Linux性能优化实战学习笔记:第五讲
一、什么是CPU的使用率
1、你最常用什么指标来描述系统的CPU性能?
我想你的答案,可能不是平均负载,也不是CPU上下文切换,而是另一个更直观的指标CPU使用率
CPU使用率到底是怎么算出来的吗?
1、如何设置节拍率
[root@luoahong ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=1000
2、内核提供的用户节拍率是多少?
USER_HZ=100
为了方便用户控件程序,内核还提供了一个用户控件的节拍率,它总是固定为100,也就是1/100秒,这样,用户控件程序并需要关系内核中HZ被设置成了多少
4、如何查看用户控件系统内部状态信息
[root@luoahong ~]# cat /proc/stat | grep ^cpu
cpu 62143 14 10857 931923 669 0 3498 0 0 0
cpu0 31506 4 5649 467020 228 0 628 0 0 0
cpu1 30637 10 5207 464903 441 0 2870 0 0 0
[root@luoahong ~]#
这里的输出结果是一个表格,其中,第一列表示的是CPU编号,如CPU0、CPU1,而第一行没有编号的CPU
表示的是所有CPU的累加
二、CPU使用率公式
我们通常所说的 CPU使用率,就是除了空闲时间外的其他时间占总CPU时间的百分比,用公式来表示就是
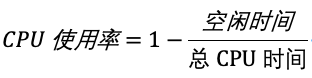
1、直接用/proc/stat 的数据,算的是什么时间段的 CPU使用率吗?
看到这里,你应该想起来了,这是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均CPU使用率,一般没啥参考价值
2、性能工具是如何计算CPU使用率的
事实上,为了计算机CPU使用率,性能能工具一般都会间隔一段时间(比如 3 秒)的两次值,做差后,再计算出这段时间的平均CPU使用率
各种性能工具所看到的CPU使用率的实际计算方法如下

性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,
你一定要保证他们用的是相同的间隔时间
三、怎么查看CPU使用率
1、top显示系统总体CPU使用情况
top显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况
# 默认每 3 秒刷新一次
$ top
top - 11:00:25 up 1:35, 2 users, load average: 0.00, 0.01, 0.18
Tasks: 131 total, 1 running, 130 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 8056848 total, 5665852 free, 688220 used, 1702776 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 6945016 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10150 polkitd 20 0 1267680 201924 9372 S 1.0 2.5 0:39.33 mysqld
9906 mysql 20 0 1119708 184904 5824 S 0.7 2.3 0:32.89 mysqld
8041 root 20 0 300896 6384 4956 S 0.3 0.1 0:28.40 vmtoolsd ...
2、top图解

3、 pidstat分析每个进程CPU使用情况
top并没有细分进程的用户态CPU和内核态CPU,那要怎么查看每个进程的详细情况呢?
# 默认每 3 秒刷新一次
$ top
top - 11:00:25 up 1:35, 2 users, load average: 0.00, 0.01, 0.18
Tasks: 131 total, 1 running, 130 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 8056848 total, 5665852 free, 688220 used, 1702776 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 6945016 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10150 polkitd 20 0 1267680 201924 9372 S 1.0 2.5 0:39.33 mysqld
9906 mysql 20 0 1119708 184904 5824 S 0.7 2.3 0:32.89 mysqld
8041 root 20 0 300896 6384 4956 S 0.3 0.1 0:28.40 vmtoolsd ...
Average: 999 10150 0.20 0.40 0.00 0.00 0.60 - mysqld
Average: 0 11747 0.40 1.59 0.00 0.00 1.98 - pidstat
4、pidstat命令图解

最后的Average部分,还计算了5组数据的平均值
四、CPU使用率过高怎么办?
1、分析思路
1、如何轻松找到CPU使用率过高的进程
通过top、ps 、pidstat等工具
2、占用CPU高的到底是代码里的那个函数?
perf和GDB
3、那么哪种工具适合在第一时间分析进程的 CPU 问题呢?
perf是Linux 2.6.31 以后内置的性能分析工具,它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析制定应用程序的性能问题
2、实时显示占用CPU时钟最多的函数
实时显示占用CPU时钟最多的函数或者指令,因此可以用来查找热点函数
[root@luoahong ~]# perf top Samples: 724 of event 'cpu-clock', Event count (approx.): 125711088
Overhead Shared Object Symbol
45.11% [kernel] [k] generic_exec_single
...
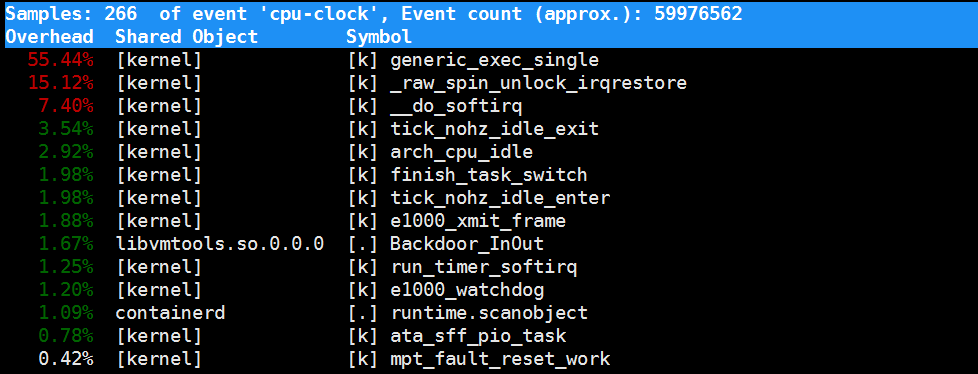
采样数需要我们特别注意,如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了
3、perf命令详解
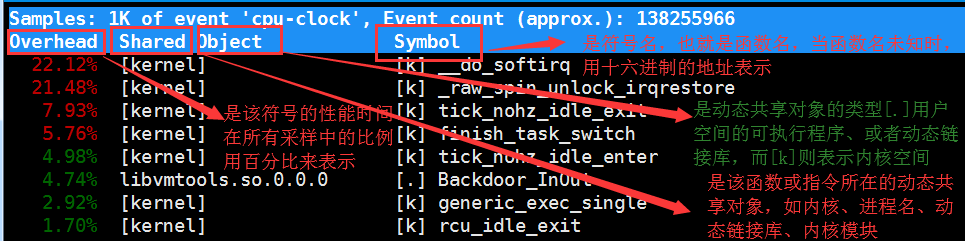
虽然实时展示了系统的性能信息,但它的缺点并不能保存数据,也就无法离线或者后续的分析,而perf record
则提供了保存数据的功能,保存后的数据,需要你用perf report解析展示
4、离线和后续分析占用CPU时钟最多的函数
perf record # 按 Ctrl+C 终止采样 [root@luoahong ~]# perf report Samples: 5K of event 'cpu-clock', Event count (approx.): 1332500000
Overhead Command Shared Object Symbol
97.15% swapper [kernel.kallsyms] [k] native_safe_halt
0.49% swapper [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.36% vmtoolsd libvmtools.so.0.0.0 [.] Backdoor_InOut
0.34% swapper [kernel.kallsyms] [k] __do_softirq
0.17% swapper [kernel.kallsyms] [k] tick_nohz_idle_exit
0.13% swapper [kernel.kallsyms] [k] tick_nohz_idle_enter
0.13% vmtoolsd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.11% kworker/0:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.11% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbOut
0.08% dockerd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.08% vmtoolsd [kernel.kallsyms] [k] __do_softirq
0.06% kworker/1:2 [kernel.kallsyms] [k] queue_delayed_work_on
0.06% vmtoolsd [kernel.kallsyms] [k] format_decode
0.04% irqbalance [kernel.kallsyms] [k] cap_mmap_file
0.04% kworker/0:0 [kernel.kallsyms] [k] ata_sff_pio_task
0.04% kworker/1:2 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.04% mysqld mysqld [.] fts_optimize_words
0.04% swapper [kernel.kallsyms] [k] rcu_idle_exit
0.04% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbIn
0.02% dockerd [kernel.kallsyms] [k] __do_softirq
0.02% in:imjournal rsyslogd [.] 0x0000000000016f90
0.02% irqbalance [kernel.kallsyms] [k] __fsnotify_parent
0.02% irqbalance [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.02% irqbalance [kernel.kallsyms] [k] copy_user_generic_unrolled
0.02% irqbalance [kernel.kallsyms] [k] native_flush_tlb_single
0.02% irqbalance [kernel.kallsyms] [k] unmap_page_range
Tip: For tracepoint events, try: perf report -s trace_fields
在实际使用中,我们还经常为perf top和perf record加上-g参数,开启调用关系的采样,方便我们根据调用链分析西能问题
Linux性能优化实战学习笔记:第五讲的更多相关文章
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第五十五讲
一.上节回顾 上一节,我们一起学习了,应用程序监控的基本思路,先简单回顾一下.应用程序的监控,可以分为指标监控和日志监控两大块. 指标监控,主要是对一定时间段内的性能指标进行测量,然后再通过时间序列的 ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
- Linux性能优化实战学习笔记:第五十八讲
一.上节回顾 专栏更新至今,咱们专栏最后一部分——综合案例模块也要告一段落了.很高兴看到你没有掉队,仍然在积极学习思考.实践操作,并热情地分享你在实际环境中,遇到过的各种性能问题的分析思路以及优化方法 ...
- Linux性能优化实战学习笔记:第十八讲
一.内存的分配和回收 1.管理内存的过程中,也很容易发生各种各样的“事故”, 对应用程序来说,动态内存的分配和回收,是既核心又复杂的一的一个逻辑功能模块.管理内存的过程中,也很容易发生各种各样的“事故 ...
- Linux性能优化实战学习笔记:第三十一讲
一.上节回顾 上一节,我们一起回顾了常见的文件系统和磁盘 I/O 性能指标,梳理了核心的 I/O 性能观测工具,最后还总结了快速分析 I/O 性能问题的思路. 虽然 I/O 的性能指标很多,相应的性能 ...
随机推荐
- 通过requirements.txt文件创建虚拟环境副本
1.首先在原来的环境中生成一个需求文件requirements.txt,用于记录所有依赖包及其精确的版本号. (venv) $ pip freeze >requirements.txt 2.创建 ...
- nginx rewrite重写规则简明笔记
nginx rewrite重写规则简明笔记 比方说http://newmiracle.cn/?p=888我要改成能这个访问http://newmiracle.cn/p888/ 首先用正则获取888 ^ ...
- windows10 启动安卓模拟器会蓝屏的解决方案
最近突然想用win10装个安卓模拟器玩游戏,然后提示vt被占用. 查了一下,了解到在windows 10 系统上,我们会用vmware,virtual box ,hyper-v,安卓模拟器,360安全 ...
- linq 大数据 sql 查询及分页优化
前提: 需要nuget PredicateLib 0.0.5: SqlServer 2008R2 (建议安装 64 位): .net 4.5 或以上: 当前电脑配置: I7 4核 3.6G ...
- Window权限维持(九):端口监视器
后台打印程序服务负责管理Windows操作系统中的打印作业.与服务的交互通过打印后台处理程序API执行,该API包含一个函数(AddMonitor),可用于安装本地端口监视器并连接配置.数据和监视器文 ...
- js函数定义及一些说明
1.javascript定义函数的三种方法一.function语句//这个方法比较常用function fn(){ alert("这是使用function语句进行函数定义");}f ...
- Flask笔记:文件上传
文件上传 enctype:在HTML中的form表单中form标签默认是`enctype="application/x-www-form-urlencoded"`,在文件上传时需要 ...
- Java生鲜电商平台-高并发的设计与架构
Java生鲜电商平台-高并发的设计与架构 说明:源码下载Java开源生鲜电商平台以及高并发的设计与架构文档 对于高并发的场景来说,比如电商类,o2o,门户,等等互联网类的项目,缓存技术是Java项目中 ...
- 原生JavaScript HTML DOM Style 对象参考
Style 对象属性 可以在Style对象上使用以下属性: “CSS”列指示定义属性的CSS版本(CSS1,CSS2或CSS3). 属性 描述 CSS alignContent 当项目不使用所有可用空 ...
- MVC中IActionFilter过滤器俄罗斯套娃的实现方式
看mvc的源码我们知道,它是在 ControllerActionInvoker 类中执行 InvokeAction 方法来实现过滤器和action方法执行的. 通过查看源码我们知道,他是通过调用 In ...