mysql的innodb数据存储结构
数据库磁盘读取与系统磁盘读取
1,系统从磁盘中读取数据到内存时是以磁盘块(block)为基本单位,位于同一个磁盘块中的数据会被一次性读取出来。
2,innodb存储引擎中有页(Page)的概念,页是数据库管理磁盘的最小单位,innodb存储引擎中默认每个页的大小为16kb,每次读取磁盘时都将页载入内存中。
3,系统一个磁盘块的大小空间往往没有16kb这么大,因此innodb每次io操作时都会将若干个地址连续的磁盘块的数据读入内存,从而实现整页读入内存
问题:数据库的数据结构时怎样的?B树和B+树有什么区别,为什么选择B+树作为存储数据的结构,而不是B树?
B树和B+树
Btree
一个M阶的B-tree有如下特点
1,每个节点最多有m个孩子(分叉),
2,除了根节点和叶子节点外,其他每个节点至少有ceil(m/2)个孩子
3,若根节点不是叶子节点,则至少有两个孩子
4,所有叶子节点都再同一层,且不包含其他关键字信息
5,每个非终端节点包含n个关键字信息,关键字的个数n满足ceil(m/2)-1<=n<= m-1 其中m为阶数
6,ki(i=1,…n)为关键字,且关键字(主键primary key)升序排序。
7,. Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1);
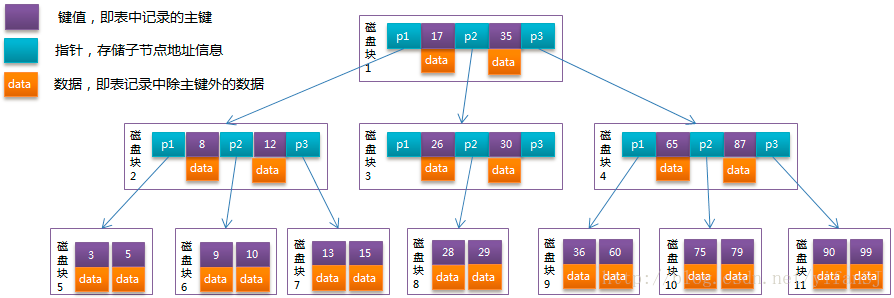
B-tree每个节点都包含指针,key以及data,每个节点含有三个指向子节点的指针和两个升序排序的关键字(key)
模拟查找关键字29的过程:
1. 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
2. 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
3. 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
4. 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
5. 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
6. 在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。
B树上大部分的操作(插入、删除、查询)所需要的磁盘存取次数和B树的高度是成正比的,并且B树是尽量多的在节点上存储信息,保证导数尽量少,在B树中可以检查多个子结点,由于在一棵树中检查任意一个结点都需要一次磁盘访问,所以B树避免了大量的磁盘访问,减少了磁盘I/O。
B+tree
毫无疑问,减少树的高度是有效减少IO次数提高效率的方式,b-tree结构每个节点不仅包含key值,还有data值,每一个页的存储(16kb)是有限的,每个节点可容纳的指针和keydata是有,如果data数据含量大,那么一个页保存的指针和key的数量就会减少,从而增页节点的数量,这就增加btree的深度,增加读取磁盘的次数,进而影响查询效率
而在b+tree中,一个节点记录的都是key值和指针(排除了data值),这样就可以记录更多的key值,其key值是升序排序,

B+tree和b-tree有如下不同点
1,非叶子节点只存储键值信息(key信息)
2,所有叶子节点之间都有一个链指针,数据都存放再叶子节点中
推算
innodb存储引擎一页的大小为16kb,一般主键类型为int占4个字节,或bigint占8个字节,指针类型页一般4个或8个字节,也就是说一个页中大概存储16*1024/16=1024个key,深度为3的B+tree索引(三页)可以维护1024*1024*1024=10亿条记录,实际情况每个节点不可能填满,B+tree的高度一般为2-4曾,mysql的innodb存储引擎将根节点常驻内存,也就是查找某一键值的行记录最多需要1-3次磁盘IO操作
页的概念,
页是innodb读取磁盘的最小单位,整页整页的读取
页分为,数据页(BTreeNode),Undo页(undo Log page),系统页(Systempage),事务数据页(Transaction SystemPage)每个数数据页的大小为16kb,每个page使用一个32位int值来表示,
一个page的基本结构
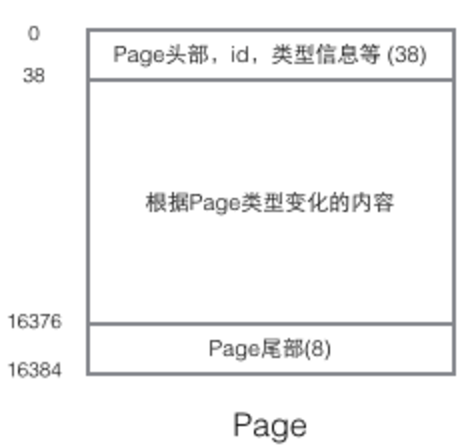
1,0-38:page头部,id,类型信息等占38个字节,头部保存两个指针分别指向前一个page和后一个page,page是一个双向列表
2,38-16376:不同的类型页所含的数据不同,这部分空间包含系统记录(SystemRecord)和用户记录(UserRecord),我们表中的一条条记录就放在UserRecord部分,UserRecord存放的内容可以是以下内容
a,主键索引树非叶子节点,B+tree索引,和指针
b,主键索引树叶子节点,key和data(就是记录本身)
c,辅助键索引树非叶子节点,B+tree辅助索引
d,辅助键索引树叶子节点,key和data(这里的data是主键)
页可以装很多种数据信息,有的页是B+树的所有主键索引,有的页是B+树的叶子节点也就是数据记录本身,有的页是我们创建的二级索引,
16376-16384:page尾部
页和节点的关系
页和节点没有强相关关系
由页组成的链表,页之间是双向列表,页里面的数据是单向链表,这种结构组成了主键索引B+树,组成了叶子节点数据。
定位一条记录的过程,select * from table where id = 29
系统经过解析sql语句,首先读取装有非叶子节点page页,遍历非叶子节点,这个过程随着节点的遍历会将一个或多个page页加载到内存,直到定位到这条记录的叶子节点,然后遍历找出该条记录。
如果使用了二级索引则先读取二级索引page遍历这个二级索引,找到装有主键信息叶子节点page页,遍历找到该主键。然后再根据主键索引寻找到该条记录

mysql的innodb数据存储结构的更多相关文章
- InnoDB数据存储结构
MySQL服务器上 存储引擎 负责对表中数据的读取和写入工作,不同存储引擎中 存放的格式 一般是不同的,甚至有的存储引擎(Memory)不用磁盘来存储数据. 页 (Page) 是磁盘和内存之间交互的基 ...
- MySQL之InnoDB数据页结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页. 一个数据页可以被大致划分为7个部分,分别是 File Header,表示页的一些通用信息,占固定的38字节. Pag ...
- mysql之innodb存储引擎---数据存储结构
一.背景 1.1文件组织架构 首先看一下mysql数据系统涉及到的文件组织架构,如下图所示: msyql文件组织架构图 从图看出: 1.日志文件:slow.log(慢日志),error.log(错误日 ...
- MySQL InnoDB 逻辑存储结构
MySQL InnoDB 逻辑存储结构 从InnoDB存储引擎的逻辑结构看,所有数据都被逻辑地存放在一个空间内,称为表空间,而表空间由段(sengment).区(extent).页(page)组成.p ...
- MYSQL Innodb逻辑存储结构
转载于网络 这几天在读<MySQL技术内幕 InnoDB存储引擎>,对 Innodb逻辑存储结构有了些了解,顺便也记录一下: 从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放 ...
- Mysql+innodb数据存储逻辑
Mysql+innodb数据存储逻辑. 表空间由段,区,页组成 ibdata1:共享表空间.即所有的数据都存放在这个表空间内.如果用户启用了innodb_file_per_table,则每张表内的数据 ...
- InnoDB 逻辑存储结构
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/80 如果创建表时没有显示的定义主键,mysql会按如下方式创建主 ...
- Innodb页面存储结构-2
上一篇<Innodb页面存储结构-1>介绍了Innodb页面存储的总体结构,本文会介绍页面的详细内容,主要包括页头.页尾和记录的详细格式. 学习数据结构时都说程序等于数据结构+算法,而在i ...
- InnoDB逻辑存储结构
从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace).表空间又由段(segment).区(extent).页(page)组成.页在一些文档中 ...
随机推荐
- 转 mysql distinct函数 与 免密码登录 与 查看表的结构
#########sample 1 mysql中去重 distinct 用法 在使用MySQL时,有时需要查询出某个字段不重复的记录,这时可以使用mysql提供的distinct这个关键字来过滤重 ...
- mysql8.0 caching_sha2_password的坑
先来解释一下为什么会报这个错,在mysql8之前的版本使用的密码加密规则是mysql_native_password,但是在mysql8则是caching_sha2_password. 解决方案有很多 ...
- nginx配置优化提高并发量
1 nginx配置优化提高并发量 worker_processes 2; 这个按照CPU的核数来决定 2 worker_connections 65535; 这个一般设置65535即可 每个进程允许的 ...
- linux中C语言的运行(gcc)
执行sudo apt-get install build-essential 出现
- tp3.2 如何比较两个字段
使用exp if ($_GET['owe_property'] || $_GET['owe_property'] !== NULL) { if ((int)$_GET['owe_property'] ...
- Linux crontab 查看所有用户的crontab任务
查看所有用户的crontab任务 - mlzhu007的专栏 - CSDN博客 https://blog.csdn.net/mlzhu007/article/details/81662091 以roo ...
- Django框架第九篇--Django和Ajax、序列化组件(serializers)、自定义分页器、模型表choice参数
Django和Ajax 一.什么是Ajax AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步的Javascript和XML”.即使用Javascript语 ...
- 【题解】Luogu P5300 [GXOI/GZOI2019]与或和
原题传送门 我们珂以拆位,拆成一个个0/1矩阵 贡献珂以用全0,全1的子矩阵的个数来计算 全0,全1的子矩阵的个数珂以用悬线法/单调栈解决 #include <bits/stdc++.h> ...
- APIO2019题解
T1.桥梁(bridges/restriction) Subtask1:暴力,$O(n^2)$. #include<cstdio> #include<algorithm> #d ...
- Map 集合按字母排序方法
@Testpublic void testMapSort() { Map<String, String> map = new HashMap<>(); map.put(&quo ...