8.11 数据库ORM(5)
2018-8-11 20:43:52
昨天从俺弟家回来了.
和俺弟聊天发现,他一直停留在自己目前的圈子,自己觉得很牛逼,比别人高人一等,,
读书无用论,,可以用 幸存者偏激理论 大概就是这个 可以否决,,
越努力,越幸运!
每个人选择不同,追求的东西不同!
ORM参考 https://www.cnblogs.com/wupeiqi/articles/5713330.html
明天看数据库的最后一节 然后进入前端知识,,然后可以愉快的Django啦!!
睡觉睡觉!!2018-8-11 21:38:27 cf已经不大好完了,多花点时间看书!!!! 要把百年孤独看完,和苏东坡传!!!
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index,CHAR,VARCHAR
from sqlalchemy.orm import sessionmaker, relationship
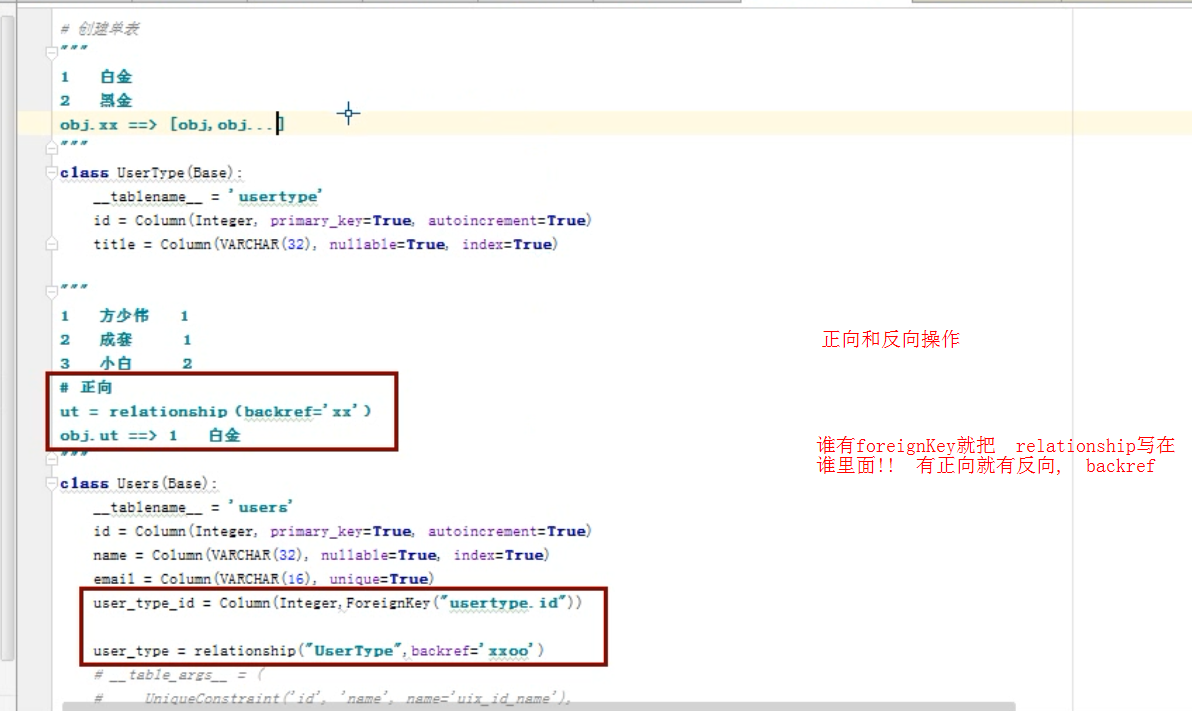
from sqlalchemy import create_engine Base = declarative_base() # 创建单表
"""
1 白金
2 黑金
obj.xx ==> [obj,obj...]
"""
class UserType(Base):
__tablename__ = 'usertype'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(VARCHAR(32), nullable=True, index=True) """
1 方少伟 1
2 成套 1
3 小白 2
# 正向
ut = relationship(backref='xx')
obj.ut ==> 1 白金
"""
class Users(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(32), nullable=True, index=True)
email = Column(VARCHAR(16), unique=True)
user_type_id = Column(Integer,ForeignKey("usertype.id")) user_type = relationship("UserType",backref='xxoo')
# __table_args__ = (
# UniqueConstraint('id', 'name', name='uix_id_name'),
# Index('ix_n_ex','name', 'email',),
# ) def create_db():
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/s4day62db?charset=utf8", max_overflow=5)
Base.metadata.create_all(engine) def drop_db():
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/s4day62db?charset=utf8", max_overflow=5)
Base.metadata.drop_all(engine) engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/s4day62db?charset=utf8", max_overflow=5)
# 取一个连接 来连接用户
Session = sessionmaker(bind=engine)
session = Session() # 类 -> 表
# 对象 -> 行
# ###### 增加 ######
#
# obj1 = UserType(title='普通用户')
# session.add(obj1) # objs =[
# UserType(title='超级用户'),
# UserType(title='白金用户'),
# UserType(title='黑金用户'),
# ]
# session.add_all(objs) # ###### 查 ######
# print(session.query(UserType))
# user_type_list = session.query(UserType).all()
# for row in user_type_list:
# print(row.id,row.title) # select xxx UserType where
# user_type_list = session.query(UserType.id,UserType.title).filter(UserType.id > 2)
# for row in user_type_list:
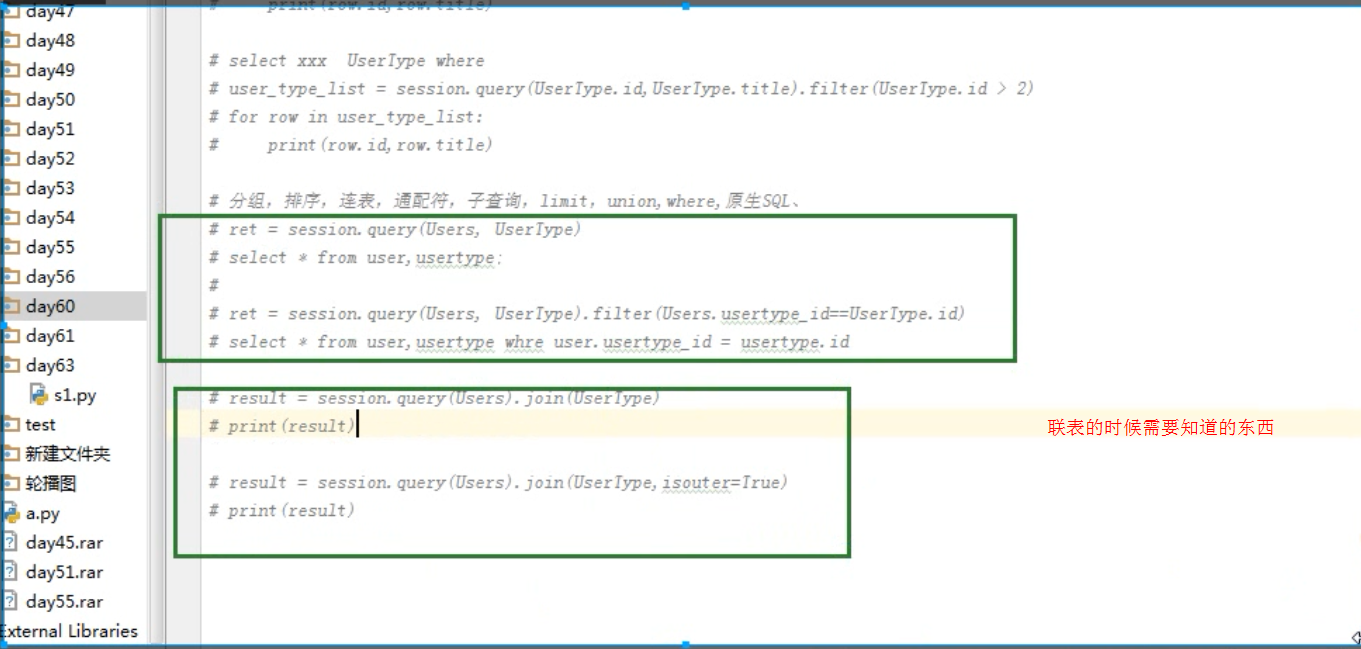
# print(row.id,row.title) # 分组,排序,连表,通配符,子查询,limit,union,where,原生SQL、
# ret = session.query(Users, UserType)
# select * from user,usertype;
#
# ret = session.query(Users, UserType).filter(Users.usertype_id==UserType.id)
# select * from user,usertype whre user.usertype_id = usertype.id # result = session.query(Users).join(UserType)
# print(result) # result = session.query(Users).join(UserType,isouter=True)
# print(result) # # 1.
# select * from b where id in (select id from tb2) # 加上 .subquery() 设置为子查询 # 2 select * from (select * from tb) as B
# q1 = session.query(UserType).filter(UserType.id > 0).subquery()
# result = session.query(q1).all()
# print(result) #
# select
# id ,
# (select * from users where users.user_type_id=usertype.id)
# from usertype; # session.query(UserType,session.query(Users).filter(Users.id == 1).subquery())
# session.query(UserType,Users)
# result = session.query(UserType.id,session.query(Users).as_scalar())
# print(result)
# result = session.query(UserType.id,session.query(Users).filter(Users.user_type_id==UserType.id).as_scalar())
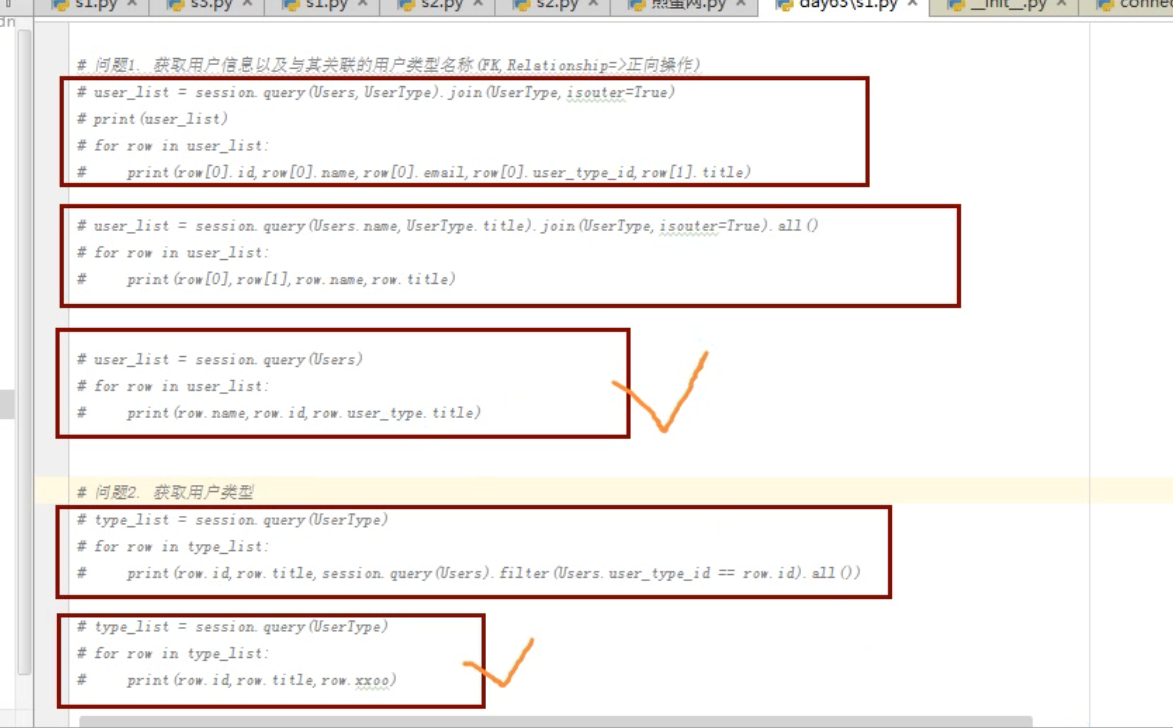
# print(result) # 问题1. 获取用户信息以及与其关联的用户类型名称(FK,Relationship=>正向操作)
# user_list = session.query(Users,UserType).join(UserType,isouter=True)
# print(user_list)
# for row in user_list:
# print(row[0].id,row[0].name,row[0].email,row[0].user_type_id,row[1].title) # user_list = session.query(Users.name,UserType.title).join(UserType,isouter=True).all()
# for row in user_list:
# print(row[0],row[1],row.name,row.title) # user_list = session.query(Users)
# for row in user_list:
# print(row.name,row.id,row.user_type.title) # 问题2. 获取用户类型
# type_list = session.query(UserType)
# for row in type_list:
# print(row.id,row.title,session.query(Users).filter(Users.user_type_id == row.id).all()) # type_list = session.query(UserType)
# for row in type_list:
# print(row.id,row.title,row.xxoo) # ###### 删除 ######
# session.query(UserType.id,UserType.title).filter(UserType.id > 2).delete() # ###### 修改 ######
# session.query(UserType.id,UserType.title).filter(UserType.id > 0).update({"title" : "黑金"})
# session.query(UserType.id,UserType.title).filter(UserType.id > 0).update({UserType.title: UserType.title + "x"}, synchronize_session=False)
# session.query(UserType.id,UserType.title).filter(UserType.id > 0).update({"num": Users.num + 1}, synchronize_session="evaluate") session.commit()
session.close()
8.11 数据库ORM(5)的更多相关文章
- Android 开源项目android-open-project工具库解析之(一) 依赖注入,图片缓存,网络相关,数据库orm工具包,Android公共库
一.依赖注入DI 通过依赖注入降低View.服务.资源简化初始化.事件绑定等反复繁琐工作 AndroidAnnotations(Code Diet) android高速开发框架 项目地址:https: ...
- LitepalNewDemo【开源数据库ORM框架-LitePal2.0.0版本的使用】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 本Demo使用的是LitePal2.0.0版本,对于旧项目如何升级到2.0.0版本,请阅读<赶快使用LitePal 2.0版本 ...
- mysql学习(2)-Navicat Premium 12 链接MySQL8.0.11数据库报2059错误
Navicat Premium 12 链接MySQL8.0.11数据库报2059错误 1,问题现象 安装完MySQL8.0.11和Navicat Premium12后,我们会用Navicat去测试连接 ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
- tornado 06 数据库—ORM—SQLAlchemy——基本内容及操作
tornado 06 数据库—ORM—SQLAlchemy——基本内容及操作 一. ORM #在服务器后台,数据是要储存在数据库的,但是如果项目在开发和部署的时候,是使用的不同的数据库,该怎么办?是不 ...
- tornado 07 数据库—ORM—SQLAlchemy—查询
tornado 07 数据库—ORM—SQLAlchemy—查询 引言 #上节课使用query从数据库查询到了结果,但是query返回的对象是直接可用的吗 #在query.py内输入一下内容 from ...
- 原创:mysql5 还原至mysql 8.0.11数据库链接配置提示错误(修改内容有三处
原创:mysql5 还原至mysql 8.0.11数据库链接配置提示错误改有三: a) mysql 连接jar包版修改 b)类路径修改 c)配置连接池地址修改 因版本升级,首先要修改 1:mysql- ...
- django 操作数据库--orm(object relation mapping)---models
思想 django为使用一种新的方式,即:关系对象映射(Object Relational Mapping,简称ORM). PHP:activerecord Java:Hibernate C#:Ent ...
- 数据库ORM框架GreenDao
常用的数据库: 1). Sql Server2). Access3). Oracle4). Sysbase5). MySql6). Informix7). FoxPro8). PostgreSQL9) ...
随机推荐
- linux 实时查看Tomcat日志信息
cd /../tomcat/logs 进入tomcat/logs/文件夹下 # tail -f catalina.out
- python 捕捉错误,exception,traceback和sys.exc_info()比较
import traceback,sys import requests try : requests.get('dsdsd') ##故意让他出错 except Exception,e: print ...
- GoogLeNet解读
转载:http://blog.csdn.net/shuzfan/article/details/50738394 GoogLeNet主要贡献提出了Inception结构: Architectural ...
- 8 -- 深入使用Spring -- 4...5 AOP代理:基于注解的“零配置”方式
8.4.5 基于注解的“零配置”方式 AspectJ允许使用注解定义切面.切入点和增强处理,而Spring框架则可识别并根据这些注解来生成AOP代理.Spring只是使用了和AspectJ 5 一样的 ...
- 胡思乱想 & 胡言乱语
其大无外,其小无内,在数学上是不存在的,有无穷大,又有无限逼近于0而永远不等于0 现实中,人们对事物的认知局限于科学工艺的发展,往小的方面说,在没有显微镜之前,我们能看到的最小的东西莫过于尘埃,其后认 ...
- iOS 解决UIScrollView布局问题(布局受statusBar和NavigationBar影响)
iOS APP中有一个非常好用的功能,那就是当我们在滚动一个UIScrollView滚动了很远很远的时候,假如我们想让UIScrollView回到顶部,我们绝大多数人的做法就是慢慢慢慢的滚动UIScr ...
- 【web端权限维持】利用ADS隐藏webshell
0X01 前言 未知攻,焉知防,在web端如何做手脚维护自己拿到的权限呢?首先要面临的是webshell查杀,那么通过利用ADS隐藏webshell,不失为一个好办法. 0X02 利用ADS隐藏web ...
- tomcat端口被占用的两个解决方法
tomcat 的 8080 端口经常会被占用,解决办法两个: 1.关闭占用8080端口的进程:8080端口被占用的话执行startup.bat会报错,可在cmd下执行netstat -ano命令查看8 ...
- open-falcon之agent
功能 采集数据,解析数据,上报数据至transfer 基本涵盖了系统层面监控指标,直接将数据转换为metricValue形式,上报至transfer 支持插件采集,代码插件放可受git管理,放置在pl ...
- <转>ML 相关算法参考
转自 国内外网站如果你想搜索比较新颖的机器学习资料或是文章,可以到以下网站中搜索,里面不仅包括了机器学习的内容,还有许多其它相关领域内容,如数据科学和云计算等.InfoWord:http://www. ...