语音端点检测(Voice Activity Detection,VAD)
本文内容均翻译自这篇博文:(该博主的相关文章都比较好,感兴趣的可以自行学习)
Voice Activity Detection(VAD) Tutorial
语音端点检测一般用于鉴别音频信号当中的语音出现(speech presence)和语音消失(speech absence)。这里将提供一个简单的VAD方法,当检测到语音时输出为1,否则,输出为0。
语音是否出现或者在背景噪声上是否平坦决定了VAD方法的检测是否稳定(The job of a VAD is to reliably determine if speech is present or not even in background noise)。在纯净背景噪声环境下(clean conditions),即使简单的能量检测方法也能够得到较好的语音检测效果,然而,一般情况下,我们得到的音频信号均会存在背景噪声。这就意味着,我们的VAD方法必须对噪声具有较好的鲁棒性。
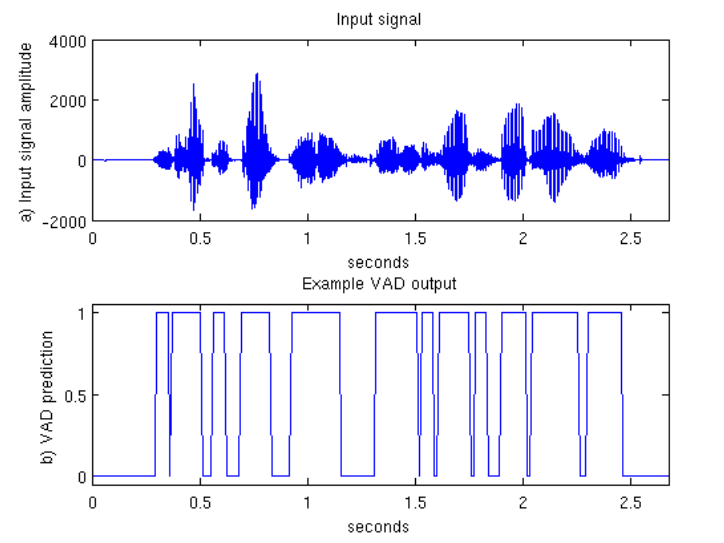
VAD的总体步骤如下:
- 将音频信号进行分帧处理;
- 从每一帧数据当中提取特征;
- 在一个已知语音和静默信号区域的数据帧集合上训练一个分类器;
- 对未知的分帧数据进行分类,判断其属于语音信号还是静默信号。
通常,一个VAD算法会将音频信号划分为发音部分(voiced)、未发音部分(unvoiced)和静默部分(silence)。这里介绍的特征能够很好的适用于这种分类任务,但是分类器的分类类别是3类而非两类(voiced speech,unvoiced speech and silence)。
预处理
第一步是将音频信号通过一个高通滤波器,截止频率大约为\(200Hz\)。这一步的目的是移除信号当中的直流偏置分量和一些低频噪声。虽然在低于\(200Hz\)的部分仍然有部分语音信息,但是不会对语音信号造成很大的影响。
在特征提取之前,我们首先要对音频信号进行长度为\(20-40ms\)的分帧,一般帧与帧之间的重叠为\(10ms\)。举例来说,如果我们的音频信号采样率为\(16kHz\),取窗口大小为\(25ms\),这种情况下,每一帧数据的所包含的数据点为:\(0.025*16000=400\)采样点。令帧之间重叠为\(10ms\)来计算,第一帧的数据起始点为\(sample 0\),第二帧数据的起始点为\(sample 160\)。
特征提取
分帧完成之后,就可以对每一帧数据进行特征提取。在下面的讨论中,\(x(n)\)为音频数据的一帧数据,其中\(n\)的范围为\(1 \rightarrow L\)(\(L\)为每一帧数据的长度)。对每一帧数据进行下面五种特征的提取:
- 对数帧能量(logarithm of frame energy):
\[
E=log(\sum\limits_{n=1}^{L}x(n)^2)
\] - 过零率(zero crossing rate):每一帧数据穿过零点的次数
- 在延迟一个位置处标准化自相关系数(normalised autocorrelation coefficient at lag 1):
\[
C=\frac{\sum\limits_{n=1}^{L-1}x(n)x(n-1)}{\sqrt{(\sum\limits_{n=1}^{L-1}x(n)^2)(\sum\limits_{n=1}^{L-1}x(n-1)^2)}}
\] - \(P_{th}\)阶线性预测的第一个系数
- \(P_{th}\)阶线性预测误差的对数
在本文中,我们使用\(P=12\),也就是说线性预测器的阶数为\(12\)。
分类
上面介绍的特征,单一使用时无法有效的对音频信号进行端点检测,但是我们可以使用多种特征的组合,来有效的解决这一问题,并且降低错误分类的概率。
Rabiner使用一个推测(calculating)静默信号特征均值和方差;语音信号特征均值和方差的贝叶斯分类器来进行分类。为了对一个未知数据帧进行分类,我们计算该数据帧来自每一个标签数据的似然,假设数据分布服从多变量高斯分布。然后,选择最大似然所对应的模型作为该数据帧的标签。
我们也可以选择discriminative classifier,如:支持矢量机,神经网络等。这里有一个SVM库libsvm,能够简单的训练一个SVM分类器来用于语音信号和静默信号的分类。
训练
训练分类器需要足够的带标签数据,这就要求人们进行人工标注数据。具体的,在VAD应用当中,要求对音频信号中的语音部分和静默部分进行划分。一般来说,带标签数据越多,训练得到的分类器分类效果越好。一个重要的细节是:在训练数据当中的背景噪声要尽量与测试数据当中的背景噪声相匹配,否则会引起噪声失配问题。如果你无法对训练和测试数据当中的噪声类型进行确定,那么尽量使用多种噪声和多种\(SNR\)(信噪比)数据对分类器进行训练。
如果你想要应用VAD到一个实际应用当中,如:电话语音数据,很重要的一点是:进行训练的数据需要在相同的通道(channel)获取,训练所获取数据的channel和应用场景的channel相同。这样可以降低训练数据集和测试数据集的失配问题。一旦训练完成之后,你可以获得一个可以预测未知数据标签的模型。
Putting it All Together
模型训练完成之后,我们可以使用该模型对未知数据帧的标签进行预测。随着数据中噪声的增加,可以推测到,VAD模型的准确率会下降。
有时,预测标签在speech present和speech abscent之间剧烈震荡,这种情况是我们所不愿意看到的。在这种情况下,我们可以对预测标签使用中值滤波Median Filter进行处理。
语音端点检测(Voice Activity Detection,VAD)的更多相关文章
- 语音激活检测(VAD)--前向神经网络方法(Alex)
这是学习时的笔记,包含相关资料链接,有的当时没有细看,记录下来在需要的时候回顾. 有些较混乱的部分,后续会再更新. 欢迎感兴趣的小伙伴一起讨论,跪求大神指点~ VAD(ffnn神经网络)-Alex t ...
- 异常检测(anomaly detection)
版权声明:本文为博主原创文章,转载或者引用请务必注明作者和出处,尊重原创,谢谢合作 https://blog.csdn.net/u012328159/article/details/51462942 ...
- Tensorflow物体检测(Object Detection)API的使用
Tensorflow在更新1.2版本之后多了很多新功能,其中放出了很多用tf框架写的深度网络结构(看这里),大大降低了吾等调包侠的开发难度,无论是fine-tuning还是该网络结构都方便了不少.这里 ...
- 多尺度目标检测 Multiscale Object Detection
多尺度目标检测 Multiscale Object Detection 我们在输入图像的每个像素上生成多个锚框.这些定位框用于对输入图像的不同区域进行采样.但是,如果锚定框是以图像的每个像素为中心生成 ...
- 实时人脸检测 (Real-Time Face Detection)
源地址:http://blog.sina.com.cn/s/blog_79b67dfe0102uzra.html 最近需要用到人脸检测,于是找了篇引用广泛的论文实现了一下:Robust Real-Ti ...
- 基于图形检测API(shape detection API)的人脸检测
原文:https://paul.kinlan.me/face-detection/ 在 Google 开发者峰会中,谷歌成员 Miguel Casas-Sanchez 跟我说:"嘿 Paul ...
- 目标检测--Scalable Object Detection using Deep Neural Networks(CVPR 2014)
Scalable Object Detection using Deep Neural Networks 作者: Dumitru Erhan, Christian Szegedy, Alexander ...
- 目标检测之行人检测(Pedestrian Detection)---行人检测之简介0
一.论文 综述类的文章 [1]P.Dollar, C. Wojek,B. Schiele, et al. Pedestrian detection: an evaluation of the stat ...
- 基于深度学习的目标检测(object detection)—— rcnn、fast-rcnn、faster-rcnn
模型和方法: 在深度学习求解目标检测问题之前的主流 detection 方法是,DPM(Deformable parts models), 度量与评价: mAP:mean Average Precis ...
随机推荐
- wcf_first
WCF包括3部分:client(需要连接到哪里,需要调用什么),service(宿主,及其消息的公开,地址的公开),wcf服务库(提供契约名称,及其怎么干) 步骤: 1.新建wcf库,其中提供一个契约 ...
- java过滤emoji表情
import java.util.regex.Matcher; import java.util.regex.Pattern; public class test { /** * 表情过滤 * */ ...
- struts2注解json 配置文件json
java提供了便捷的Json-lib 类库,能够让我们很方便的将 Array / JavaBean / Map 解析成 JSON 串,当然反之也是可以的. struts2借助于json-lib类库, ...
- 阿里云ossfs配置
Github:https://github.com/aliyun/ossfs/wiki Root账户卸载:umount /挂载目录非root用户要卸载目录,请用:fusermount -u your_ ...
- Spring.xml中配置注解context:annotation-config和context:component-scan简述
XML中context:annotation-config和context:component-scan简述 <context:annotation-config/> 中文意思:<上 ...
- Windows终端工具_MobaXterm
前言 有人喜欢小而美的工具,有人喜欢大集成工具.这里推荐一款增强型的Windows终端工具MobaXterm,它提供所有重要的远程网络工具(SSH,X11,RDP,VNC,FTP,MOSH ..... ...
- eval方法
1.作用 eval函数可计算某个字符串,并执行其中的Javascript代码 2.参数 eval函数的参数为一个string类型的字符串,不能是String()类型的对象 3.返回值 计算string ...
- 【译】在Transformer中加入相对位置信息
目录 引言 动机 解决方案 概览 注释 实现 高效实现 结果 结论 参考文献 本文翻译自How Self-Attention with Relative Position Representation ...
- 提升lua代码效率
local test = {} , do test[ i ] = {} end local t1 = os.clock( ) , do test[ ].mValue = end local t2 = ...
- java课程之团队开发冲刺1.5
一.总结昨天进度 1.昨天由于时间较少,没有太多的时间来进行学习Sqlite 二.遇到的困难 1.由于最终的程序需要调用本地的数据库,所以我们需要在安装程序的时候就需要直接附带安装一个本地的数据库到手 ...