Python爬取网址中多个页面的信息
通过上一篇博客了解到爬取数据的操作,但对于存在多个页面的网址来说,使用上一篇博客中的代码爬取下来的资料并不完整。接下来就是讲解该如何爬取之后的页面信息。
一、审查元素
鼠标移至页码处右键,选择检查元素
接着屏幕下方就会出现对应的html语句
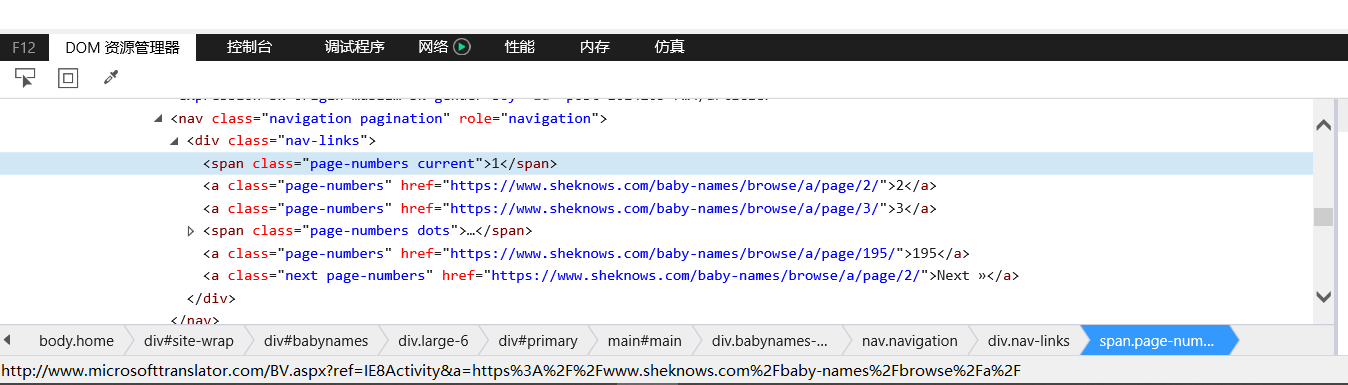
二、分析html语句与项目要求
本次项目是爬取所有信息,根据第一步中的html语句,我们有两种爬取后续页面信息的方法:
方法一:循环访问本页面中的“下一页”链接直至该标签为空
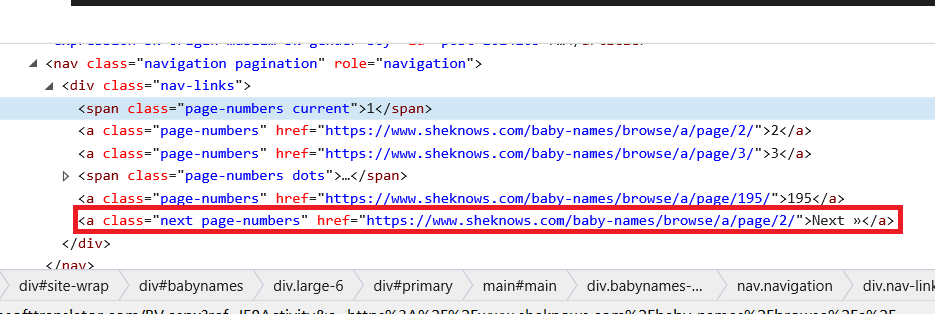
即
def next_page(url):
soup=get_requests(url)
draw_base_list(soup)
pcxt=soup.find('div',{'class':'babynames-term-articles'}).find('nav')
pcxt1=pcxt.find('div',{'class':'nav-links'}).find('a',{'class':'next page-numbers'})
if pcxt1!=None:
link=pcxt1.get('href')
next_page(link)
else:
print("爬取完成")
方法二:获取总页数,通过更改url来爬取后续信息
通过html语句可以看出不同页数的url只有最后的数字不一样,而最后的数字就代表着这个url中的信息是第几页的信息。
页面中的html语句给出了总页码,我们只需要定位至该标签并获得总页数即可。
即
def get_page_size(soup):
pcxt=soup.find('div',{'class':'babynames-term-articles'}).find('nav')
pcxt1=pcxt.find('div',{'class':'nav-links'}).findAll('a')
for i in pcxt1[:-1]:
link=i.get('href')
s=str(i)
page=re.sub('<a class="page-numbers" href="','',s)
page1=re.sub(link,'',page)
page2=re.sub('">','',page1)
page3=re.sub('</a>','',page2)
pagesize=int(page3)
print(pagesize)
return pagesize
pass
获得总页数后这个模块还没有结束,我们还需要更改url来访问网址,也就是主函数的编写:
if __name__ == '__main__':
url="http://www.sheknows.com/baby-names/browse/a/"
soup=get_requests(url)
page=get_page_size(soup)
for i in range(1,page+1):
url1=url+"page/"+str(i)+"/"
soup1=get_requests(url1)
draw_base_list(soup1)
通过以上的两种方法就可以将多个页面中的信息都爬取下来了,赶紧动手试试吧。

Python爬取网址中多个页面的信息的更多相关文章
- python爬取豌豆荚中的详细信息并存储到SQL Server中
买了本书<精通Python网络爬虫>,看完了第6章,我感觉我好像可以干点什么:学的不多,其中的笔记我放到了GitHub上:https://github.com/NSGUF/PythonLe ...
- Python 爬取网页中JavaScript动态添加的内容(一)
当我们进行网页爬虫时,我们会利用一定的规则从返回的 HTML 数据中提取出有效的信息.但是如果网页中含有 JavaScript 代码,我们必须经过渲染处理才能获得原始数据.此时,如果我们仍采用常规方法 ...
- Python 爬取 北京市政府首都之窗信件列表-[信息展示]
日期:2020.01.25 博客期:133 星期六 [代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明] //博客总体说明 1.准备工作 2.爬取工作 3.数据处理 4.信息展示(本期博客 ...
- Python 爬取网页中JavaScript动态添加的内容(二)
使用 selenium + phantomjs 实现 1.准备环境 selenium(一个用于web应用程测试的工具)安装:pip install seleniumphantomjs(是一种无界面的浏 ...
- python爬取网络中的QQ号码
import urllib.request import ssl import re import os #博客地址:https://blog.csdn.net/qq_36374896 def wri ...
- python 爬取国家粮食局东北地区玉米收购价格监测信息
#!/usr/bin/python# -*- coding: UTF-8 -*-import reimport sysimport timeimport urllibimport urllib.req ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 一个自定义python分布式专用爬虫框架。支持断点爬取和确保消息100%不丢失,哪怕是在爬取进行中随意关停和随意对电脑断电。
0.此框架只能用于爬虫,由框架来调度url请求,必须按照此方式开发,没有做到类似celery的通用分布式功能,也不方便测试.可以使用另外一个,基于函数式编程的,调度一切函数的分布式框架,做到了兼容任何 ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
随机推荐
- (尚002)Vue的基本使用
输入端在上面变化的同时,下面的内容也在变 View-->DOM监听-->指令;大括号数据 {{username}} Model-->模型(简单来说就是data,数据供view自动去读 ...
- git 查看项目代码统计命令
git log --author="xxxxxxxx" --pretty=tformat: --numstat | gawk '{ add += $1 ; subs += $2 ; ...
- Reed-Solomon纠错码的译码
其中用到了等比数列展开:1/(1-\alpha). 此时,似乎应该将\alpha视为模远小于1的复数. 只有这样,\alpha^i 才能作为一个有限域中的元素展开.它在一个半径小于1的圆上,由若干具 ...
- [mysql8]新坑哈 更改Mysql 表的大小转换设置lower_case_table_names=1
在安装了8.0.14之后,初始化的时候在my.cnf里设置了lower_case_table_names=1,安装好了之后,启动报错: 1 2 3 4 5 2019-01-28T13:24:24.91 ...
- 2019强网杯web upload writeup及关键思路
<?phpnamespace app\web\controller; class Profile{ public $checker; public $filename_tmp; ...
- python2 && python3 的 input函数
Python2.x中的input()函数input()函数让我们明确我们输入的是数字格式还是字符格式,就是我们自己要知道我们想要的是什么,数字格式直接输入,字符格式必须加上单引号或者双引号,以确定我们 ...
- Intellij IDEA 从入门到上瘾 图文教程
1. IDEA VS Eclipse 核心术语比较 由下图可见:两者最大的转变就在于工作空间概念的转变,并且在IDEA当中,Project和 Module是作为两个不同的概念,对项目结构是具有重大 ...
- Android中活动的最佳实践(如何很快的看懂别人的代码activity)
这种方法主要在你拿到别人的代码时候很多activity一时半会儿看不懂,用了这个方法以后就可以边实践操作就能够知道具体哪个activity是干什么用的 1.新建一个BaseActivity的类,让他继 ...
- js jquery 实现 排班,轮班,日历,日程。使用fullcalendar 插件
如果想用fullcalendar实现排班功能,或者日历.日程功能.那么只需要简单的几步: 这里先挂官网链接: fullcalendar fullcalendar官网下载链接 一.下载及简单配置 1.这 ...
- JavaWeb之基础(1) —— 文件、目录结构和创建项目
1. JavaWeb应用 JavaWeb应用从大类上分为静态和动态两种. 静态应用就是传统的HTML文件+素材资源构造的静态网页,不需要特殊的配置.JavaWeb也不是专门用来做静态网站的. 动态应用 ...