性能:Receiver层面
创建多个接收器
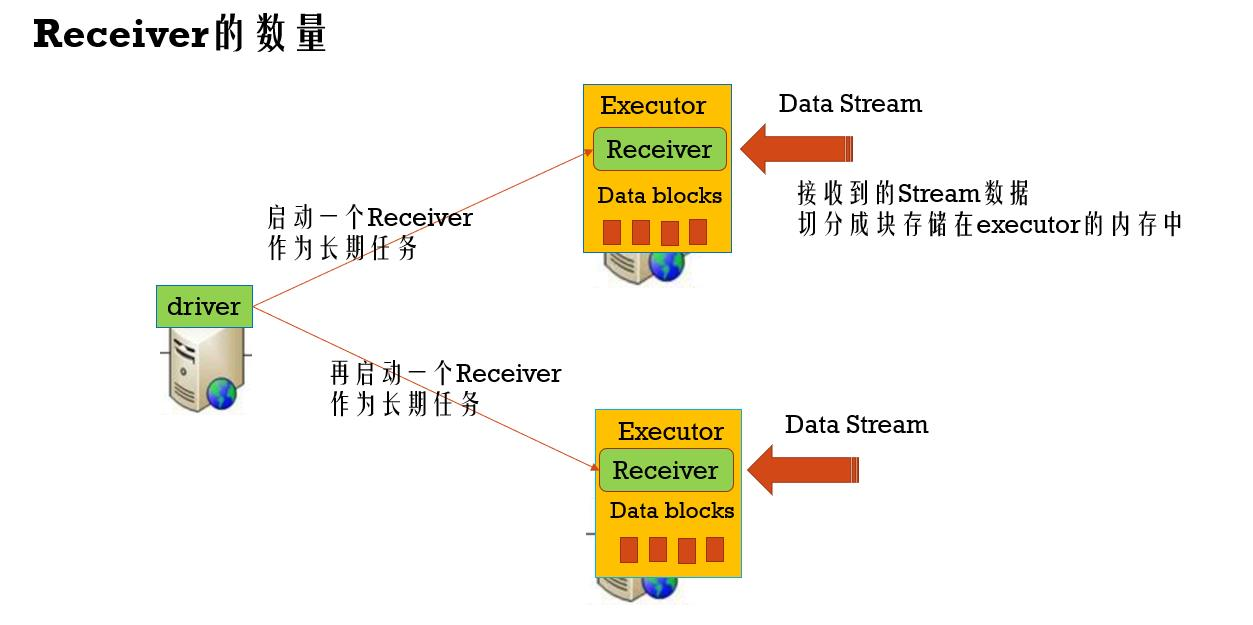
多个端口启动多个receiver在其他Executor,接收多个端口数据,在吞吐量上提高其性能。代码上:
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} /**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
* spark-submit --class com.twq.wordcount.JavaNetworkWordCount \
* --master spark://master:7077 \
* --deploy-mode client \
* --driver-memory 512m \
* --executor-memory 512m \
* --total-executor-cores 4 \
* --executor-cores 2 \
* /home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*
* spark-shell --master spark://master:7077 --total-executor-cores 4 --executor-cores 2
*/
object MultiReceiverNetworkWordCount {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf) // Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(5)) //创建多个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines1 = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER) val lines2 = ssc.socketTextStream("master", 9997, StorageLevel.MEMORY_AND_DISK_SER) val lines = lines1.union(lines2)
/////val lines = lines1.union(lines2).union(lines3)
lines.repartition(100) //处理的逻辑,就是简单的进行word count
val words = lines.repartition(100).flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10)) //将结果输出到控制台
wordCounts.print() //启动Streaming处理流
ssc.start() //等待Streaming程序终止
ssc.awaitTermination() ssc.stop(false)
}
}
Receiver数据块的数量
Receiver接受数据的速率
性能:Receiver层面的更多相关文章
- PHP 性能分析与实验——性能的宏观分析
[编者按]此前,阅读过了很多关于 PHP 性能分析的文章,不过写的都是一条一条的规则,而且,这些规则并没有上下文,也没有明确的实验来体现出这些规则的优势,同时讨论的也侧重于一些语法要点.本文就改变 P ...
- QQ会员AMS平台PHP7升级实践
作者:徐汉彬链接:https://zhuanlan.zhihu.com/p/21493018来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. QQ会员活动运营平台(AMS ...
- 日请求亿级的 QQ 会员 AMS 平台 PHP7 升级实践
QQ会员活动运营平台(AMS),是QQ会员增值运营业务的重要载体之一,承担海量活动运营的Web系统.AMS是一个主要采用PHP语言实现的活动运营平台, CGI日请求3亿左右,高峰期达到8亿.然而,在之 ...
- 日请求亿级的QQ会员AMS平台PHP7升级实践
版权声明:本文由PHP7升级项目组原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/74 来源:腾云阁 https://www ...
- 缓存中间件-Redis(二)
在上一篇中我们简单总结和介绍了Redis的几个方面 1.使用Redis背景 2.Redis通信多路复用的基本原理 3.Redis基本数据结构 4.Redis持久化方式 这一篇我们使用简单的业务场景来介 ...
- 如何从软硬件层面提升 Android 动画性能?
若是有人问如何解决动画性能不佳的问题,Dan Lew Codes 总会反问:你是否使用了硬件层? 动画放映过程中每帧画面可能都要重绘.如果使用视图层,,渲染过的视图可以存入离屏缓存以待将来重用,而无需 ...
- 性能:Transform层面
数据处理的并行度 1.BlockRDD的分区数 (1)通过Receiver接受数据的特点决定 (2)也可以自己通过repartition设置 2.ShuffleRDD的分区数 (1)默认的分区数为sp ...
- 有效提升Python代码性能的三个层面
使用python进入一个熟练的状态之后就会思考提升代码的性能,尤其是python的执行效率还有很大提升空间(委婉的说法).面对提升效率这个话题,python自身提供了很多高性能模块,很多大牛开发出了高 ...
- 前端性能优化-Vue代码层面
1.v-if 和 v-show 区分使用场景 v-if 是 真正 的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建:也是惰性的:如果在初始渲染时条件为假,则什么也不做 ...
随机推荐
- 长乐国庆集训Day5
T1 方阵 题目 [题目描述] 小澳最近迷上了考古,他发现秦始皇的兵马俑布局十分有特点,热爱钻研的小澳打算在电脑上还原这个伟大的布局. 他努力钻研,发现秦始皇布置兵马俑是有一定规律的.兵马俑阵总共有n ...
- 74HC573锁存器应用(附英文手册)
锁存器(LATCH)概念 锁存器(Latch)是一种对脉冲电平敏感的存储单元电路,它们可以在特定输入脉冲电平作用下改变状态. 锁存,就是把信号暂存以维持某种电平状态. 锁存器作用: 缓存 完成高速的控 ...
- liunx下Oracle安装
1. 引言 将近一个月没有更新博客了,最近忙着数据库数据迁移工作:自己在服务器上搭建了oracle数据库,一步步走下来遇见很多BUG:现在自己记录下,方便以后有用上的地方: 2. 准备工作 oracl ...
- 【Maven基础入门】02 了解POM文件构建
温故 上一节我们说过:Maven 是一个基于POM文件的构建工具,当然离不开POM文件 POM文件是一个XML标记语言表示的文件,文件就是:pom.xml 一个POM文件包含了项目的基本信息,用于描述 ...
- 获取当前URL地址和$_GET获取参数
用这个方法,可以在不使用$_get[]就可以获取get传过来的参数.还可以获取当前的URL public function getCurrentUrl() { $pageURL = 'http'; i ...
- oracle 数据库触发器,插入更新时间戳
1.首先建立一个测试表 CREATE TABLE TestTragger( UserId int Primary Key, Name VARCHAR() Not Null, CreateTime Ti ...
- C# vb .net实现圆角矩形特效滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的圆角矩形效果呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第 ...
- 2019 4399java面试笔试题 (含面试题解析)
本人3年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.4399等公司offer,岗位是Java后端开发,最终选择去了4399. 面试了很多家公司,感觉大部分公司考察的点 ...
- 2019 拼多多java面试笔试题 (含面试题解析)
本人3年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.拼多多等公司offer,岗位是Java后端开发,最终选择去了拼多多. 面试了很多家公司,感觉大部分公司考察的点都差 ...
- Python进阶----计算机基础知识(操作系统多道技术),进程概念, 并发概念,并行概念,多进程实现
Python进阶----计算机基础知识(操作系统多道技术),进程概念, 并发概念,并行概念,多进程实现 一丶进程基础知识 什么是程序: 程序就是一堆文件 什么是进程: 进程就是一个正在 ...