ElasticSearch 索引查询使用指南——详细版
- 我们通常用用
_catAPI检测集群是否健康。 确保9200端口号可用:
curl 'localhost:9200/_cat/health?v'
绿色表示一切正常, 黄色表示所有的数据可用但是部分副本还没有分配,红色表示部分数据因为某些原因不可用.
2.通过如下语句,我们可以获取集群的节点列表:
curl 'localhost:9200/_cat/nodes?v'
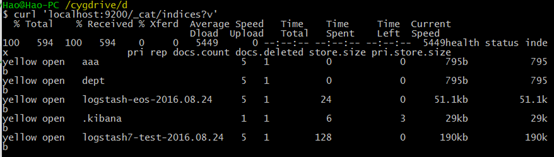
3。通过如下语句,列出所有索引:
curl 'localhost:9200/_cat/indices?v'
返回结果:
4.创建索引
现在我们创建一个名为“customer”的索引,然后再查看所有的索引:
curl -XPUT 'localhost:9200/customer?pretty'
curl 'localhost:9200/_cat/indices?v'
结果如下:

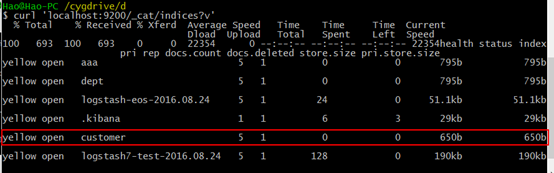
上图中红框所表示的是:我们有一个叫customer的索引,它有五个私有的分片以及一个副本,在它里面有0个文档。
5.插入和获取
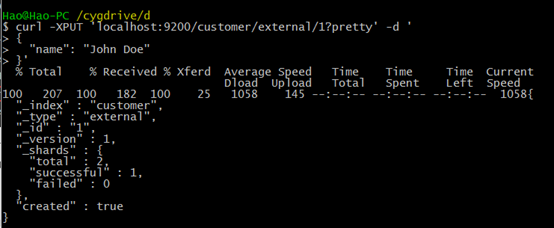
现在我么插入一些数据到集群索引。我们必须给ES指定所以的类型。如下语句:"external" type, ID:1:
主体为JSON格式的语句: { "name": "John Doe" }
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'
返回结果为:create:true 表示插入成功。
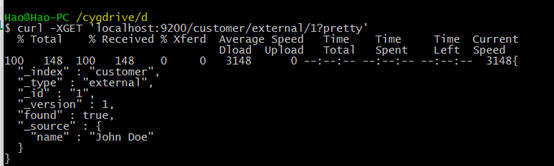
获取GET,语句如下:
curl -XGET 'localhost:9200/customer/external/1?pretty'
其中含义为:获取customer索引下类型为external,id为1的数据,pretty参数表示返回结果格式美观。
6.删除索引 DELETE
curl -XDELETE 'localhost:9200/customer?pretty'
curl 'localhost:9200/_cat/indices?v'
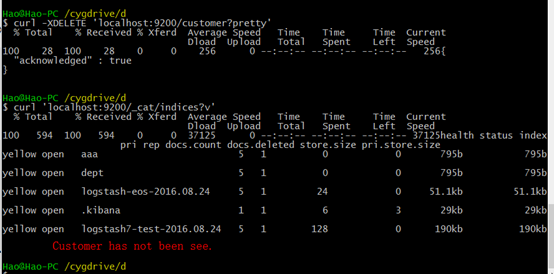
表示索引删除成功。
7.通过以上命令语句的学习,我们发现索引的增删改查有一个类似的格式,总结如下:
curl -X<REST Verb> <Node>:<Port>/<Index>/<Type>/<ID>
<REST Verb>:REST风格的语法谓词
<Node>:节点ip
<port>:节点端口号,默认9200
<Index>:索引名
<Type>:索引类型
<ID>:操作对象的ID号
8 修改数据
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "Jane Doe"
}'
上述命令语句是:先新增id为1,name为John Doe的数据,然后将id为1的name修改为Jane Doe。
9.更新数据
9.1 这个例子展示如何将id为1文档的name字段更新为Jane Doe:
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d '
{
"doc": { "name": "Jane Doe" }
}'
9.2 这个例子展示如何将id为1数据的name字段更新为Jane Doe同时增加字段age为20:
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d '
{
"doc": { "name": "Jane Doe", "age": 20 }
}'
9.3 也可以通过一些简单的scripts来执行更新。一下语句通过使用script将年龄增加5:
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d '
{
"script" : "ctx._source.age += 5"
}'
10 删除数据
删除数据那是相当的直接. 下面的语句将执行删除Customer中ID为2的数据:
curl -XDELETE 'localhost:9200/customer/external/2?pretty'
11 批处理
举例:
下面语句将在一个批量操作中执行创建索引:
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d '
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
'
下面语句批处理执行更新id为1的数据然后执行删除id为2的数据
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d '
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}}
'
12.导入数据集
你可以点击这里下载示例数据集:accounts.json
其中每个数据都是如下格式:
{
"index":{"_id":"1"}
}
{
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
}
导入示例数据集:
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary "@accounts.json"
curl 'localhost:9200/_cat/indices?v'

上图红框表示我们已经成功批量导入1000条数据索引到bank索引中。
13.查询
Sample:
curl 'localhost:9200/bank/_search?q=*&pretty'
{
"took" : 63,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1000,
"max_score" : 1.0,
"hits" : [ {
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : 1.0, "_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
}, {
"_index" : "bank",
"_type" : "account",
"_id" : "6",
"_score" : 1.0, "_source" : {"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
}, {
"_index" : "bank",
"_type" : "account",
上面示例返回所有bank中的索引数据。其中 q=* 表示匹配索引中所有的数据。
等价于:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} }
}'
14 查询语言
匹配所有数据,但只返回1个:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"size": 1
}'
注意:如果siez不指定,则默认返回10条数据。
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"from": 10,
"size": 10
}'
返回从11到20的数据。(索引下标从0开始)
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } }
}'
上述示例匹配所有的索引中的数据,按照balance字段降序排序,并且返回前10条(如果不指定size,默认最多返回10条)。
15.执行搜索
下面例子展示如何返回两个字段(account_number balance)
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"_source": ["account_number", "balance"]
}'
返回account_number 为20 的数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "account_number": 20 } }
}'
返回address中包含mill的所有数据::
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "address": "mill" } }
}'
返回地址中包含mill或者lane的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "address": "mill lane" } }
}'
和上面匹配单个词语不同,下面这个例子是多匹配(match_phrase短语匹配),返回地址中包含短语 “mill lane”的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_phrase": { "address": "mill lane" } }
}'
以下是布尔查询,布尔查询允许我们将多个简单的查询组合成一个更复杂的布尔逻辑查询。
这个例子将两个查询组合,返回地址中含有mill和lane的所有记录数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}'
上述例子中,must表示所有查询必须都为真才被认为匹配。
相反, 这个例子组合两个查询,返回地址中含有mill或者lane的所有记录数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"should": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}'
上述例子中,bool表示查询列表中只要有任何一个为真则认为匹配。
下面例子组合两个查询,返回地址中既没有mill也没有lane的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must_not": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}'
上述例子中,must_not表示查询列表中没有为真的(也就是全为假)时则认为匹配。
我们可以组合must、should、must_not来实现更加复杂的多级逻辑查询。
下面这个例子返回年龄大于40岁、不居住在ID的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}'
16.过滤filter(查询条件设置)
下面这个例子使用了布尔查询返回balance在20000到30000之间的所有数据。
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}'
17 聚合 Aggregations
下面这个例子: 将所有的数据按照state分组(group),然后按照分组记录数从大到小排序,返回前十条(默认):
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state"
}
}
}
}'
注意:我们设置size=0,不显示查询hits,因为我们只想看返回的聚合结果。
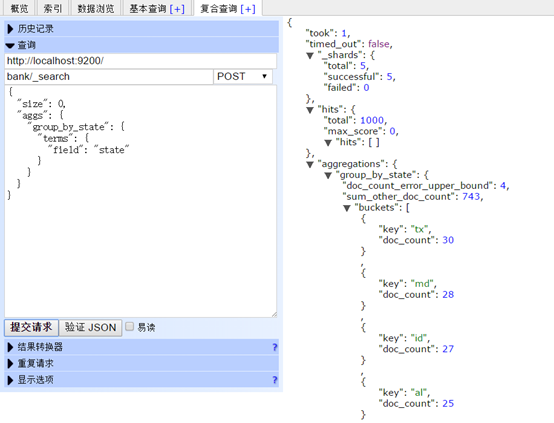

上述语句类似于以下SQL语句:
SELECT state, COUNT(*) FROM bank GROUP BY state ORDER BY COUNT(*) DESC
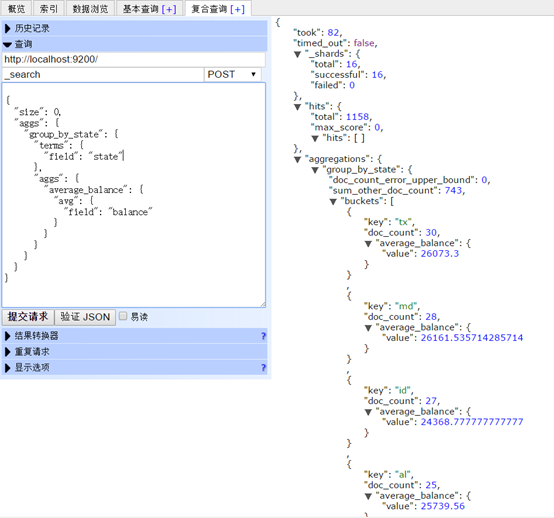
下面这个实例按照state分组,降序排序,返回balance的平均值:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}'
ElasticSearch 索引查询使用指南——详细版的更多相关文章
- ElasticSearch 索引查询使用指南
1.检测集群是否健康,我们通常用下面的命令.确保9200端口号可用: http://localhost:9200/_cat/health?v 或者 http://localhost:9200/_clu ...
- elasticsearch索引查询,日志搜素
索引查询 http://10.199.137.115:9200/_cat/indices?format=json 返回json字符串的索引状态 增加索引名称过滤 http://10.199.137.1 ...
- Elasticsearch 索引生命周期管理 ILM 实战指南
文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ 1.什么是索引生命周期 在基于日志.指标.实时时间序列的大型系统中,集群的索引也具备类似 ...
- elasticsearch之多索引查询
一.问题源起 在elasticsearch的查询中,我们一般直接通过URL来设置要search的index: 如果我们需要查询的索引比较多并且没有什么规律的话,就会面临一个尴尬的局面,超过URL的长度 ...
- Elasticsearch索引和查询性能调优的21条建议
Elasticsearch部署建议 1. 选择合理的硬件配置:尽可能使用 SSD Elasticsearch 最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能.使用SSD(PCI-E接口SSD卡/SA ...
- ElasticSearch 常用查询语句
为了演示不同类型的 ElasticSearch 的查询,我们将使用书文档信息的集合(有以下字段:title(标题), authors(作者), summary(摘要), publish_date(发布 ...
- HBase和ElasticSearch索引类型及存储位置
本篇博文主要对HyperBase(HBase).Search(ElasticSearch)的索引类型及具体存储位置进行概要总结,让大家从整体上了解TDH平台中HyperBase和Search索引的管理 ...
- 正确遍历ElasticSearch索引
1:ElasticSearch的查询过程 2:由ES查询模式引起的深度分页问题 3:如何正确遍历索引中的数据 ElasticSearch的查询过程 es的数据查询分两步: 第一步是的结果是获取满足查询 ...
- ES3:ElasticSearch 索引
ElasticSearch是文档型数据库,索引(Index)定义了文档的逻辑存储和字段类型,每个索引可以包含多个文档类型,文档类型是文档的集合,文档以索引定义的逻辑存储模型,比如,指定分片和副本的数量 ...
随机推荐
- HDU 4348 I - To the moon 可持续化
队友套的可持续化线段树,徘徊在RE和MLE之间多发过的... 复用结点新的线段树平均要log2N个结点. 其实离线就好,按照时间顺序组织操作然后dfs. #include <iostream&g ...
- poj3264 划分树
题意: 给定一个序列,询问区间中最大数减去最小数的结果 和2104差不多, 代码贴过来就OK了 #include <iostream> #include <algorithm> ...
- table 会有默认的外边框,内部会有分割线
.表格中边框的显示 只显示上边框 <table frame=above> 只显示下边框 <table frame=below> 只显示左.右边框 <table frame ...
- mac 上node.js环境的安装与测试【转】
http://blog.csdn.net/baihuaxiu123/article/details/51868142 一 摘要 如何大家之前做过web服务器的人都知道,nginx+lua与现在流行的n ...
- 【Codeforces Rockethon 2014】Solutions
转载请注明出处:http://www.cnblogs.com/Delostik/p/3553114.html 目前已有[A B C D E] 例行吐槽:趴桌子上睡着了 [A. Genetic Engi ...
- 2017年网络空间安全技术大赛部分writeup
作为一个bin小子,这次一个bin都没做出来,我很羞愧. 0x00 拯救鲁班七号 具体操作不多说,直接进入反编译源码阶段 可以看到,只要2处的str等于a就可以了,而str是由1处的checkPass ...
- 【动态规划】loj#2485. 「CEOI2017」Chase
有意思的可做dp题:细节有点多,值得多想想 题目描述 在逃亡者的面前有一个迷宫,这个迷宫由 nnn 个房间和 n−1n-1n−1 条双向走廊构成,每条走廊会链接不同的两个房间,所有的房间都可以通过走廊 ...
- [JOY]1143 飘飘乎居士的约会
题目描述 又是美妙的一天,这天飘飘乎居士要和MM约会,因此他打扮的格外帅气.但是,因为打扮的时间花了太久,离约会的时间已经所剩无几. 幸运的是,现在飘飘乎居士得到了一张nm的地图,图中左上角是飘飘乎居 ...
- css兼容处理-hack
浏览器兼容之旅的第二站:各浏览器的Hack写法 Browser CSS Hacks Moving IE specific CSS into @media blocks Detecting browse ...
- 【java】 field 和 variable 区别及相关术语解释
Having said that, the remainder of this tutorial uses the following general guidelines when discussi ...