ubuntu之路——day17.3 简单的CNN和CNN的常用结构池化层

来看上图的简单CNN:
从39x39x3的原始图像 不填充且步长为1的情况下经过3x3的10个filter卷积后 得到了
37x37x10的数据 不填充且步长为2的情况下经过5x5的20个filter卷积后 得到了
17x17x20的数据 不填充且步长为2的情况下经过5x5的40个filter卷积后 得到了
7x7x40的最终结果
将7x7x40的卷积层全部展开作为输入特征,建立一个输入层单元数为1960的神经网络即可
卷积神经网络常见的结构:
1.Conv卷积层如上图所见
2.Pool池化层
3.FullyConnected全连接层
Pooling layer 池化层:
池化层的作用:缩减模型大小,提高计算速度,增强提取特征的鲁棒性
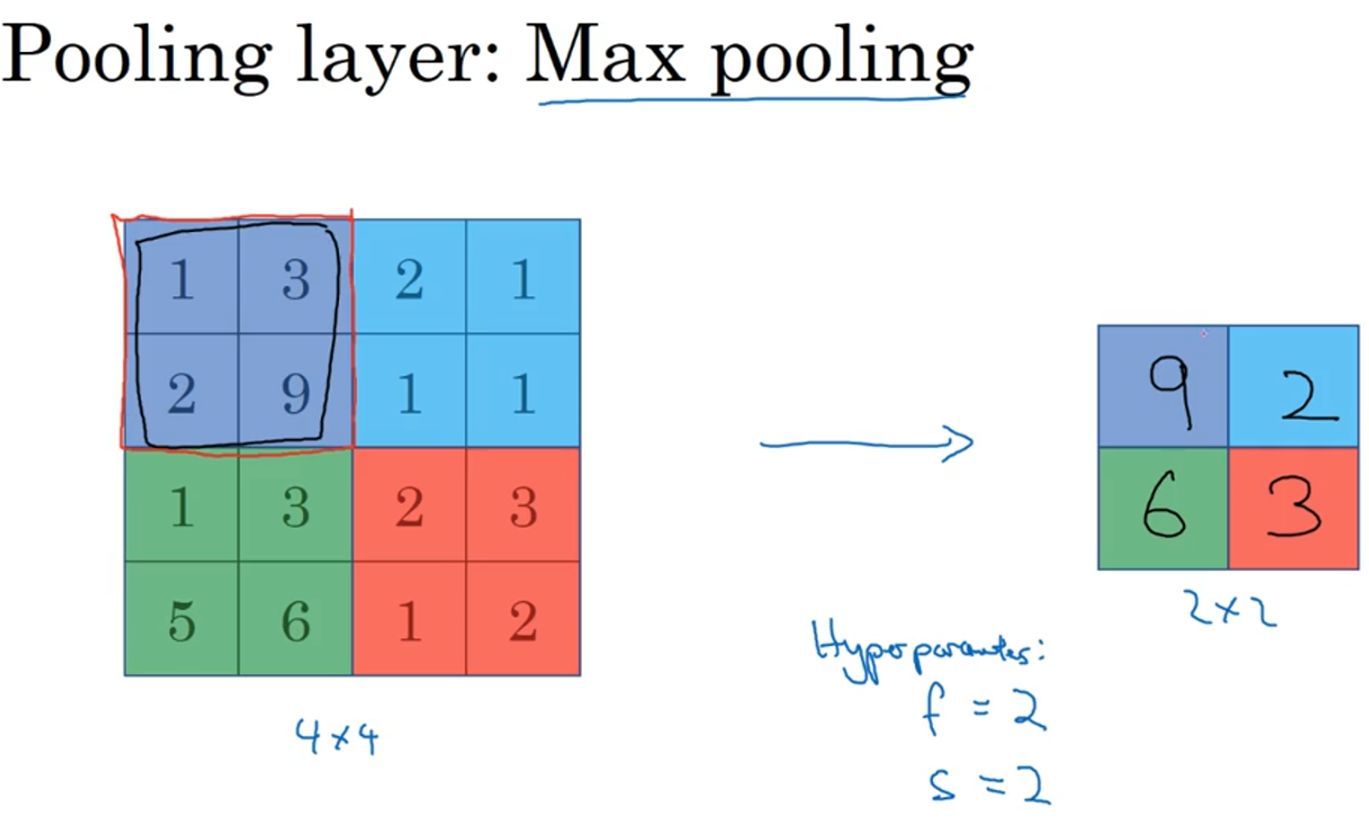
最大池化层,顾名思义,就是把每次filter的卷积过程换为对区域内的所有数字求最大值的过程,如上图所示,在指定filter大小和步长s后可以得到最终的结果为2x2,然后每次求不同区域内的最大值即可。
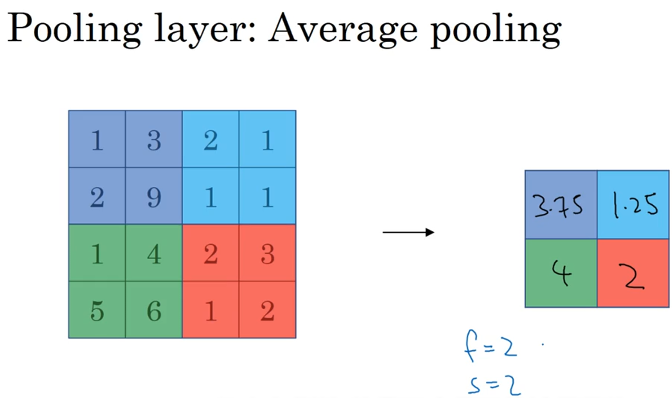
平均池化层,这种池化层的应用要比最大池化层少。一般应用于很深的网络中,比如上浅层的信道层的网络等,原理与最大池化层相同,只是每次对filter的区域求平均值。
注意:
一般而言,池化层的超参数只有filter的大小f和步长s,在池化层中一般不用填充padding,因此p一般为0。
堆叠的池化层操作与卷积操作相同,对每个信道单独求max/average然后堆叠即可。
ubuntu之路——day17.3 简单的CNN和CNN的常用结构池化层的更多相关文章
- ubuntu之路——day17.4 卷积神经网络示例
以上是一个识别手写数字的示例 在这个示例中使用了两个卷积-池化层,三个全连接层和最后的softmax输出层 一般而言,CNN的构成就是由数个卷积层紧跟池化层再加上数个全连接层和输出层来构建网络. 在上 ...
- CNN中卷积层 池化层反向传播
参考:https://blog.csdn.net/kyang624823/article/details/78633897 卷积层 池化层反向传播: 1,CNN的前向传播 a)对于卷积层,卷积核与输入 ...
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- CNN学习笔记:池化层
CNN学习笔记:池化层 池化 池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样.有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见 ...
- 深入解析CNN pooling 池化层原理及其作用
原文地址:https://blog.csdn.net/CVSvsvsvsvs/article/details/90477062 池化层作用机理我们以最简单的最常用的max pooling最大池化层为例 ...
- tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图
tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图 因为很多 demo 都比较复杂,专门抽出这两个函数,写的 demo. 更多教程:http://www.tensorflown ...
- ubuntu之路——day17.1 用np.pad做padding
网上对np.pad的解释很玄乎,举的例子也不够直观,看了更晕了,对于CNN的填充请参考下面就够用了: np.pad的参数依次是目标数组,多增加的维数可以理解为一张图的前后左右增加几圈,设置为'cons ...
- ubuntu之路——day17.2 RGB图像的卷积、多个filter的输出、单个卷积层的标记方法
和单层图像的卷积类似,只需要对每一个filter构成的三层立方体上的每一个数字与原图像对应位置的数字相乘相加求和即可. 在这个时候可以分别设置filter的R.G.B三层,可以同时检测纵向或横向边缘, ...
- ubuntu之路——day17.1 卷积操作的意义、边缘检测的示例、filter与padding的关系、卷积步长
感谢吴恩达老师的公开课,以下图片均来自于吴恩达老师的公开课课件 为什么要进行卷积操作? 我们通过前几天的实验已经做了64*64大小的猫图片的识别. 在普通的神经网络上我们在输入层上输入的数据X的维数为 ...
随机推荐
- js中 !==和 !=的区别是什么
1.比较结果上的区别 !=返回同类型值比较结果. !== 不同类型不比较,且无结果,同类型才比较. 2.比较过程上的区别 != 比较时,若类型不同,会偿试转换类型. !== 只有相同类型才会比较. 3 ...
- 19、localStorage.getItem得到的是[object Object] 的解决方案
实现本地存储,避免刷新页面数据丢失: localStorage.setItem 只能存储字符串, 所以在储存的时候先将对象转换为字符串 localStorage.setItem("local ...
- vavr:让你像写Scala一样写Java
本文阅读时间大约7分钟. Hystrix是Netflix开源的限流.熔断降级组件,去年发现Hystrix已经不再更新了,而在github主页上将我引导到了另一个替代项目--resilience4j,这 ...
- Java集合学习(6):LinkedHashSet
一.概述 首先我们需要知道的是它是一个Set的实现,所以它其中存的肯定不是键值对,而是值.此实现与HashSet的不同之处在于,LinkedHashSet维护着一个运行于所有条目的双重链接列表.此链接 ...
- Could not get lock /var/lib/dpkg/lock-frontend解决
在安装软件包时如果出现Could not get lock /var/lib/dpkg/lock-frontend,说明之前使用apt时出现异常,没有正常关闭,还在运行. lgj@lgj-Lenovo ...
- JAVA自定义查询策略
此文章为个人笔记,考虑之后工作用到,博客方便于查找,如果可以给他人提供参考价值,那再好不过 1.定义查询接口参数 package com.qy.code.generator.query; import ...
- 《linux就该这么学》课堂笔记11 LVM、防火墙初识
1.常用的LVM部署命令 功能/命令 物理卷管理 卷组管理 逻辑卷管理 扫描 pvscan vgscan lvscan 建立 pvcreate vgcreate lvcreate 显示 pvdispl ...
- Markdown Mermaid
Mermaid 是一个用于画流程图.状态图.时序图.甘特图的库,使用 JS 进行本地渲染,广泛集成于许多 Markdown 编辑器中. 之前用过 PlantUML,但是发现这个东西的实现原理是生成 U ...
- Pytorch autograd,backward详解
平常都是无脑使用backward,每次看到别人的代码里使用诸如autograd.grad这种方法的时候就有点抵触,今天花了点时间了解了一下原理,写下笔记以供以后参考.以下笔记基于Pytorch1.0 ...
- php原型模式(prototype pattern)
练练练,计划上午练完创建型设计模式. <?php /* The prototype pattern replicates other objects by use of cloning. Wha ...