SQL进阶-索引设置&sql优化
一、索引设置
1、索引的设置原则
经常出现在WHERE条件、关联条件中的字段作为索引字段; 在满足查询需求的前提下,应尽可能少的创建索引;(对于一个组合索引,可以满足以组合索引左边的一部分字段的查询需求); 经常更新的字段,不适合创建索引; 区分度太低的字段,不适合创建索引; 不要为永远不会出现在WHERE条件、关联条件中的字段创建索引;
2、案例分析
比如有下面一张表:
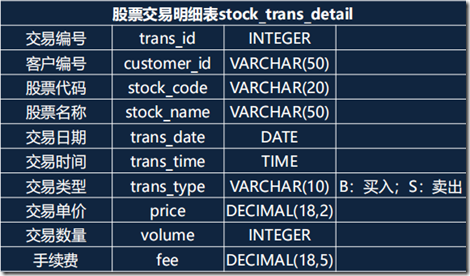
查询需求如下:
需求一:按单个客户编号查询某个客户的交易明细。 需求二:按单个客户编号查询某个时间段的某只股票的交易明细。 需求三:统计某个时间段每只股票不同交易类型的交易金额。 需求四:统计每天所有股票的交易金额。 需求五:统计每只股票所有的交易费用。 查询一:SELECT * FROM stock_trans_detail WHERE customer_id = '?'; 查询二:SELECT * FROM stock_trans_detail WHERE customer_id = '?' AND trans_date BETWEEN '2020-01-01' AND '2020-12-31' AND stock_code = '?'; 查询三:SELECT stock_code,trans_type,sum(price*volume) FROM stock_trans_detail WHERE trans_date BETWEEN '2020-01-01' AND '2020-12-31' GROUP BY stock_code,trans_type; 查询四:SELECT trans_date,sum(price*volume) FROM stock_trans_detail GROUP BY trans_date; 查询五:SELECT stock_code,sum(fee) FROM stock_trans_detail GROUP BY stock_code;
索引设置分析:
需求一:按单个客户编号查询某个客户的交易明细。
需求二:按单个客户编号查询某个时间段的某只股票的交易明细。
需求三:统计某个时间段每只股票不同交易类型的交易金额。
需求四:统计每天所有股票的交易金额。
需求五:统计每只股票所有的交易费用。 索引一:customer_id
索引二:customer_id,trans_date,stock_code
索引三:trans_date,stock_code
索引四:无
索引五:无 最终:
索引一:customer_id,trans_date,stock_code
索引二:trans_date,stock_code
二、SQL优化
1、SQL优化的五个层次
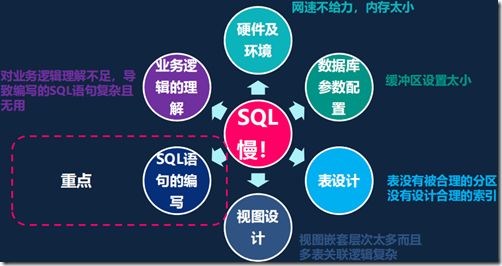
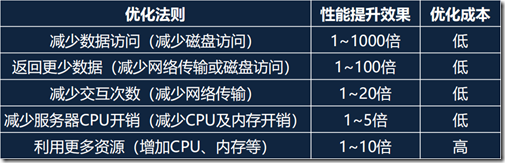
主键 –> 唯一索引 –> 非唯一索引 –> 全表扫描(应尽量避免)
2、SQL优化的15条铁律
铁律1:尽量避免在索引列上使用表达式
如:
SELECT * FROM score WHERE score / 100 >= 0.6;
转换为:
SELECT * FROM score WHERE score >= 0.6 * 100; SELECT * FROM score WHERE LEFT(student_id,1) = 'S';
转换为:
SELECT * FROM score WHERE student_id LIKE 'S%';
铁律2:尽量避免在WHERE条件中使用NOT、<>和!=操作符
如:
SELECT * FROM score WHERE score <> 50;
转换为:
SELECT * FROM score WHERE score > 50 OR score < 50;
或
SELECT * FROM score WHERE score > 50;
UNION ALL
SELECT * FROM score WHERE score < 50;
铁律3:避免索引列的隐式类型转换
如:
SELECT * FROM stock_trans_detail WHERE stock_code = 600001;
转换为:
SELECT * FROM stock_trans_detail WHERE stock_code = '600001';
铁律4:在OR的两个条件上都有索引的话,将OR转换为UNION或UNION ALL
如:
SELECT * FROM score WHERE score = 100 OR gender = '男';
转换为:
SELECT * FROM score WHERE score = 100
UNION
SELECT * FROM score WHERE gender = '男';
铁律5:使用IN操作符替换OR
如:
SELECT * FROM score WHERE score = 100 OR score = 99;
转换为:
SELECT * FROM score WHERE score IN (100,99);
铁律6:使用BETWEEN操作符替换IN
如:
SELECT * FROM score WHERE score IN (100,99,98,97,96,95);
转换为:
SELECT * FROM score WHERE score BETWEEN 95 AND 100;
铁律7:在合适的情况下,使用EXISTS操作符替换IN
如:
SELECT * FROM stock
WHERE stock_code IN (
SELECT stock_code FROM stock_trans_detail
WHERE trans_date BETWEEN '2020-01-01' AND '2020-12-31'
);
转换为:
SELECT * FROM stock a
WHERE EXISTS (
SELECT 1 FROM stock_trans_detail b
WHERE a.stock_code = b.stock_code
AND b.trans_date BETWEEN '2020-01-01' AND '2020-12-31'
); 子查询结果集较大时,适合用EXISTS;
子查询结果集较小时,适合用IN;
铁律8:LIKE通配符也可能导致索引失效
如:
SELECT * FROM score WHERE subject_name LIKE '%机%';
转换为:
SELECT * FROM score WHERE subject_name LIKE '机%'
UNION ALL
SELECT * FROM score WHERE subject_name LIKE '计算机%';
或
SELECT * FROM score
WHERE subject_name IN ('机械原理','计算机导论');
铁律9:索引中不包含NULL值,所以使用IS NULL、IS NOT NULL做判断的条件,都用不到索引
解决方法:应该将数据库中的所有字段都设置为不可为NULL,且针对不同的数据类型设置默认值。
比如,对于INT类型的字段,如果为NULL,则设为默认值0。这样就可以将IS NULL的判断,转换为与0相等的判断。 如:
SELECT * FROM score WHERE score IS NULL;
转换为:
SELECT * FROM score WHERE score = 0;
铁律10: INT型字段中,应该使用>=替换>
如:
SELECT * FROM student WHERE age > 15;
转换为:
SELECT * FROM student WHERE age >= 16;
铁律11: 在多个结果集不交叉的情况下,使用UNION ALL替换UNION
如:
SELECT * FROM score WHERE score = 100
UNION
SELECT * FROM score WHERE score = 99;
转换为:
SELECT * FROM score WHERE score = 100
UNION ALL
SELECT * FROM score WHERE score = 99;
铁律12: 优化GROUP BY子句
如:
SELECT trans_date,stock_code,sum(volume)
FROM stock_trans_detail
GROUP BY trans_date,
CASE WHEN trans_type = 'B' THEN '买入' WHEN trans_type = 'S' then '卖出'
ELSE '' END
HAVING trans_date BETWEEN '2020-01-01' AND '2020-12-31';
转换为:
SELECT trans_date,
CASE WHEN trans_type = 'B' THEN '买入' WHEN trans_type = 'S' then '卖出'
ELSE '' END, SUM(volume)
FROM stock_trans_detail
WHERE trans_date BETWEEN '2020-01-01' AND '2020-12-31'
GROUP BY trans_date,trans_type;
铁律13: 使用ORDER BY配合LIMIT分页查询
如:
当LIMIT的偏移量特别大时,效率会非常低
SELECT * FROM score LIMIT 1000,10 效率高
SELECT * FROM score LIMIT 100000,10 效率低
转换为:
SELECT * FROM score ORDER BY student_id LIMIT 100000,10;
铁律14: 避免不合理的DISTINCT
由于DISTINCT去重功能的限制,实际开发过程中使用到DISTINCT的情况很少。如果发现结果集有重复而需要使用DISTINCT去重,
则很可能是因为对业务逻辑理解不足导致的SQL语句的编写问题。 如:
SELECT DISTINCT a.stock_code,a.stock_name
FROM stock a
INNER JOIN stock_trans_detail b
ON a.stock_code = b.stock_code
AND b.trans_date BETWEEN '2020-01-01' AND '2020-12-31‘;
转换为:
SELECT a.stock_code,a.stock_name FROM stock a
WHERE EXISTS (
SELECT 1 FROM stock_trans_detail b
WHERE a.stock_code = b.stock_code
AND b.trans_date BETWEEN '2020-01-01' AND '2020-12-31');
铁律15: 不要把SQL语句写的太冗长
合理使用临时表,而不是想着一个SQL解决所有问题。如果一个SQL关联的表超过5张,就应该考虑拆分。
SQL进阶-索引设置&sql优化的更多相关文章
- 「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
大家好,我是melo,一名大三后台练习生 专栏回顾 索引的原理&&设计原则 欢迎关注本专栏:MySQL高级篇 本篇速览 在我们上一篇文章中,讲到了索引的原理&&设计原则 ...
- 面试题: mysql 数据库已看 sql安全性 索引 引擎 sql优化
总结的一些MySQL数据库面试题 2016年06月16日 11:41:18 阅读数:4950 一.sql语句应该考虑哪些安全性? (1)防止sql注入,对特殊字符进行转义,过滤或者使用预编译的sql语 ...
- SQL Server 索引维护sql语句
使用以下脚本查看数据库索引碎片的大小情况: 复制代码代码如下: DBCC SHOWCONTIG WITH FAST, TABLERESULTS, ALL_INDEXES, NO_INFOMSGS 以 ...
- SQL Server2005索引碎片分析和解决方法
SQL Server2005索引碎片分析和解决方法 本文作者(郑贤娴),请您在阅读本文时尊重作者版权. 摘要: SQL Server,为了反应数据的更新,需要维护表上的索引,因而这些索引会形成碎片.根 ...
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
- SQL优化的四个方面,缓存,表结构,索引,SQL语句
一,缓存 数据库属于 IO 密集型的应用程序,其主要职责就是数据的管理及存储工作.而我们知道,从内存中读取一个数据库的时间是微秒级别,而从一块普通硬盘上读取一个IO是在毫秒级别,二者相差3个数量级.所 ...
- SQL Server索引进阶:第十三级,插入,更新,删除
在第十级到十二级中,我们看了索引的内部结构,以及改变结构造成的影响.在本文中,继续查看Insert,update,delete和merge造成的影响.首先,我们单独看一下这四个命令. 插入INSERT ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- SQL Server索引进阶:第五级,包含列
原文地址: Stairway to SQL Server Indexes: Level 5, Included Columns 本文是SQL Server索引进阶系列(Stairway to SQL ...
随机推荐
- Unable to connect to HBase using Phoenix JDBC Driver
Feb 01, 2017; 5:21pm Unable to connect to HBase using Phoenix JDBC Driver 9 posts Hi All, I am try ...
- MVC学习笔记(六)---遇到的小问题汇总
一.MVC中Controller中返回两个对象的写法如下: , msg = "成功", user = user, userInfo = person }); 二.前台向后台传入带有 ...
- Ubuntu 下安装zsh和oh-my-zsh
注意:安装前先备份/etc/passwd 一开始装oh-my-zsh我是拒绝的,因为这东西安装容易,卸载难,真的很难. Mac安装参考:http://www.cnblogs.com/EasonJim/ ...
- Spring MVC 复习
概念 三层架构 将整个业务应用划分为三层 表现层:用来和客户端进行数据交互,一般采用MVC设计模式 业务层:处理公司具体业务逻辑 持久层:用来操作数据库 MVC模型 Model View ...
- 【转载】C#如何获取DataTable中某列的数据类型
在C#的数据表格DataTable的操作中,有时候因为业务需要,我们需要获取到DataTable所有列或者某一列的数据类型,此时我们可以通过DataTable中的Columns属性对象的DataTyp ...
- Typora优化-适合不懂CSS代码的小白
转载请注明出处:https://www.cnblogs.com/nreg/p/11116176.html 先来一张优化前与优化后的对比图: 优化前: 优化后: 1.通过 文件-偏好设置 打开主题文件 ...
- JavaScript 函数(二)
一.匿名函数 1.匿名函数 没有名字的函数即称为匿名函数. 2.使用方法 a.将匿名函数赋值给一个变量,这样就可以通过变量进行调用 b.匿名函数自调用 3.关于自执行函数(匿名函数自调用)的作用:防止 ...
- JavaScript 获取页面元素
一.根据 id 获取元素 语法格式: document.getElementById(id); Demo: var main = document.getElementById('main'); co ...
- android中activity和service是否在同一个进程中
分两种情况,如果是本地线程,肯定是同一个进程中的, 如果是远程服务,那么activity和service将在不同的进程中的 ----- 非远程服务,和Activity属于同一个进程和线程:而远程服务和 ...
- Ansible-ansible命令
Ansible是用于执行"远程操作"的简单工具.该命令允许针对一组主机定义并运行单个任务剧本. 常用选项 说明 --ask-vault-pass 请求保险库密码 --become- ...