的青涩记忆. 一.什么是 IO 流? 想象一个场景 ...
- Python 简明教程 --- 24,Python 文件读写
微信公众号:码农充电站pro 个人主页:https://codeshellme.github.io 过去的代码都是未经测试的代码. 目录 无论是哪种编程语言,IO 操作都是非常重要的部分.I 即Inp ...
- 第九章 Python文件操作
前一阵子写类相关的内容,把老猿写得心都累了,本来准备继续介绍一些类相关的知识的,如闭包.装饰器.描述符.枚举类.异常等,现在实在不想继续,以后再开章节吧.本章弄点开胃的小菜提提神,介绍Python中文 ...
- C++基于文件流和armadillo读取mnist
发现网上大把都是用python读取mnist的,用C++大都是用opencv读取的,但我不怎么用opencv,因此自己摸索了个使用文件流读取mnist的方法,armadillo仅作为储存矩阵的一种方式 ...
随机推荐
- 【代码笔记】Web-JavaScript-JavaScript 运算符
一,效果图. 二,代码. <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- mysql数据库的备份和恢复
Mysql数据库的备份和恢复 1.备份单个数据库 mysql数据库自带了一个很好用的备份命令,就是mysqldump,它的基本使用如下: 语法:mysqldump –u <用户名> -p ...
- Python __exit__,__enter__函数with语句的组合应用
__exit__,__enter__函数with语句的组合应用 by:授客 QQ:1033553122 简介 设计对象类时,我们可以为对象类新增两个方法,一个是__enter(self)__,一个 ...
- Python property使用简介
property使用简介 by:授客 QQ:1033553122 功能简介 1) 把类方法变成只读属性 2) setter和getter的另一种实现 代码演示1 #!/usr/bin/env pyth ...
- 微信小程序-全国快递查询
微信小程序-全国快递查询 摘要:WeChat.小程序.JS 开发过程 源码下载 1. GitHub 2. 百度云 链接:https://pan.baidu.com/s/1XVbtT2JsZslg4Y0 ...
- 【转】c# [Serializable]的作用
http://blog.csdn.net/chinarenkai/article/details/3220452 如果你做远程方法调用(RPC)时,比如,服务器端有个类A及对象a,客户端需要无视网络的 ...
- github仓库本地创建上传远程仓库
1.现在githubu创建自己心意的仓库. 2.然后再本地创建文件夹 echo"# (远程仓库的名字) >>README.md git add README.md git co ...
- 使用Visual Studio Team Services持续集成(三)——使用工件
使用Visual Studio Team Services持续集成(三)--使用工件 工件是应用程序的可部署组件.Visual Studio Team Services有能力在构建过程中显式地管理工件 ...
- [20190401]那个更快的疑问.txt
[20190401]那个更快的疑问.txt --//前一阵子,做了11g于10g下,单表单条记录唯一索引扫描的测试,摘要如下:--//参考链接:http://blog.itpub.net/267265 ...
- Python 面向对象的特性2-----继承
面向对象的三大特性 1.封装 根据职责将属性和方法封装到一个抽象的类中,然后类创建一个实实在在的对象,有了对象以后,就可以访问到对象内部的属性,或者让对象来调用一个已经封装好的方法. 2.继承 实现代 ...