DL Practice:Cifar 10分类
Step 1:数据加载和处理
一般使用深度学习框架会经过下面几个流程:
模型定义(包括损失函数的选择)——>数据处理和加载——>训练(可能包括训练过程可视化)——>测试
所以自己写代码的时候基本上按照这四大模块四步走就ok了。
本例步骤:
A、Load and normalizing the CIFAR10 training and test datasets using torchvision
B、Define a Convolution Neural Network
C、Define a loss function
D、Train the network on the training data
E、Test the network on the test data
首先使用torchvision加载和归一化训练数据与测试数据。
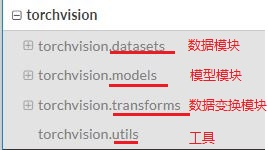
torchvision实现了常用的一些深度学习的相关图像数据的加载功能,比如cifar10、Imagenet、Mnist等。保存在torchvision.datasets模块中;
torchvision也封装了一些处理数据的方法。保存在torchvision.transforms模块中。
torchvision还封装了一些模型和工具封装在相应模型中。
# 首先当然肯定要导入torch和torchvision,至于第三个是用于进行数据预处理的模块
import torch
import torchvision
import torchvision.transforms as transforms # 由于torchvision的datasets的输出是[0,1]的PILImage,所以我们先先归一化为[-1,1]的Tensor
# 首先定义了一个变换transform,利用的是上面提到的transforms模块中的Compose( )
# 把多个变换组合在一起,可以看到这里面组合了ToTensor和Normalize这两个变换
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 定义了我们的训练集,名字就叫trainset,至于后面这一堆,其实就是一个类:
# torchvision.datasets.CIFAR10( )也是封装好了的,就在我前面提到的torchvision.datasets
# 模块中,不必深究,如果想深究就看我这段代码后面贴的图1,其实就是在下载数据
#(不翻墙可能会慢一点吧)然后进行变换,可以看到transform就是我们上面定义的transform
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# trainloader其实是一个比较重要的东西,我们后面就是通过trainloader把数据传入网
# 络,当然这里的trainloader其实是个变量名,可以随便取,重点是它是由后面的
# torch.utils.data.DataLoader()定义的,这个东西来源于torch.utils.data模块,
# 网页链接http://pytorch.org/docs/0.3.0/data.html,这个类可见我后面图2
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 对于测试集的操作和训练集一样
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 类别信息也是需要我们给定的
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Step 2:定义卷积神经网络
这一步虽然代码量很少,但是却包含很多难点和重点,执行这一步的代码需要包含神经网络工具箱torch.nn、神经网络函数torch.nn.functional。
注意:虽然官网给的程序有这么一句 from torch.autograd import Variable,但是此步中确实没有显式地用到variable,只能说网络里运行的数据确实要以variable的形式存在,在后面我们会讲解这个内容。
# 首先是调用Variable、 torch.nn、torch.nn.functional
from torch.autograd import Variable # 这一步还没有显式用到variable,但是现在写在这里也没问题,后面会用到
import torch.nn as nn
import torch.nn.functional as F class Net(nn.Module): # 我们定义网络时一般是继承的torch.nn.Module创建新的子类
def __init__(self):
super(Net, self).__init__() # 第二、三行都是python类继承的基本操作,此写法应该是python2.7的继承格式,但python3里写这个好像也可以
self.conv1 = nn.Conv2d(3, 6, 5) # 添加第一个卷积层,调用了nn里面的Conv2d()
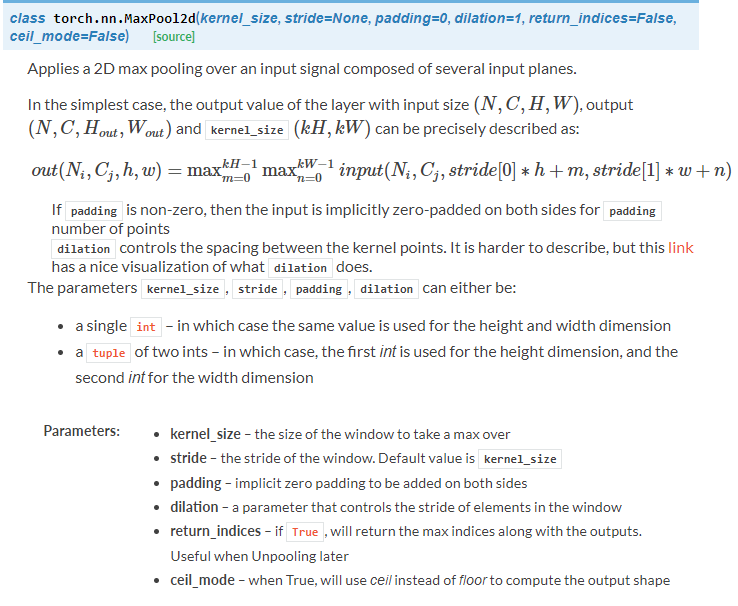
self.pool = nn.MaxPool2d(2, 2) # 最大池化层
self.conv2 = nn.Conv2d(6, 16, 5) # 同样是卷积层
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 接着三个全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) def forward(self, x): # 这里定义前向传播的方法,为什么没有定义反向传播的方法呢?这其实就涉及到torch.autograd模块了,
# 但说实话这部分网络定义的部分还没有用到autograd的知识,所以后面遇到了再讲
x = self.pool(F.relu(self.conv1(x))) # F是torch.nn.functional的别名,这里调用了relu函数 F.relu()
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5) # .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。
# 第一个参数-1是说这个参数由另一个参数确定, 比如矩阵在元素总数一定的情况下,确定列数就能确定行数。
# 那么为什么这里只关心列数不关心行数呢,因为马上就要进入全连接层了,而全连接层说白了就是矩阵乘法,
# 你会发现第一个全连接层的首参数是16*5*5,所以要保证能够相乘,在矩阵乘法之前就要把x调到正确的size
# 更多的Tensor方法参考Tensor: http://pytorch.org/docs/0.3.0/tensors.html
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x # 和python中一样,类定义完之后实例化就很简单了,我们这里就实例化了一个net
net = Net()
知识点:
1、神经网络工具箱torch.nn
:这是一个专为深度学习设计的模块,我们来看一下官方文档中它的目录。
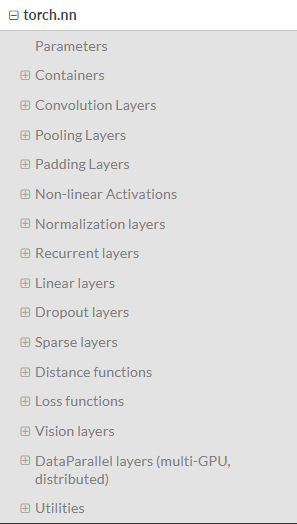
a. Container中的Module,也即nn.Module
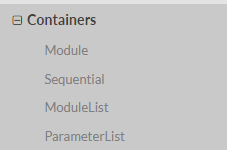
看一下nn.Module的详细介绍:
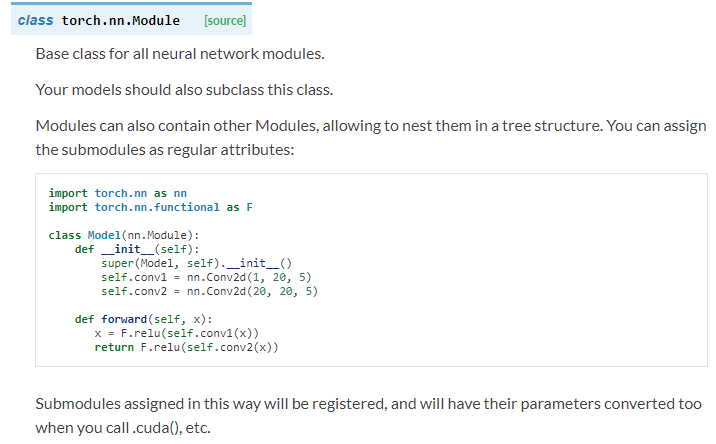
可知,nn.Module是所有神经网络的基类,我们自己定义任何神经网络,都要继承nn.Module!class Net(nn.Module)。
b. convolution layers
我们在上面的代码块中用到了Conv2d: self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5)

例如Conv2d(1,20,5)的意思就是说,输入是1通道的图像,输出是20通道,也就是20个卷积核,卷积核是5*5,其余参数都是用的默认值。
c. pooling layers
可以看到有很多的池化方式,我们上面的代码采用的是Maxpool2d: self.pool = nn.MaxPool2d(2, 2)
d. Linear layer
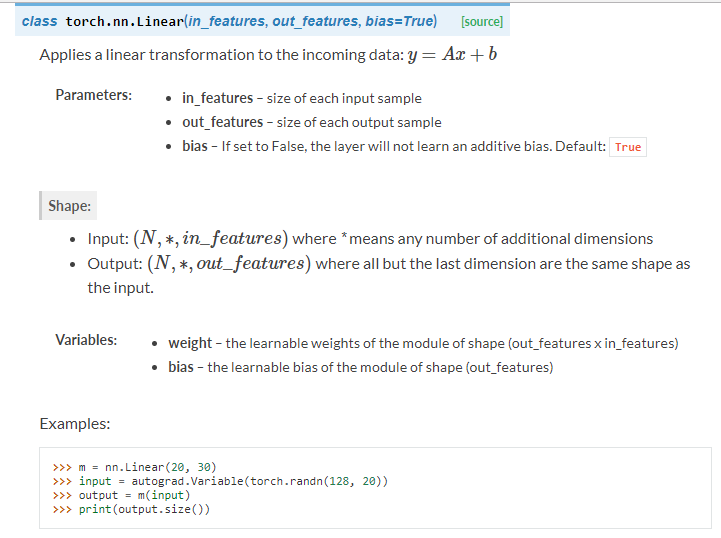
e. Non-linear Activations
要注意,其实这个例子中的非线性激活函数用的并不是torch.nn模块中的这个部分,但是torch.nn模块中有这个部分,所以还是提一下。
此例中的激活函数用的其实是torch.nn.functional 模块中的函数。它们是有区别的,区别下文继续讲。现在先浏览一下这个部分的内容即可:
2、torch.nn.functional
torch.nn中大多数layer在torch.nn.funtional中都有一个与之对应的函数。二者的区别在于:
torch.nn.Module中实现layer的都是一个特殊的类,可以去查阅,他们都是以class xxxx来定义的,会自动提取可学习的参数
而nn.functional中的函数,更像是纯函数,由def function( )定义,只是进行简单的数学运算而已。
说到这里你可能就明白二者的区别了,functional中的函数是一个确定的不变的运算公式,输入数据产生输出就ok,
而深度学习中会有很多权重是在不断更新的,不可能每进行一次forward就用新的权重重新来定义一遍函数来进行计算,所以说就会采用类的方式,以确保能在参数发生变化时仍能使用我们之前定好的运算步骤。
所以从这个分析就可以看出什么时候改用nn.Module中的layer了:
如果模型有可学习的参数,最好使用nn.Module对应的相关layer,否则二者都可以使用,没有什么区别。
比如此例中的Relu其实没有可学习的参数,只是进行一个运算而已,所以使用的就是functional中的relu函数,
而卷积层和全连接层都有可学习的参数,所以用的是nn.Module中的类。
不具备可学习参数的层,将它们用函数代替,这样可以不用放在构造函数中进行初始化。
定义网络模型,主要会用到的就是torch.nn 和torch.nn.funtional这两个模块,这两个模块值得去细细品味一番,希望大家可以去读一下官方文档!
Step 3:定义损失函数和优化器
import torch.optim as optim #导入torch.potim模块 criterion = nn.CrossEntropyLoss() #同样是用到了神经网络工具箱 nn 中的交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) #optim模块中的SGD梯度优化方式---随机梯度下降
涉及知识点
1、优化器
pytorch将深度学习中常用的优化方法全部封装在torch.optim之中,所有的优化方法都是继承基类optim.Optimizier

图中提到了如果想要把模型搬到GPU上跑,就要在定义优化器之前就完成.cuda( )这一步。
2、损失函数
损失函数是封装在神经网络工具箱nn中的,包含很多损失函数,如图所示:
此例中用到的是交叉熵损失,criterion = nn.CrossEntropyLoss() 详情如下:
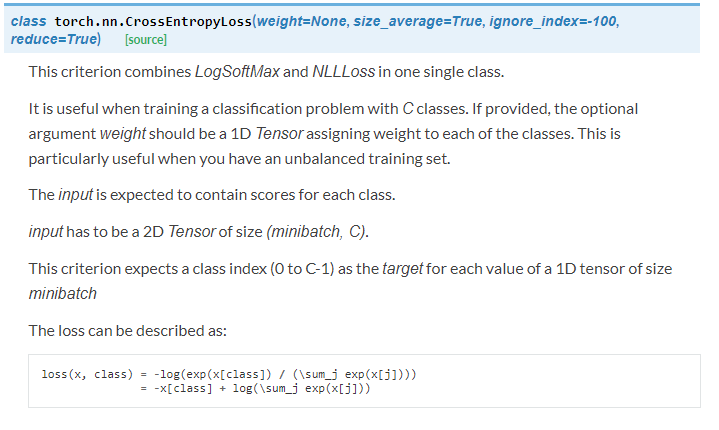


基本上这一步没什么好说的,就是在众多的优化器方法和损失函数中选择就ok,具体选什么就由自己情况定。
Step 4:训练
经过前面的数据加载和网络定义后,就可以开始训练了,这里会看到前面遇到的一些东西究竟在后面会有什么用,所以这一步应该仔细研究一下。
for epoch in range(2): # loop over the dataset multiple times 指定训练一共要循环几个epoch
running_loss = 0.0 #定义一个变量方便我们对loss进行输出
for i, data in enumerate(trainloader, 0): # 这里我们遇到了第一步中出现的trailoader,代码传入数据
# enumerate是python的内置函数,既获得索引也获得数据,详见下文
# get the inputs
inputs, labels = data # data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels) # 将数据转换成Variable,第二步里面我们已经引入这个模块
# 所以这段程序里面就直接使用了,下文会分析
# zero the parameter gradients
optimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度
# forward + backward + optimize
outputs = net(inputs) # 把数据输进网络net,这个net()在第二步的代码最后一行我们已经定义了
loss = criterion(outputs, labels) # 计算损失值,criterion我们在第三步里面定义了
loss.backward() # loss进行反向传播,下文详解
optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮
# print statistics # 这几行代码不是必须的,为了打印出loss方便我们看而已,不影响训练过程
running_loss += loss.data[0] # 从下面一行代码可以看出它是每循环0-1999共两千次才打印一次
if i % 2000 == 1999: # print every 2000 mini-batches 所以每个2000次之类先用running_loss进行累加
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000)) # 然后再除以2000,就得到这两千次的平均损失值
running_loss = 0.0 # 这一个2000次结束后,就把running_loss归零,下一个2000次继续使用
print('Finished Training')
分析:
1、autograd
在第二步中我们定义网络时定义了前向传播函数,但是并没有定义反向传播函数,可是深度学习是需要反向传播求导的,
Pytorch其实利用的是Autograd模块来进行自动求导,反向传播。
Autograd中最核心的类就是Variable了,它封装了Tensor,并几乎支持所有Tensor的操作,这里可以参考官方给的详细解释:
http://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-py
以上链接详细讲述了variable究竟是怎么能够实现自动求导的,怎么用它来实现反向传播的。
这里涉及到计算图的相关概念。想要计算各个variable的梯度,只需调用根节点的backward方法,Autograd就会自动沿着整个计算图进行反向计算
而在此例子中,根节点就是我们的loss,所以:
程序中的loss.backward()代码就是在实现反向传播,自动计算所有的梯度。
所以训练部分的代码其实比较简单:
running_loss和后面负责打印损失值的那部分并不是必须的,所以关键行不多,总得来说分成三小节
第一节:把最开始放在trainloader里面的数据给转换成variable,然后指定为网络的输入;
第二节:每次循环新开始的时候,要确保梯度归零
第三节:forward+backward,就是调用我们在第三步里面实例化的net()实现前传,loss.backward()实现后传
每结束一次循环,要确保梯度更新。
Step 5:测试
dataiter = iter(testloader) # 创建一个python迭代器,读入的是我们第一步里面就已经加载好的testloader
images, labels = dataiter.next() # 返回一个batch_size的图片,根据第一步的设置,应该是4张 # print images
imshow(torchvision.utils.make_grid(images)) # 展示这四张图片
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4))) # python字符串格式化 ' '.join表示用空格来连接后面的字符串,参考python的join()方法
这一部分代码就是先随机读取4张图片,让我们看看这四张图片是什么并打印出相应的label信息,
因为第一步里面设置了是shuffle了数据的,也就是顺序是打乱的,所以各自出现的图像不一定相同。
outputs = net(Variable(images)) # 注意这里的images是我们从上面获得的那四张图片,所以首先要转化成variable
_, predicted = torch.max(outputs.data, 1)
# 这个 _ , predicted是python的一种常用的写法,表示后面的函数其实会返回两个值
# 但是我们对第一个值不感兴趣,就写个_在那里,把它赋值给_就好,我们只关心第二个值predicted
# 比如 _ ,a = 1,2 这中赋值语句在python中是可以通过的,你只关心后面的等式中的第二个位置的值是多少 print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) # python的字符串格式化
这里用到了torch.max( ), 它是属于Tensor的一个方法:

注意到注释中第一句话,是说返回输入Tensor中每行的最大值,并转换成指定的dim(维度).
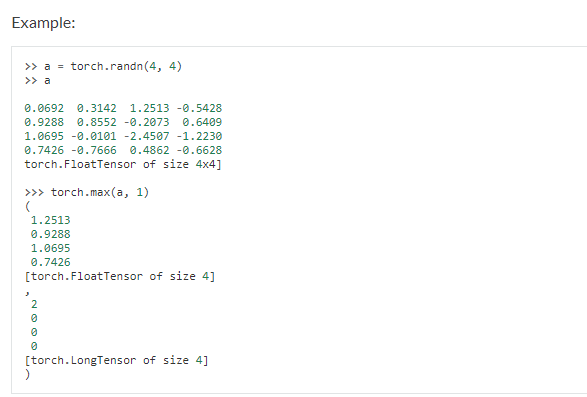
所以我们程序中的 torch.max(outputs.data, 1) ,返回一个tuple (元组)
而这里很明显,这个返回的元组的第一个元素是image data,即是最大的 值,第二个元素是label, 即是最大的值 的 索引!
我们只需要label(最大值的索引),所以就会有 _ , predicted这样的赋值语句,表示忽略第一个返回值,把它赋值给 _, 就是舍弃它的意思;
我在注释中也说明了这是什么意思
这里说一下,这第二个参数1,看清楚上面的说明是 the dimension to reduce! 而不是去这个dimension上面找最大
所以这里dim=1,基于我们的a是 4行 x 4列 这么一个维度,所以指的是 消除列这个维度,这是个什么意思呢?
如果我们把上面的示例代码中,的参数 keepdim=True写上,torch.max(a,1,keepdim=True), 会发现,返回的结果的第一个元素,即表示最大的值的那部分,其实是一个 size为 【4,1】的Tensor,也就是其实它是在 按照每行 来找最大,所以结果是4行,然后因为只找一个最大值,所以是1列,整个size就是 4行 1 列, 然后参数dim=1,相当于调用了 squeeze(1),这个操作,上面的说明也是这么写的,所以最后就得到结果是一个size为4的vector。
你可以自己下去在ipython里面做实验,发现如果dim=0,它其实是在返回每列的最大值,
所以一定不要搞混!这里的dim是指的 the dimension to reduce!并不是在the dimension上去返回最大值。
所以其实我自己写的时候一般更喜欢用 torch.argmax()这个函数更直观更好理解一些
总之在这里你只需要理解这行操作的功能是:返回了最大的索引,即预测出来的类别。 想深入研究可以自己去ipython里面试一下
correct = 0 # 定义预测正确的图片数,初始化为0
total = 0 # 总共参与测试的图片数,也初始化为0
for data in testloader: # 循环每一个batch
images, labels = data
outputs = net(Variable(images)) # 输入网络进行测试
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 更新测试图片的数量
correct += (predicted == labels).sum() # 更新正确分类的图片的数量 print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total)) # 最后打印结果
tutorial给的结果是53%.
来测试一下每一类的分类正确率:
class_correct = list(0. for i in range(10)) # 定义一个存储每类中测试正确的个数的 列表,初始化为0
class_total = list(0. for i in range(10)) # 定义一个存储每类中测试总数的个数的 列表,初始化为0
for data in testloader: # 以一个batch为单位进行循环
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(4): # 因为每个batch都有4张图片,所以还需要一个4的小循环
label = labels[i] # 对各个类的进行各自累加
class_correct[label] += c[i]
class_total[label] += 1 for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
DL Practice:Cifar 10分类的更多相关文章
- 【翻译】TensorFlow卷积神经网络识别CIFAR 10Convolutional Neural Network (CNN)| CIFAR 10 TensorFlow
原网址:https://data-flair.training/blogs/cnn-tensorflow-cifar-10/ by DataFlair Team · Published May 21, ...
- 【神经网络与深度学习】基于Windows+Caffe的Minst和CIFAR—10训练过程说明
Minst训练 我的路径:G:\Caffe\Caffe For Windows\examples\mnist 对于新手来说,初步完成环境的配置后,一脸茫然.不知如何跑Demo,有么有!那么接下来的教 ...
- PAT (Basic Level) Practice 1012 数字分类 分数 20
给定一系列正整数,请按要求对数字进行分类,并输出以下 5 个数字: A1 = 能被 5 整除的数字中所有偶数的和: A2 = 将被 5 除后余 1 的数字按给出顺序进行交错求和,即计算 n1−n ...
- TensorFlow—CNN—CIFAR数据集分类
- 【转】DBMS_STATS.GATHER_TABLE_STATS详解 2012-04-22 09:20:10
[转]DBMS_STATS.GATHER_TABLE_STATS详解 2012-04-22 09:20:10 分类: Linux 由于Oracle的优化器是CBO,所以对象的统计数据对执行计划的生成至 ...
- 文本分类-TextCNN
简介 TextCNN模型是由 Yoon Kim提出的Convolutional Naural Networks for Sentence Classification一文中提出的使用卷积神经网络来处理 ...
- 四、10分钟ToPandas_0.24.2
# Author:Zhang Yuan整理,版本Pandas0.24.2 # 0. 习惯上,我们会按下面格式引入所需要的包: import pandas as pd import numpy as n ...
- Java开发者写SQL时常犯的10个错误
首页 所有文章 资讯 Web 架构 基础技术 书籍 教程 我要投稿 更多频道 » - 导航条 - 首页 所有文章 资讯 Web 架构 基础技术 书籍 教程 我要投稿 更多频道 » - iOS ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
随机推荐
- 洛谷【P1498】:南蛮图腾(分治算法)
传送门 题目描述就不用看了,直接上样例就行: 输入样例#1: 2 输出样例#1: /\ /__\ /\ /\ /__\/__\ 输入样例#2: 3 输出样例#2: /\ /__\ /\ /\ /__\ ...
- vim 常用命令(记录)
很好的vim讲解:https://blog.csdn.net/weixin_37657720/article/details/80645991 命令模式:默认模式.输入ctrl+c, 输入:,转换为命 ...
- Linux SSH 连接安全设置
一.更换端口, 可以在一定程度上防止扫描攻击 vim /etc/ssh/sshd_config 将 port 一项从 22 更改为高位端口, 然后重启 ssh 服务 systemctl restart ...
- MapReduce的核心运行机制
MapReduce的核心运行机制概述: 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 ...
- jquery.lazyload.js-v1.9.1延时加载插件,已兼容ie6和各大浏览器
来源:http://www.jq22.com/jquery-info390 使用前要求: img的设置: 1.class要配上“lazy”: 2.用data-original代替src: 3.如果想要 ...
- Linux软件安装——软件包分类、RPM包管理
1.软件包分类: (1)源码包: 优点:开源,即用户可以看到源代码,用户可以修改源代码:可以自由选择所需的功能:软件是编译安装,效率更高. 缺点:需要手动安装,安装慢. (2)二进制包(RPM包.系统 ...
- minikube 安装试用
目前使用k8s 要么用的物理机搭建的环境,要么就是使用docker for mac 中kubernetes 的特性,为了本地调试方便,使用下minikube minukube 包含的特性 负载均衡器 ...
- 原手下一名98年的java离职了
原手下一名98年的java离职了,回家考试要2年. 系统做的还算凑合,毕竟年龄在这. 需要改善的地方我会放到自己的项目管理工具中去改善. 离职前他一直跟我说微服务的启动是用docker,也感谢他,我们 ...
- 4-网页,网站,微信公众号基础入门(配置网站--下载安装PHP)
https://www.cnblogs.com/yangfengwu/p/10979101.html 这一节咱看一下如何在原先的基础上实现网站 首先去下载 PHP https://windows.ph ...
- cf1189解题报告
cf1189div2解题报告 codeforces A 答案要不是一串要不就是去掉最后一个字母的两串 #include <bits/stdc++.h> #define ll long lo ...