【神经网络与深度学习】【计算机视觉】SSD
SSD
背景介绍:
基于“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的结果,但是在速度方面离实时效果还比较远在提高 mAP 的同时兼顾速度,逐渐成为 Object Detection 未来的趋势。 YOLO 虽然能够达到实时的效果,但是其 mAP 与刚面提到的 state of art 的结果有很大的差距。 YOLO 有一些缺陷:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。针对
YOLO 中的这些不足,该论文提出的方法 SSD 在这两方面都有所改进,同时兼顾了 mAP 和实时性的要求。在满足实时性的条件下,接近 state of art 的结果。对于输入图像大小为 300*300 在 VOC2007 test 上能够达到 58 帧每秒( Titan X 的 GPU ),72.1% 的 mAP。输入图像大小为 500 *500 , mAP 能够达到 75.1%。作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。
关键点:
关键点1:网络结构
该论文采用 VGG16 的基础网络结构,使用前面的前 5 层,然后利用 astrous 算法将 fc6 和 fc7 层转化成两个卷积层。再格外增加了 3 个卷积层,和一个 average pool层。不同层次的 feature map 分别用于 default box 的偏移以及不同类别得分的预测(惯用思路:使用通用的结构(如前 5个conv 等)作为基础网络,然后在这个基础上增加其他的层),最后通过 nms得到最终的检测结果。
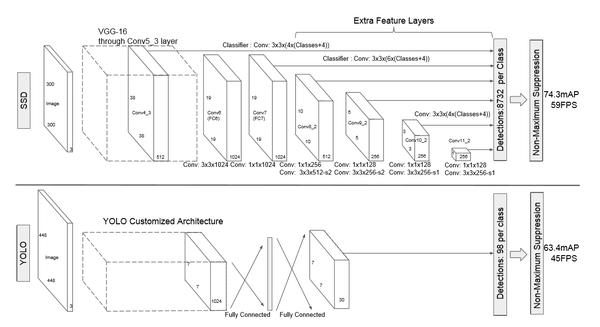
这些增加的卷积层的 feature map 的大小变化比较大,允许能够检测出不同尺度下的物体: 在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。观察YOLO,后面存在两个全连接层,全连接层以后,每一个输出都会观察到整幅图像,并不是很合理。但是SSD去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的feature
map,预测不同宽高比的图像,这样比YOLO增加了预测更多的比例的box。(下图横向的流程)
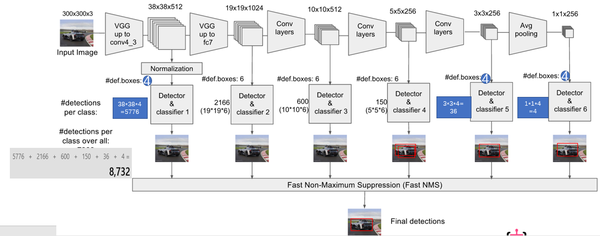
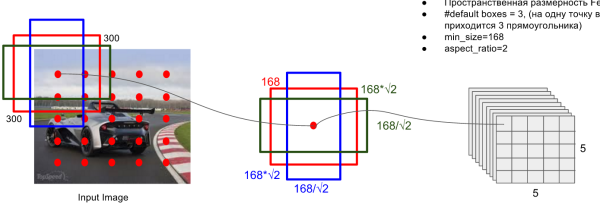
关键点2:多尺度feature map得到 default boxs及其 4个位置偏移和21个类别置信度
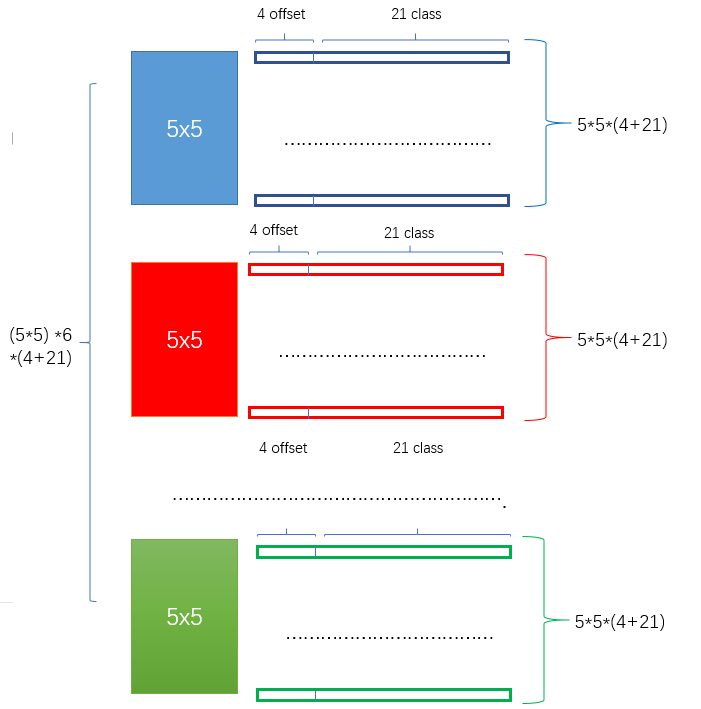
对于不同尺度feature map( 上图中 38x38x512,19x19x512, 10x10x512, 5x5x512, 3x3x512, 1x1x256) 的上的所有特征点: 以5x5x256为例 它的#defalut_boxes = 6
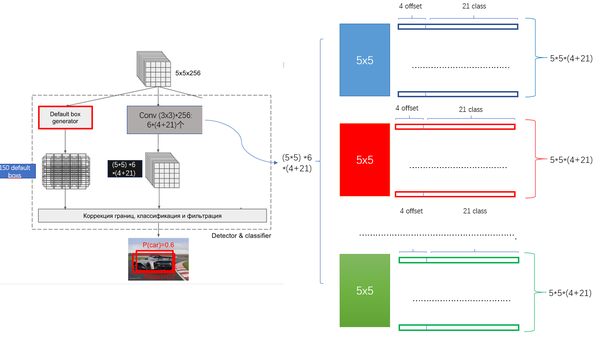
- 1 按照不同的 scale 和 ratio 生成,k 个 default boxes,这种结构有点类似于 Faster R-CNN 中的 Anchor。(此处k=6所以:5*5*6 = 150 boxes)
- 2 新增加的每个卷积层的 feature map 都会通过一些小的卷积核操作,得到每一个 default boxes 关于物体类别的21个置信度 (
20个类别和1个背景)
和4偏移 (shape offsets) 。- 假设feature map 通道数为 p 卷积核大小统一为 3*3*p (此处p=256)。个人猜想作者为了使得卷积后的feature map与输入尺度保持一致必然有 padding = 1, stride = 1 :
- 假如feature map 的size 为 m*n, 通道数为 p,使用的卷积核大小为 3*3*p。每个 feature map 上的每个特征点对应 k 个 default boxes,物体的类别数为 c,那么一个feature map就需要使用 k(c+4)个这样的卷积滤波器,最后有 (m*n) *k* (c+4)个输出。
- 假设feature map 通道数为 p 卷积核大小统一为 3*3*p (此处p=256)。个人猜想作者为了使得卷积后的feature map与输入尺度保持一致必然有 padding = 1, stride = 1 :
训练策略
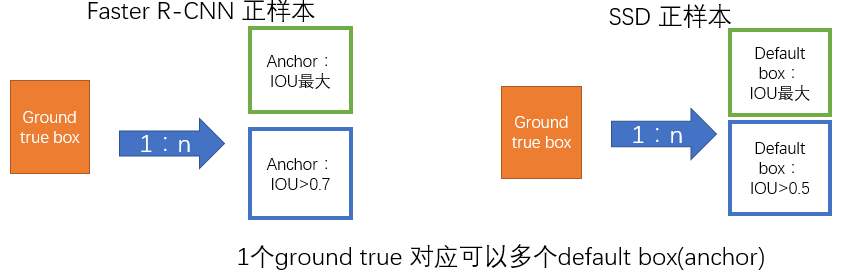
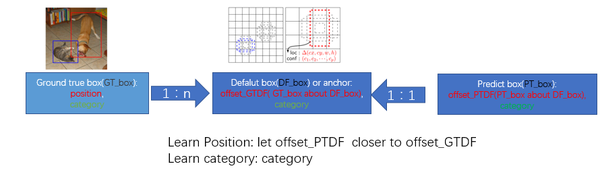
监督学习的训练关键是人工标注的label。对于包含default box(在Faster R-CNN中叫做anchor)的网络模型(如: YOLO,Faster R-CNN, MultiBox)关键点就是如何把 标注信息(ground true box,ground true category)映射到(default box上)
- 正负样本: 给定输入图像以及每个物体的 ground truth,首先找到每个ground true box对应的default box中IOU最大的作为(与该ground true box相关的匹配)正样本。然后,在剩下的default box中找到那些与任意一个ground truth box 的 IOU 大于 0.5的default box作为(与该ground true box相关的匹配)正样本。 一个 ground truth 可能对应多个 正样本default box 而不再像MultiBox那样只取一个IOU最大的default
box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。下图的例子是:给定输入图像及 ground truth,分别在两种不同尺度(feature map 的大小为 8*8,4*4)下的匹配情况。有两个 default box 与猫匹配(8*8),一个 default box 与狗匹配(4*4)。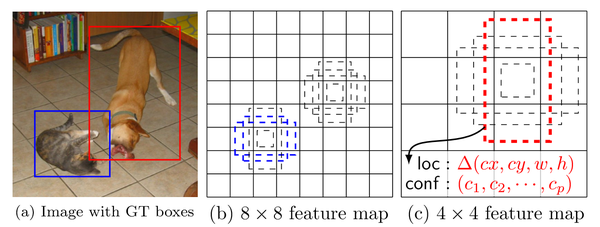
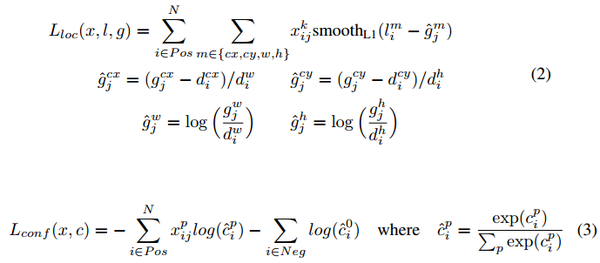
冲量为 0.9,权重衰减为 0.0005,batchsize 为 32。不同数据集的学习率改变策略不同。新增加的卷积网络采用 xavier 的方式进行初始化
在预测阶段,直接预测每个 default box 的偏移以及对于每个类别相应的得分。最后通过 nms 的方式得到最后检测结果。
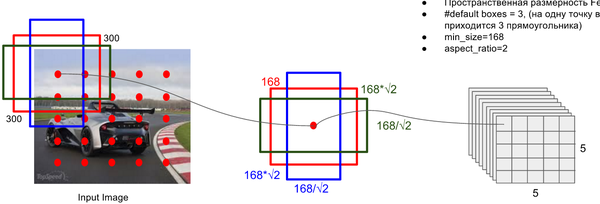
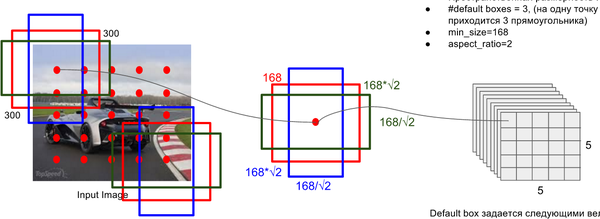
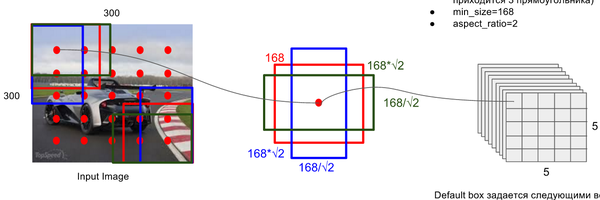
Default Box 的生成:
该论文中利用不同层的 feature map 来模仿学习不同尺度下物体的检测。
- scale: 假定使用 m 个不同层的feature map 来做预测,最底层的 feature map 的 scale 值为
,最高层的为
,其他层通过下面公式计算得到
- ratio: 使用不同的 ratio值
计算
default box 的宽度和高度:,
。另外对于
ratio = 1 的情况,额外再指定 scale 为也就是总共有
6 中不同的 default box。 - default box中心:上每个 default box的中心位置设置成
,其中
表示第k个特征图的大小
。
Hard Negative Mining:
用于预测的 feature map 上的每个点都对应有 6 个不同的 default box,绝大部分的 default box 都是负样本,导致了正负样本不平衡。在训练过程中,采用了 Hard Negative Mining 的策略(根据confidence loss对所有的box进行排序,使正负例的比例保持在1:3) 来平衡正负样本的比率。这样做能提高4%左右。
Data augmentation
为了模型更加鲁棒,需要使用不同尺寸的输入和形状,作者对数据进行了如下方式的随机采样:
- 使用整张图片
- 使用IOU和目标物体为0.1, 0.3,0.5, 0.7, 0.9的patch (这些 patch 在原图的大小的 [0.1,1] 之间, 相应的宽高比在[1/2,2]之间)
- 随机采取一个patch
当 ground truth box 的 中心(center)在采样的 patch 中时,我们保留重叠部分。在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的 水平翻转(horizontally flipped)。用数据增益通过实验证明,能够将数据mAP增加8.8%。
参考:
【神经网络与深度学习】【计算机视觉】SSD的更多相关文章
- [神经网络与深度学习][计算机视觉]SSD编译时遇到了json_parser_read.hpp:257:264: error: ‘type name’ declared as function ret
运行make之后出现如下错误: /usr/include/boost/property_tree/detail/json_parser_read.hpp:257:264: error: 'type n ...
- (转)神经网络和深度学习简史(第一部分):从感知机到BP算法
深度|神经网络和深度学习简史(第一部分):从感知机到BP算法 2016-01-23 机器之心 来自Andrey Kurenkov 作者:Andrey Kurenkov 机器之心编译出品 参与:chen ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验【中英】
[中英][吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第二周测验 第2周测验 - 神经网络基础 神经元节点计算什么? [ ]神经元节点先计算激活函数,再计算线性函数(z = Wx + ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验【中英】
[吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第一周测验[中英] 第一周测验 - 深度学习简介 和“AI是新电力”相类似的说法是什么? [ ]AI为我们的家庭和办公室的个人设备供电 ...
- 对比《动手学深度学习》 PDF代码+《神经网络与深度学习 》PDF
随着AlphaGo与李世石大战的落幕,人工智能成为话题焦点.AlphaGo背后的工作原理"深度学习"也跳入大众的视野.什么是深度学习,什么是神经网络,为何一段程序在精密的围棋大赛中 ...
- 如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?
如何理解归一化(Normalization)对于神经网络(深度学习)的帮助? 作者:知乎用户链接:https://www.zhihu.com/question/326034346/answer/730 ...
- 【神经网络与深度学习】卷积神经网络(CNN)
[神经网络与深度学习]卷积神经网络(CNN) 标签:[神经网络与深度学习] 实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次. 说明:以后的总结,还应该以我的认识进行总结,这样比较符合 ...
- 【神经网络与深度学习】【CUDA开发】caffe-windows win32下的编译尝试
[神经网络与深度学习][CUDA开发]caffe-windows win32下的编译尝试 标签:[神经网络与深度学习] [CUDA开发] 主要是在开发Qt的应用程序时,需要的是有一个使用的库文件也只是 ...
- 【神经网络与深度学习】【Matlab开发】caffe-windows使能Matlab2015b接口
[神经网络与深度学习][Matlab开发]caffe-windows使能Matlab2015b接口 标签:[神经网络与深度学习] [Matlab开发] 主要是想全部来一次,所以使能了Matlab的接口 ...
随机推荐
- JQuery DOM操作(属性操作/样式操作/文档过滤)
jQuery——入门(三)JQuery DOM操作(属性操作/样式操作/文档过滤) 一.DOM属性操作 1.属性 (1).attr() 方法 语法:$(selector).attr(name|prop ...
- git merge与git rebase区别(转载)
这是最近看的讲的比较通俗易懂的rebase与merge的区别了 https://www.jianshu.com/p/4079284dd970
- NOIP 2018 考前须知
Day0Day0Day0来水一发 Created with Raphaël 2.2.0开始考试浏览题面(3遍),注意数据范围初步判定难度,先易后难15分钟左右想正解实在想吃不出写暴力,NOIP部分分很 ...
- (尚025)Vue_案例_静态组件
页面效果展示截图: 第一步.首先拆分组件 (1).首先看一下是上下/左右结构 确定为:输入框+列表+底部; (2).确定名字 (3).创建对应的组件 ========================= ...
- C# 读取Excel 单元格是日期格式
原文地址:https://www.cnblogs.com/liu-xia/p/5230768.html DateTime.FromOADate(double.Parse(range.Value2.To ...
- 1-开发共享版APP(接入指南)-APP说明
该APP的功能,类似于网上售卖的Wi-Fi/GPRS远程控制器 设备页面 用户页面 ...
- Cogs 739. [网络流24题] 运输问题(费用流)
[网络流24题] 运输问题 ★★ 输入文件:tran.in 输出文件:tran.out 简单对比 时间限制:1 s 内存限制:128 MB «问题描述: «编程任务: 对于给定的m 个仓库和n 个零售 ...
- 这里是DDOSvoid的blog
由于博主已经退役,博客现由 @一扶苏一 代为维护. DDOSvoid 在生前退役前写下了大量的 blog 存在本地,现在由他的弟子 一扶苏一 整理编纂成为题单慢慢上传,是为<论语>< ...
- HEXO快速搭建自己的博客
关注我,每天都有优质技术文章推送,工作,学习累了的时候放松一下自己. 本篇文章同步微信公众号 欢迎大家关注我的微信公众号:「醉翁猫咪」 很多人有自己的博客,那么你想要吗?利用Hexo就可以搭建专属自己 ...
- 升级pip3的正确姿势--python3 pip3 update
升级pip3的正确姿势为: pip3 install --upgrade pip 而不是 pip3 install --upgrade pip3