MySQL中间件之ProxySQL(11):链式规则( flagIN 和 flagOUT )
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html
1.理解链式规则
在mysql_query_rules表中,有两个特殊字段"flagIN"和"flagOUT",它们分别用来定义规则的入口和出口,从而实现链式规则(chains of rules)。
链式规则的实现方式如下:
- 当入口值flagIN设置为0时,表示开始进入链式规则。如未显式指定规则的flagIN值,则默认都为0。
- 当语句匹配完当前规则后,将记下当前规则的flagOUT值,如果flagOUT值非空(NOT NULL),则为该语句打上flagOUT标记。如果该规则的apply字段值不是1,则继续向下匹配。
- 如果语句的flagOUT标记和下一条规则的flagIN值不同,则跳过该规则,继续向下匹配。直到匹配到
flagOUT=flagIN的规则,则匹配该规则。该规则是链式规则中的另一条规则。 - 直到某规则的apply字段设置为1,或者已经匹配完所有规则,则最后一次被评估的规则将直接生效,不再继续向下匹配。
通过下面两张图,应该很容易理解链式规则的生效方式。
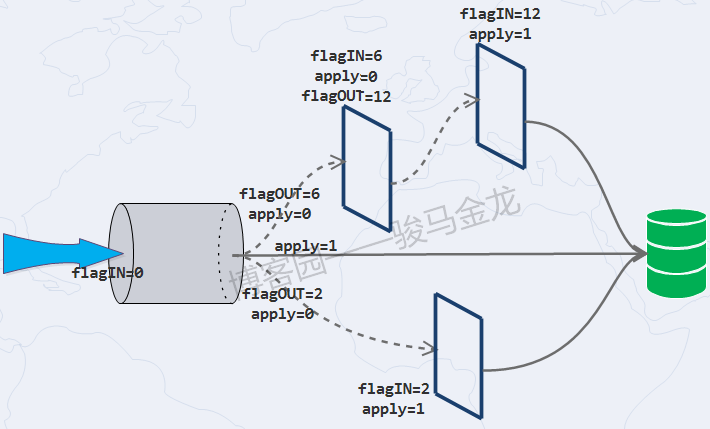
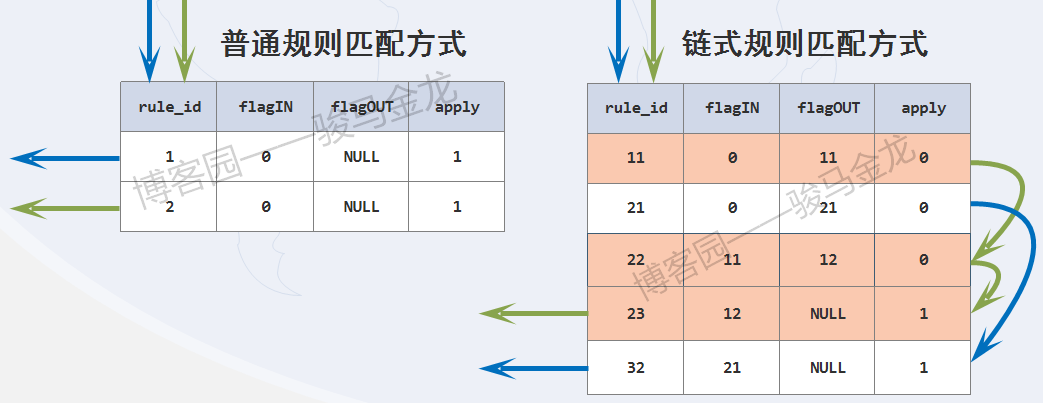
必须注意,规则是按照rule_id的大小顺序进行的。且并非只有apply=1时才会应用规则,当无规则可匹配,或者某规则的flagIN和flagOUT值相同,都会应用最后一次被评估的规则。
以下几个示例,可以解释生效规则:
# rule_id=3 生效
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | 23 |
| 3 | 0 | 23 | NULL |
+---------+-------+--------+---------+
# rule_id=2 生效
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | 23 |
| 3 | 0 | 24 | NULL |
+---------+-------+--------+---------+
# rule_id=2 生效,因为匹配完rule_id=2后,还打着flagOUT=23标记
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | NULL |
| 3 | 1 | 24 | NULL |
+---------+-------+--------+---------+
# rule_id=3 生效,因为匹配完rule_id=2后,还打着flagOUT=23标记
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | NULL |
| 3 | 1 | 23 | NULL |
+---------+-------+--------+---------+
2.链式规则示例
有了普通规则匹配方式,为什么还要设计链式规则呢?虽然ProxySQL通过正则表达式实现了很灵活的规则匹配模式,但需求总是千变万化的,有时候仅通过一条正则匹配规则和替换规则很难实现比较复杂的要求,例如sharding时。
链式规则除了常用的多次替换,还可巧用于多次匹配。
本文简单演示一下链式规则,不具有实际意义,只为后面ProxySQL实现sharding的文章做基础知识铺垫。
2个测试库,共4张表test{1,2}.t{1,2}。
mysql> select * from test1.t1;
+------------------+
| name |
+------------------+
| test1_t1_malong1 |
| test1_t1_malong2 |
| test1_t1_malong3 |
+------------------+
mysql> select * from test1.t2;
+------------------+
| name |
+------------------+
| test1_t2_malong1 |
| test1_t2_malong2 |
| test1_t2_malong3 |
+------------------+
mysql> select * from test2.t1;
+--------------------+
| name |
+--------------------+
| test2_t1_xiaofang1 |
| test2_t1_xiaofang2 |
| test2_t1_xiaofang3 |
+--------------------+
mysql> select * from test2.t2;
+--------------------+
| name |
+--------------------+
| test2_t2_xiaofang1 |
| test2_t2_xiaofang2 |
| test2_t2_xiaofang3 |
+--------------------+
现在借用链式规则,一步一步地将对test1.t1表的查询路由到test2.t2表的查询。再次声明,此处示例毫无实际意义,仅为演示链式规则的基本用法。
大致链式匹配的过程为:
test1.t1 --> test1.t2 --> test2.t1 --> test2.t2
以下是具体插入的规则:
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(1,1,0,0,23,"test1\.t1","test1.t2");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(2,1,0,23,24,"test1\.t2","test2.t1");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern,destination_hostgroup) values
(3,1,1,24,NULL,"test2\.t1","test2.t2",30);
load mysql query rules to runtime;
save mysql query rules to disk;
admin> select rule_id,
apply,
flagIN,
flagOUT,
match_pattern,
replace_pattern,
destination_hostgroup DH
from mysql_query_rules;
+---------+-------+--------+---------+---------------+-----------------+------+
| rule_id | apply | flagIN | flagOUT | match_pattern | replace_pattern | DH |
+---------+-------+--------+---------+---------------+-----------------+------+
| 1 | 0 | 0 | 23 | test1\.t1 | test1.t2 | NULL |
| 2 | 0 | 23 | 24 | test1\.t2 | test2.t1 | NULL |
| 3 | 1 | 24 | NULL | test2\.t1 | test2.t2 | 30 |
+---------+-------+--------+---------+---------------+-----------------+------+
查询test1.t1表,测试结果。
[root@xuexi ~]# mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"
+--------------------+
| name |
+--------------------+
| test2_t2_xiaofang1 | <-- 查询返回结果为test2.t2内容
| test2_t2_xiaofang2 |
| test2_t2_xiaofang3 |
+--------------------+
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 | <-- 3条规则全都命中
| 2 | 1 |
| 3 | 1 |
+---------+------+
admin> select hostgroup,digest_text from stats_mysql_query_digest;
+-----------+----------------------------------+
| hostgroup | digest_text |
+-----------+----------------------------------+
| 30 | select * from test2.t2 | <-- 路由目标hg=30
+-----------+----------------------------------+
显然,已经按照预想中的方式进行匹配、替换、路由。
一个问题:如果查询的是test1.t2表或test2.t1表,会进行链式匹配吗?
答案是不会,因为rule_id=2和rule_id=3这两个规则的flagIN都是非0值,而每个SQL语句初始时只进入flagIN=0的规则。
此外还需注意,当某语句未按照我们的期望途经所有的链式规则,则可能会根据destination_hostgroup字段的值直接路由出去,即使没有指定该字段值,还有用户的默认路由目标组,或者基于端口的路由目标。所以,在写链式规则时,应当尽可能地针对某一类型的语句进行完完整整的定制,保证这类语句能途经我们所期望的所有规则。
MySQL中间件之ProxySQL(11):链式规则( flagIN 和 flagOUT )的更多相关文章
- ProxySQL(11):链式规则( flagIN 和 flagOUT )
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9350631.html 理解链式规则 在mysql_query_rules表中,有两个特殊字段"fl ...
- MySQL中间件之ProxySQL(7):详述ProxySQL的路由规则
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.关于ProxySQL路由的简述 当ProxySQL收到前端app发 ...
- MySQL中间件之ProxySQL(9):ProxySQL的查询缓存功能
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html ProxySQL支持查询缓存的功能,可以将后端返回的结果集缓存在自己的 ...
- MySQL中间件之ProxySQL(1):简介和安装
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.ProxySQL简介 之前的文章里,介绍了一个MySQL的中间件: ...
- MySQL中间件之ProxySQL(10):读写分离方法论
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.不同类型的读写分离 数据库中间件最基本的功能就是实现读写分离,Pr ...
- MySQL中间件之ProxySQL(6):管理后端节点
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.配置后端节点前的说明 为了让ProxySQL能够找到后端的MySQ ...
- MySQL中间件之ProxySQL(8):SQL语句的重写规则
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.为什么要重写SQL语句 ProxySQL在收到前端发送来的SQL语 ...
- MySQL中间件之ProxySQL(14):ProxySQL+PXC
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.ProxySQL+PXC 本文演示ProxySQL代理PXC(Pe ...
- MySQL中间件之ProxySQL(5):线程、线程池、连接池
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.ProxySQL的线程 ProxySQL由多个模块组成,是一个多线 ...
随机推荐
- CodeForces 935E Fafa and Ancient Mathematics (树形DP)
题意:给定一个表达式,然后让你添加 n 个加号,m 个减号,使得表达式的值最大. 析:首先先要建立一个表达式树,这个应该很好建立,就不说了,dp[u][i][0] 表示 u 这个部分表达式,添加 i ...
- C++: find()函数的注意事项
头文件: <algorithm> iterator find(iterator it1, iterator it2, &T);
- Core Expression
https://docs.oracle.com/cd/E12058_01/doc/doc.1014/e12030/cron_expressions.htm A Cron Expressions Cro ...
- Think twice before starting the adventure
杂文一篇. 1. 取名字真心是一件特别困难的事情.这位独立开发者花了将近两天的时间,给他的私人项目取了个名字:这篇博客<为何我不鸟你的开源项目>里显然还忽视了一个原因,就是名字取得太烂以至 ...
- maven + eclipse + tomcat热部署 引自:http://jingpin.jikexueyuan.com/article/23068.html
方案二: 1.修改tomcat的server.xml配置文件,在host结点下添加如下代码 Xml代码 <Context docBase="F:\eclipse_workspace ...
- python网络爬虫开发实战(崔庆才)_14页_chromedriver环境配置和加载
自己1,环境配置,我下载了相对应的Chromedriver(其实我也不知道对不对应,都是下载最新版的我猜应该会对应),然后在任何文件夹下输入command+shift+G,打开输入窗口,任何输入 / ...
- 有关wkwebview和UIwebview获取html中的标签方法
wkwebview方法如下: [webView evaluateJavaScript:@"navigator.userAgent" completionHandler:^(id r ...
- spring 读取yaml配置文件
从Spring框架4.1.0增加了对YAML的支持,Spring框架4.1.0 maven POM具有Snakeyaml依赖性 . 您可以在Spring Boot应用中使用两种方式加载YAML: 1 ...
- 新鲜出炉的一套Java面试题
作者:孤独烟 由于近期是互联网寒冬,然而烟哥的好友还是顶着重重压力出去面试,最终斩获无数offer.在烟哥的沟通下,终于套得其中一套题目,故在此分享! 公司:国内三巨头其中的一家!面试时间约在1月份左 ...
- eclipse创建Maven web项目的步骤
Maven 是一个项目管理工具,可以对 Java 项目进行构建.依赖管理. Maven 能够帮助开发者完成以下工作: 构建 文档生成 报告 依赖 SCMs 发布 分发 邮件列表 一.环境配置 Mave ...