用caffe进行图片检索
1.图片的处理
输入:将自己的图像转换成caffe需要的格式要求:lmdb 或者 leveldb 格式
这里caffe有自己提供的脚本:create_minst.sh
转换训练图片和验证图片的格式,运行脚本以后生成对应的:***_train_Imdb 文件夹,***_val_Imdb文件夹

在此注意的是 数据的标注:
create_minst.sh里的输入是train.txt 和val.txt (这两个文件分别保存的是:训练train图片的路径以及标签,还有验证val图片的路径和标签 )
格式如下:
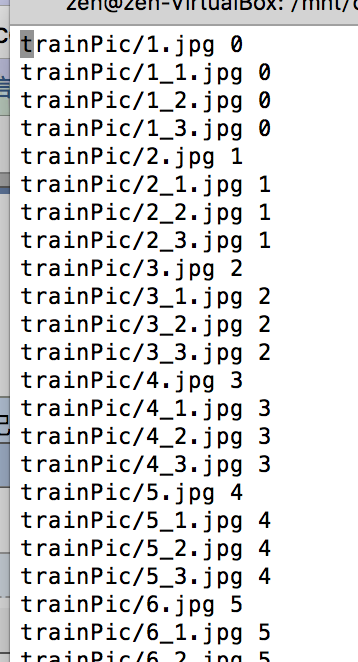
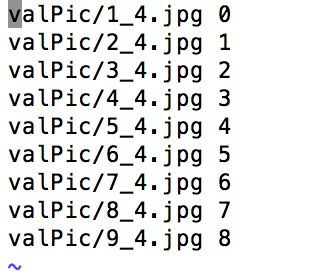
在create_imagenet.sh注意要写好train.txt与val.txt的文件路径
2. 编写配置文件并训练模型
配置文件有两个:1.参数的配置文件solver_**.prototxt(这里可以修改迭代的次数,步率以及其他内容,我只修改了迭代次数)
2.训练网络的配置文件:train_CIFAR10_48.prototxt,test_CIFAR10_48.prototxt
在train_CIFAR10_48.prototxt这里的source 就是我们之前转换好的caffe对应的训练图片的leveldb文件夹,同理test_CIFAR10_48.prototx
在这里需要注意的是meanfile是均值文件,他可以提高你的训练准确率。我这里没有自己生成均值文件,而是用的ilsvrc12库的均值文件~
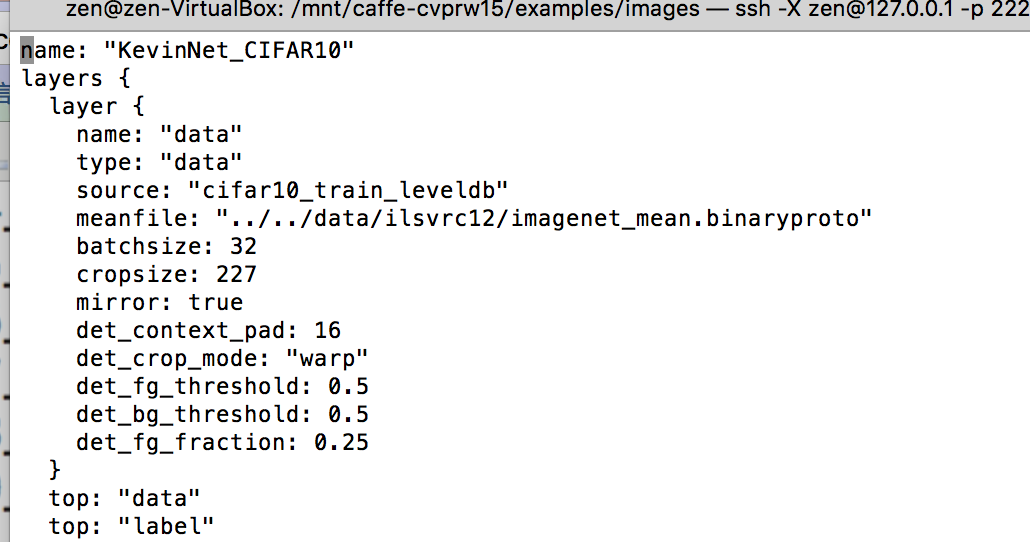
接下来运行训练的脚本:train.sh
脚本内容如下: 这里指定了了参数配置文件solver_CIFAR10_48.prototxt
还有一个值得提一句的是:bvlc_reference_caffenet.caffemodel这是一个与训练模型,需要提前下载好。 gpu -1是用cpu,
../../build/tools/caffe train -solver solver_CIFAR10_48.prototxt -weights ../../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu -1 2>&1 | tee log.txt
运行完以后会生成model文件:例子中我训练500次。

3.利用model来测试
这里有脚本文件:run_*.m
top_K代表匹配出几个相似图片 如果只想要匹配出最最相似的top_k=1
接下来的路径按照自己的路径填写。
强调的是:test_file_list存储的是要进行预测的图片路径,
test_label_list存储的是预测图片的正确答案(因为如果要求准确率,需要这个文件,如果不需要的话就忽略吧注释掉,然后把算精确率的代码注释掉就ok了)
train_file_list就是你的图片集,预测图片在这个图片集里寻找与 它最最匹配的picture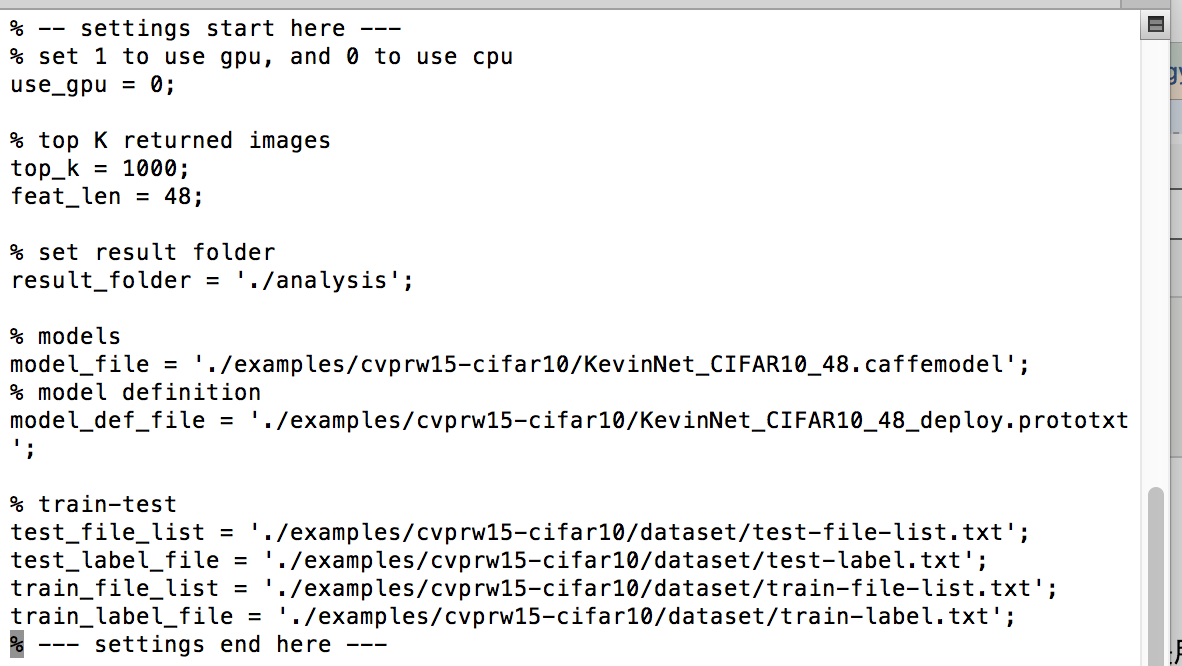
_
-->
用caffe进行图片检索的更多相关文章
- 基于纹理的图片检索及demo(未启动)
基于纹理的图片检索及demo(未启动)
- windows+caffe(二)——图片转换为levedb格式
借鉴于langb2014的 http://blog.csdn.net/langb2014/article/details/50458520 与liukailun09的 http://blog.cs ...
- 总结一下用caffe跑图片数据的研究流程
近期在用caffe玩一些数据集,这些数据集是从淘宝爬下来的图片.主要是想研究一下对女性衣服的分类. 以下是一些详细的操作流程,这里总结一下. 1 爬取数据.写爬虫从淘宝爬取自己须要的数据. 2 数据预 ...
- 基于内容的图片检索CBIR(Content Based Image Retrieval)简介
传统的图像检索过程,先通过人工对图像进行文字标注,再利用关键字来检索图像,这种依据图像描述的字符匹配程度提供检索结果的方法,简称“以字找图”,既耗时又主观多义.基于内容的图像检索客服“以字找图”方式的 ...
- 基于内容的图片检索CBIR简介
原文地址:http://blog.csdn.net/davebobo/article/details/53171311 传统的图像检索过程,先通过人工对图像进行文字标注,再利用关键字来检索图像,这种依 ...
- caffe学习--使用caffe中的imagenet对自己的图片进行分类训练(超级详细版) -----linux
http://blog.csdn.net/u011244794/article/details/51565786 标签: caffeimagenet 2016-06-02 12:57 9385人阅读 ...
- ios 工程图片清理shell
#!/bin/shecho "随意删除@2x图片可能会引起错误 因为ios工程会更加前缀和分辨率自己找到@2x的图片 所以删除@2x图片时要慎重"read -n1 -p &quo ...
- caffe特征层可视化
#参考1:https://blog.csdn.net/sushiqian/article/details/78614133#参考2:https://blog.csdn.net/thy_2014/art ...
- 神经网络:caffe特征可视化的代码例子
caffe特征可视化的代码例子 不少读者看了我前面两篇文章 总结一下用caffe跑图片数据的研究流程 deep learning实践经验总结2--准确率再次提升,到达0.8.再来总结一下 之后.想知道 ...
随机推荐
- .NET 互联网技术简介
概述 技术更新太快,尤其是在互联网公司里,很多新的主流技术,我们还是必须要知道和熟练使用的.下面就给大家简单介绍,入门还是需要大家更努力的去深入学习. 目录 Git 入门 常用软件安装及VS插件工具 ...
- 面经:Google两轮背靠背
如题,谷歌两轮背靠背电面.两轮都是废话不多说直奔coding,虽然第一轮的中国大哥还是花了一点点时间了解了一下我的背景.毕业时间.research方向.说好的research面呢? 中国大哥出的题: ...
- C++Builder6.0 新建和打开项目软件死机
大清早上班打开C++Builder6.0软件,打开项目却卡死,甚是奇怪,然后尝试新建项目也同样卡死.尝试打开一个CPP文件,可以打开,再尝试打开项目.bpr文件,便打开了.至于原因为什么,那就不得而知 ...
- MySQL个人学习笔记
目录: 数据库的基本操作 创建.删除用户及授权 数据库字符校对集 创建.删除数据库和表 DML操作 DDL操作 索引 事务 一.数据库的基本操作 -- 选择要操作的数据库 -- world:数据库名 ...
- 024-linux中动态库libXXX.so
1.动态库的概念.动态链接库与普通的程序相比而言,没有main函数,是一系列函数的实现.通过shared和fPIC编译参数生产so动态链接库文件.程序在调用库函数时,只需要连接上这个库即可. 2.动态 ...
- bzoj3196: Tyvj 1730 二逼平衡树 树套树
地址:http://www.lydsy.com/JudgeOnline/problem.php?id=3196 题目: 3196: Tyvj 1730 二逼平衡树 Time Limit: 10 Sec ...
- 【Redis学习之一】Redis
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 一.Redis入门介绍 数据存储的发展:文件存储--> ...
- 深入hibernate的三种状态(转)
hibernate的三种状态: 瞬时对象,持久化对象,托管对象. hibernate的两级缓存:1>一级缓存:session 2>二级缓存:sessionfactory. 瞬时对象: ...
- MySQL数据库----事务处理
事物处理 一. 什么是事务 一组sql语句批量执行,要么全部执行成功,要么全部执行失败 二.为什么出现这种技术 为什么要使用事务这个技术呢? 现在的很多软件都是多用户,多程序,多线程的,对同一 ...
- python之路----hashlib模块
在平时生活中,有很多情况下,你在不知不觉中,就用到了hashlib模块,比如:注册和登录认证注册和登录认真过程,就是把注册用的账户密码进行:加密 --> 解密 的过程,在加密.解密过程中,用的了 ...