反爬虫——使用chrome headless时一些需要注意的细节
以前我们介绍过chrome headless的用法(https://www.cnblogs.com/apocelipes/p/9264673.html)。
今天我们要稍微提一下其中一个细节。
反爬和window.navigator对象
navigator对象,一个对大家来说既熟悉又陌生的名词,熟悉是因为在学BOM对象的时候或多或少都见过甚至在代码中使用过,陌生是因为对于navigator对象来说虽然各大浏览器都有实现却一直没有一个统一的标准,所以在不同浏览器上的navigator对象也可能是不一样的,所以不鼓励在生产环境使用,用得少,自然也就陌生了。
然而反爬就是要不从常规处下手,如果有某个特性比较冷僻,又可以用来区分人类用户和爬虫或者增加爬取难度,那么它就一定会被反爬工程师善加利用。今天我们的主角就是navigator对象了。
一般的反爬虫会有header验证,浏览器验证等等,这些在你使用headless browsers时都不成问题,所以反爬工程师们要如何阻止你的爬虫呢?不急,我们先看下正常浏览器里navigator对象的内容:

这是chrome浏览器,因为headless没办法截图,所以我就把navigator对象的属性全部保存成了文本,这是使用headless时的信息:
vendorSub:
productSub: 20030107
vendor: Google Inc.
cookieEnabled: true
appCodeName: Mozilla
appName: Netscape
appVersion: 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ...
...
webdriver: true
...
unregisterProtocolHandler: function unregisterProtocolHandler() { [native code] }
deviceMemory: 8
clipboard: {}
...
因为篇幅,我做了节选,需要注意的就是红色的部分,这是相比正常浏览器所多出来的部分。
经常和爬虫打交道的可能已经看出了,这是启用了webdriver协议之后会包含的字段,可是我们使用的chrome headless使用的是devtools protocol啊,怎么也会有这个标志呢?
答案在这里:
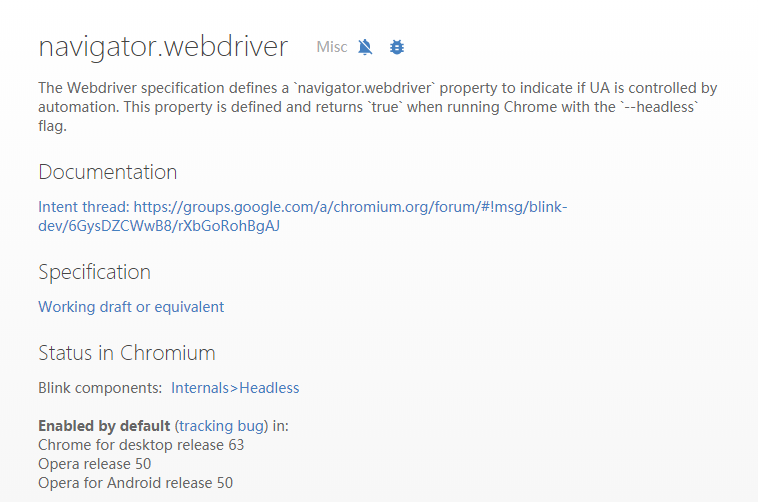
没错,当你指定了“--headless”参数的时候,不管是什么协议,都会带有该字段,如果你不指定“--headless”参数使用devtools protocol控制chrome,那么就和使用正常的浏览器没有区别。
仔细想一想,正常的人类访问网页怎么可能用没有界面的headless模式嘛,这样如果你不当心的话一抓一个准。
解决方案
解决办法其实也不麻烦,大致有如下几点:
- 更换浏览器,如上图所示,这一特性是chrome 63以后添加的,那么只要用chrome 62即可,devtools protocol也支持chrome 62;
- 不使用headless模式,不使用headless模式也自然不会被检测到,当然,启动一个浏览器窗口来渲染页面,性能肯定是不及headless的,这点需要权衡;
- 只对必要的页面使用headless,其余数据仍用httpclient模拟请求的方式获取,这也是最有效的方式,当然这样会极大的增加开发成本。
总之绕过这一检测机制的方法有很多,这篇文章仅仅是抛砖引玉而已,希望大家以后遇到类似的反爬措施时不要觉得束手无策。
最后希望大家在做爬虫时请遵守网络道德,不要给对方站点添麻烦。
如果有意见和建议,欢迎指出!
参考:https://www.chromestatus.com/feature/6216034532982784
反爬虫——使用chrome headless时一些需要注意的细节的更多相关文章
- 【Python3爬虫】常见反爬虫措施及解决办法(一)
这一篇博客,是关于反反爬虫的,我会分享一些我遇到的反爬虫的措施,并且会分享我自己的解决办法.如果能对你有什么帮助的话,麻烦点一下推荐啦. 一.UserAgent UserAgent中文名为用户代理,它 ...
- 反爬虫和抗DDOS攻击技术实践
导语 企鹅媒体平台媒体名片页反爬虫技术实践,分布式网页爬虫技术.利用人工智能进行人机识别.图像识别码.频率访问控制.利用无头浏览器PhantomJS.Selenium 进行网页抓取等相关技术不在本文讨 ...
- Python爬虫与反爬虫(7)
[Python基础知识]Python爬虫与反爬虫(7) 很久没有补爬虫了,相信在白蚁二周年庆的活动大厅比赛中遇到了关于反爬虫的问题吧 这节我会做个基本分享. 从功能上来讲,爬虫一般分为数据采集,处理, ...
- 笔记-selenium+chrome headless
笔记-selenium+chrome headless 1. selenium+chrome headless phantomjs与selenium分手了,建议使用其它无头浏览器. chro ...
- 大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫
大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫 大众点评的反爬虫手段有那些: 封ip,封账号,字体库反爬虫,css文字映射,图形滑动验证码 这个图片是滑动验证码,访问频率高的话,会出 ...
- 反爬虫2(代理ip)
在进行爬虫访问时,被访问主机除了会校验访问身份,还会校验访问者的ip, 当短时间同ip大量访问时,主机有可能会拒绝 返回,所以就现需要代理ip, 百度中可以获取到大量的免费的代理ip(ps:注意在访问 ...
- 深入细枝末节,Python的字体反爬虫到底怎么一回事
内容选自 即将出版 的<Python3 反爬虫原理与绕过实战>,本次公开书稿范围为第 6 章——文本混淆反爬虫.本篇为第 6 章中的第 4 小节,其余小节将 逐步放送 . 字体反爬虫开篇概 ...
- Python 爬虫工程师必看,深入解读字体反爬虫
字体反爬虫开篇概述 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- 使用Python自动填写问卷星(pyppeteer反爬虫版)
写此文的目的是为了方便寒假自己忘记填问卷星 一开始的想法和去年一样,去年就写过一版,想着今年不过就是改改数据,换换id而已,另外没想到的事情发生了... 满怀信心的写完代码 from selenium ...
随机推荐
- nginx,hello World!
向nginx中添加第一个最简单的hello world模块 一.编写ngx_http_mytest_module模块 1. ngx_http_mytest_module.c #include < ...
- android-effect
1. 基本框架 2.初探
- selenium自动化打开浏览器不受信任解决办法
之前在用selenium(火狐浏览器)打开一个https网站时,总是弹出不受信任,修改配置后,每次加载的浏览器都是还原了配置,无法加载出页面,这里给出解决办法:让浏览器去加载我们修改后的配置,具体如下 ...
- POJ - 3984 迷宫问题 bfs解法
#include<stdio.h> #include<string.h> #include<algorithm> #include<stack> usi ...
- NUC970开发板烧录
本次烧录的采用新塘公司官方的NuWriter软件进行烧录,现在我们首先来讲解如何将uboot,Linux内核,根文件系统烧录到开发板上. 过程中所需文件链接: 链接:https://pan.baidu ...
- 支持Linux,嗅探和注入功能的网卡
支持的WiFi USB 以下是已知可以很好地支持Linux,嗅探和注入功能,外部天线(可以替换)和强大的TX功率以及良好的RX灵敏度的Wifi卡的列表 TP-LINK TL-WN722N(仅限卷1) ...
- vscode配置git及码云
1.将代码放到码云 到码云里新建一个仓库,完成后码云会有一个命令教程按上面的来就行了 码云中的使用教程: Git 全局设置: git config --global user.name "A ...
- 在使用可变数组过程中遇到*** Terminating app due to uncaught exception 'NSInternalInconsistencyException', reason: '-[__NSCFDictionary setObject:forKey:]: mutating method sent to immutable object'问题
*** Terminating app due to uncaught exception 'NSInternalInconsistencyException', reason: '-[__NSCFD ...
- VSCode插件开发全攻略(八)代码片段、设置、自定义欢迎页
更多文章请戳VSCode插件开发全攻略系列目录导航. 代码片段 代码片段,也叫snippets,相信大家都不陌生,就是输入一个很简单的单词然后一回车带出来很多代码.平时大家也可以直接在vscode中创 ...
- 在ASP.NET MVC里对Web Page网页进行权限控制
我们在ASP.NET MVC开发时,有时候还是得设计ASP.NET的Web Page网页(.aspx和.aspx.cs),来实现一些ASP.NET MVC无法实现的功能,如此篇<Visual S ...