Mysql 优化,慢查询
最近项目上遇到点问题,服务器出现连接超时。上次也是超时,问题定位到mongodb上,那次我修改好了,这次发现应该不是这个的问题了。
初步怀疑是mysql这边出问题了,写的sql没经过压力测试,导致用户量多的时候,出现拥堵。
好,那就来看看mysql方便的慢查询吧,来看看具体的哪些sql查询慢,从这里开始来优化下。
一:开启慢查询
先来看看慢查询日志设置的时间长度:
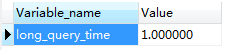
show VARIABLES LIKE 'long%'
返回,long_query_time 指定了慢查询的阈值,即如果执行语句的时间超过该阈值则为慢查询语句,默认值为10秒。这里设置的为1s
慢查询日志开启情况:
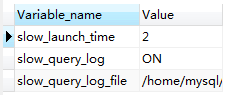
SHOW VARIABLES LIKE 'slow%'
返回:slow_query_log的值为ON为开启慢查询日志,OFF则为关闭慢查询日志。
slow_query_log_file 的值是记录的慢查询日志到文件中(注意:默认名为主机名.log,慢查询日志是否写入指定文件中,需要指定慢查询的输出日志格式为文件,相关命令为:show variables like ‘%log_output%’;去查看输出的格式)
通过以上命令,确定慢查询已经打开了。然后去看慢查询日志就行。
由于这里用的是阿里云的数据库,所以提供了后台可以很方便的查询到日志和下载日志。

这里点击下载即可将慢查询的日志下载下来。
二:分析慢查询日志
1. 截取一段慢查询日志:
# Time: 180918 19:06:21
# User@Host: proxy[proxy] @ [192.168.0.16] Id: 6707197
# Query_time: 1.015429 Lock_time: 0.000116 Rows_sent: 1 Rows_examined: 44438
SET timestamp=1537268781;
select
id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag,
nodisturb_mode, nodisturb_start_time,
nodisturb_end_time, binding_time, device_os_type, app_type, state
from app_mobile_device
where user_id = '78436'
and app_type = 'YGY'
order by binding_time desc;
# User@Host: proxy[proxy] @ [192.168.0.16] Id: 6707236
# Query_time: 1.021662 Lock_time: 0.000083 Rows_sent: 1 Rows_examined: 44438
SET timestamp=1537268781;
select
id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag,
nodisturb_mode, nodisturb_start_time,
nodisturb_end_time, binding_time, device_os_type, app_type, state
from app_mobile_device
where user_id = '14433'
and app_type = 'YGY'
order by binding_time desc;
这里可以看到:
Query_time (慢查询语句的查询时间) 都超过了设置的 1s,
Rows_sent (慢查询返回记录) 这里只返回了 1 条
Rows_examined (慢查询扫描过的行数) 44438 -> 通过这里大概可以看出问题很大
2.现在将这个SQL语句放到数据库去执行,并使用EXPLAIN分析 看下执行计划。
EXPLAIN
select
id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag,
nodisturb_mode, nodisturb_start_time,
nodisturb_end_time, binding_time, device_os_type, app_type, state
from app_mobile_device
where user_id = '78436'
and app_type = 'YGY'
order by binding_time desc;
查询结果是:

解释下参数:
| SELECT识别符。这是SELECT的查询序列号 | |
| select_type |
SELECT类型,可以为以下任何一种:
|
| table |
输出的行所引用的表 |
| type |
联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
|
| possible_keys |
指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。 |
| key_len | 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。 |
| ref | 显示使用哪个列或常数与key一起从表中选择行。 |
| rows | 显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。 |
| filtered | 显示了通过条件过滤出的行数的百分比估计值。 |
| Extra |
该列包含MySQL解决查询的详细信息
|
这里可以发现:rows 为查询的行数,查询了4w多行,那慢是肯定的了。
因为这里是好几个条件,并且没有使用一个索引,那就只能给添加索引了,
这里给选择添加普通多列索引,因为这个表在最开始设计出问题了,导致有重复的数据,不能设置唯一索引了。
ALTER TABLE app_mobile_device ADD INDEX user_app_type_only ( `user_id` ,`app_type` )
索引设置了,再看下刚的SQL的执行计划。

可以发现rows 的检查行数,很明显的下降了。
到此,慢查询的使用和优化就基本完成了。
Mysql 优化,慢查询的更多相关文章
- MySQL——优化嵌套查询和分页查询
优化嵌套查询 嵌套查询(子查询)可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中.嵌套查询写起来简单,也容易理解.但是,有时候可以被更有效率的连接(JOIN ...
- mysql优化-》查询缓存
使用MySql查询缓存(query_cache_size) 在MySql中查询缓存的原理: 其实是MySql创建了一个临时的空间叫Qcache(这个空间生成在MySql的编译器内存中),这个空间的大小 ...
- MySQL优化COUNT()查询
COUNT()聚合函数,以及如何优化使用了该函数的查询,很可能是最容易被人们误解的知识点之一 COUNT()的作用 COUNT()是一个特殊的函数,有两种非常不同的作用: 统计某个列值的数量 统计行数 ...
- MySQL优化总结-查询总条数
1.COUNT(*)和COUNT(COL) COUNT(*)通常是对主键进行索引扫描,而COUNT(COL)就不一定了,另外前者是统计表中的所有符合的纪录总数,而后者是计算表中所有符合的COL的纪录数 ...
- MySql优化子查询
用子查询语句来影响子查询中产生结果rows的数量和顺序. For example: SELECT * FROM t1 WHERE t1.column1 IN (SELECT column1 FROM ...
- Mysql优化--慢查询日志
Mysql 系列文章主页 =============== 默认没有开启慢查询日志功能.如果不是调优需要的话,一般不建议开启. 查看是否开启慢查询日志: SHOW VARIABLES LIKE '%sl ...
- mysql 优化之查询缓存(mysql8已经废弃这个功能)
对于缓存,一般人想到的是 redis.memcache 这些内存型的缓存. 但是实际上 mysql 也提供了缓存,mysql 里面的缓存是查询缓存,可以把我们查询过的语句缓存下来,下一次查询的时候有可 ...
- mysql优化 慢查询(一)
1.显示慢查询的一些参数的命令:show variables like '%slow%';结果如图
- mysql 优化like查询
1. like %keyword 索引失效,使用全表扫描.但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描. 2. like keyword% 索引有 ...
- MySQL优化、锁
1. MySQL优化-查看执行记录 MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化. 使用ex ...
随机推荐
- Php廖雪峰教程学习与实战
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000 目录 Python教程 Pyth ...
- 解决Mac上adb: command not found问题
使用mac进行开发的时候,有时候需要使用adb指令来进行一些操作,但是如果没有配置过Android环境变量,可能会出现adb: command not found的问题,查了一些资料,这里记录一下ma ...
- redis cluster 集群重新启动关闭
找遍了redis cluster官方文档,没发现有关集群重新启动和关闭的方法.为啥会没有呢,推測redis cluster至少要三个节点才干执行,三台同一时候挂掉的可能性比較小,仅仅要不同一时候挂掉. ...
- 跟我学SharePoint 2013视频培训课程——怎样创建列表和列表项(7)
课程简介 第7天,怎样在SharePoint 2013中创建列表和列表项 视频 SharePoint 2013 交流群 41032413
- 使用 Apache Commons CSV 读写 CSV 文件
有时候,我们需要读写 CSV 文件,在这里给大家分享Apache Commons CSV,读写 CSV 文件非常方便. 具体官方文档请访问Apache Commons CSV. 官方文档已经写得很详细 ...
- mysql中and 和 or 联合使用
以下是两张表,我只列出有用的字段. Table:student_score 学生成绩 sid(学生ID) cid(课程ID) score(分数) 5 1 50 5 2 110 5 3 64 5 4 n ...
- 更改 AWS RDS mysql时区 -摘自网络
AWS RDS AWS上搭建数据库的时候,不是DB on EC2就是RDS,但是选择RDS时,Timezone怎么处理? 「面向全球提供的AWS来讲理所当然的是UTC」,而RDS也不是例外.把服务器迁 ...
- 在 Windows Server 2008 中部署带 SignalR 的网站出错
一直是在 Windows Server 2008 R2 或更高版本的 Windows 中进行部署,没有遇到过此现象,不知道是不是因为系统的原因. 现象为从浏览器访问配置 signalr 的地址返回 4 ...
- 求最大连续和——dp
输入一组整数,求出这组数字子序列和中最大值.也就是仅仅要求出最大子序列的和,不必求出最大的那个序列. 比如: 序列:-2 11 -4 13 -5 -2,则最大子序列和为20. 序列:-6 2 4 -7 ...
- 精通D3.js笔记
DOM常用属性 innerHTML: 元素标签内部的文本. innerText outerHTML outerText nodeName: 节点名称 parentNode: 父节点 nextSibli ...