使用Jsoup解析和操作HTML
jsoup 简单介绍
jsoup 是一款 Java 的HTML 解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套很省力的API,可通过DOM。CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup的主要功能例如以下:
1. 从一个URL,文件或字符串中解析HTML。
2. 使用DOM或CSS选择器来查找、取出数据。
3. 可操作HTML元素、属性、文本。
jsoup是基于MIT协议公布的,可放心使用于商业项目。
jsoup 的主要类层次结构例如以下图所看到的:
接下来我们专门针对几种常见的应用场景举例说明 jsoup 是怎样优雅的进行 HTML 文档处理的。
文档输入
jsoup 能够从包含字符串、URL地址以及本地文件来载入 HTML 文档,并生成 Document 对象实例。
以下是相关代码:

// 直接从字符串中输入 HTML 文档
String html = "<html><head><title>开源中国社区</title></head>"
+ "<body><p>这里是 jsoup 项目的相关文章</p></body></html>";
Document doc = Jsoup.parse(html); // 从URL直接载入 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/").get();
String title = doc.title(); Document doc = Jsoup.connect("http://www.oschina.net/")
.data("query", "Java") //请求參数
.userAgent("I’m jsoup") //设置User-Agent
.cookie("auth", "token") //设置cookie
.timeout(3000) //设置连接超时时间
.post(); //使用POST方法訪问URL // 从文件里载入 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
请大家注意最后一种 HTML 文档输入方式中的 parse 的第三个參数,为什么须要在这里指定一个网址呢(尽管能够不指定,如第一种方法)?由于 HTML 文档中会有非常多比如链接、图片以及所引用的外部脚本、css文件等。而第三个名为 baseURL 的參数的意思就是当 HTML 文档使用相对路径方式引用外部文件时。jsoup 会自己主动为这些 URL 加上一个前缀。也就是这个 baseURL。
比如 <a href=/project>开源软件</a> 会被转换成 <a href=http://www.oschina.net/project>开源软件</a>。
解析并提取 HTML 元素
这部分涉及一个 HTML 解析器最主要的功能,但 jsoup 使用一种有别于其它开源项目的方式——选择器。我们将在最后一部分具体介绍 jsoup 选择器,本节中你将看到 jsoup 是怎样用最简单的代码实现。
只是 jsoup 也提供了传统的 DOM 方式的元素解析,看看以下的代码:
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
你可能会认为 jsoup 的方法似曾相识,没错,像 getElementById 和 getElementsByTag 方法跟 JavaScript 的方法名称是一样的,功能也全然一致。你能够依据节点名称或者是 HTML 元素的 id 来获取相应的元素或者元素列表。
与 htmlparser 项目不同的是,jsoup 并没有为 HTML 元素定义一个相应的类。一般一个 HTML 元素的组成部分包含:节点名、属性和文本,jsoup 提供简单的方法供你自己检索这些数据,这也是 jsoup 保持瘦身的原因。
而在元素检索方面,jsoup 的选择器简直无所不能,
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");//全部引用png图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这是 jsoup 真正让我折服的地方,jsoup 使用跟 jQuery 一模一样的选择器对元素进行检索,以上的检索方法假设换成是其它的 HTML 解释器,至少都须要非常多行代码,而 jsoup 仅仅须要一行代码就可以完毕。
jsoup 的选择器还支持表达式功能,我们将在最后一节介绍这个超强的选择器。
改动数据
在解析文档的同一时候,我们可能会须要对文档中的某些元素进行改动。比如我们能够为文档中的全部图片添加可点击链接、改动链接地址或者是改动文本等。
以下是一些简单的样例:
doc.select("div.comments a").attr("rel", "nofollow");
//为全部链接添加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
//为全部链接添加 class=mylinkclass 属性
doc.select("img").removeAttr("onclick"); //删除全部图片的onclick属性
doc.select("input[type=text]").val(""); //清空全部文本输入框中的文本
道理非常easy,你仅仅须要利用 jsoup 的选择器找出元素,然后就能够通过以上的方法来进行改动。除了无法改动标签名外(能够删除后再插入新的元素)。包含元素的属性和文本都能够改动。
改动完直接调用 Element(s) 的 html() 方法就能够获取改动完的 HTML 文档。
HTML 文档清理
jsoup 在提供强大的 API 同一时候,人性化方面也做得很好。在做站点的时候,常常会提供用户评论的功能。有些用户比較淘气。会搞一些脚本到评论内容中,而这些脚本可能会破坏整个页面的行为,更严重的是获取一些机要信息。比如 XSS 跨站点攻击之类的。
jsoup 对这方面的支持很强大,使用很easy。
看看以下这段代码:
String unsafe = "<p><a href='http://www.oschina.net/' onclick='stealCookies()'>开源中国社区</a></p>";
String safe = Jsoup.clean(unsafe, Whitelist.basic());
// 输出:
// <p><a href="http://www.oschina.net/" rel="nofollow">开源中国社区</a></p>
jsoup 使用一个 Whitelist 类用来对 HTML 文档进行过滤,该类提供几个经常用法:

假设这五个过滤器都无法满足你的要求呢,比如你同意用户插入 flash 动画,没关系,Whitelist 提供扩展功能。比如 whitelist.addTags("embed","object","param","span","div"); 也可调用 addAttributes 为某些元素添加属性。
jsoup 的过人之处——选择器
前面我们已经简单的介绍了 jsoup 是怎样使用选择器来对元素进行检索的。
本节我们把重点放在选择器本身强大的语法上。下表是 jsoup 选择器的全部语法具体列表。
基本使用方法

以上是最主要的选择器语法,这些语法也能够组合起来使用,以下是 jsoup 支持的组合使用方法:

除了一些主要的语法以及这些语法进行组合外,jsoup 还支持使用表达式进行元素过滤选择。以下是 jsoup 支持的全部表达式一览表:
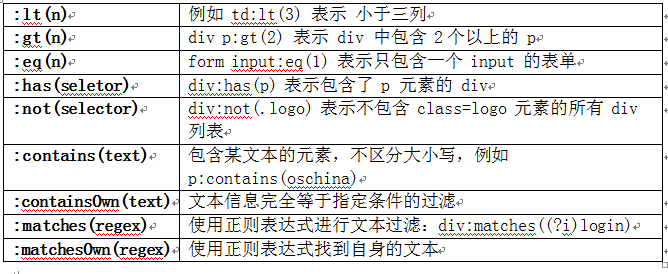
总结
jsoup 的基本功能到这里就介绍完成,但因为 jsoup 良好的可扩展性 API 设计,你能够通过选择器的定义来开发出很强大的 HTML 解析功能。
再加上 jsoup 项目本身的开发也很活跃,因此假设你正在使用 Java 。须要对 HTML 进行处理。最好还是试试。
以上摘自开源中国社区:http://www.oschina.net/question/12_14127
附:
jsoup在线API:jsoup 1.6.3 API
jsoup开发指南
使用Jsoup解析和操作HTML的更多相关文章
- jsoup解析HTML
Connection conn = Jsoup.connect(String url); conn.data("txtBill", key);// 设置关键字查询字段 Docume ...
- Jsoup 解析 HTML
Jsoup 文档 方法 要取得一个属性的值,可以使用Node.attr(String key) 方法 对于一个元素中的文本,可以使用Element.text()方法 对于要取得元素或属性中的HTML内 ...
- Jsoup解析HTML、加载文档等实例
一.引入jsoup的jar包:http://jsoup.org/download 补充:http://jsoup.org/apidocs/ Jsoup API 可以了解更详细的内容 二.Js ...
- 接口测试脚本之Jsoup解析HTML
第一次接触jsoup还是在处理收货地址的时候,当时在写一个下单流程,需要省市区id以及详细门牌号等等,因此同事介绍了jsoup,闲来无事,在此闲扯一番! 1.我们来看下,什么是jsoup,先来看看官方 ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- Android利用Jsoup解析html 开发网站客户端小记。
这些天业余时间比较多,闲来无事,想起了以前看过开发任意网站客户端的一篇文章,就是利用jsoup解析网站网页,通过标签获取想要的内容.好了废话不多说,用到的工具为 jsoup-1.7.2.jar包,具体 ...
- [java] jsoup 解析网页获取省市区域信息
到国家统计局抓取数据, 到该class下解析数据 /** * jsoup解析网页 * @author xwolf * @date 2016-12-13 18:11 * @since V1.0.0 */ ...
- jsoup解析HTML及简单实例
jsoup 中文参考文献 http://www.open-open.com/jsoup/ 本文将利用jsoup,简单实现网络抓取的功能,并给出一个小实例,该实例效果为:获取作者本人在博客园写的所 ...
- Android开发探秘之三:利用jsoup解析HTML页面
这节主要是讲解jsoup解析HTML页面.由于在android开发过程中,不可避免的涉及到web页面的抓取,解析,展示等等,所以,在这里我主要展示下利用jsoup jar包来抓取cnbeta.com网 ...
随机推荐
- Spring Boot (31) 数据验证
曾经参数的验证是这样的: public String test(User user){ if(user == null){ throw new NullPointerException("u ...
- springboot与dubbo整合遇到的坑
整合环境: dubbo 2.6.2 springboot 2.1.5 遇到的问题:服务一直无法注册到zookeeper注册中心 项目结构: 使用application.properties文件: 配置 ...
- fragment间的数据传递
今天我将要讲的是fragment间的数据是如何进行传递的.这里我将举个简单的例子. 首先要有个MainActivity,它托管了MainFragment,而MainFragment又托管了DatePi ...
- (转)解决office软件无法卸载也无法安装的顽固问题
原文地址 http://jingyan.baidu.com/article/f3ad7d0fcfe32509c3345bab.html 有时会出现office下载失败,然后又无法重新安装,导致offi ...
- HanLP自然语言处理包开源(包含源码)
支持中文分词(N-最短路分词.CRF分词.索引分词.用户自定义词典.词性标注),命名实体识别(中国人名.音译人名.日本人名.地名.实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换, ...
- Spartan6系列之Spartan6系列之芯片时钟资源深入详解
1. 时钟资源概述 时钟设施提供了一系列的低电容.低抖动的互联线,这些互联线非常适合于传输高频信号.最大量减小时钟抖动.这些连线资源可以和DCM.PLL等实现连接. 每一种Spartan-6芯片提 ...
- codeforces_459D_(线段树,离散化,求逆序数)
链接:http://codeforces.com/problemset/problem/459/D D. Pashmak and Parmida's problem time limit per te ...
- CAD控件:COM接口实现自定义实体
1. 实现步骤: 3 1. 实现步骤: 参考例子 :Src\MxDraw5.2\samples\ie\iedemoTest.htm 1) 增加自定义实体对象 调用DrawCustomEntity函数, ...
- Java基础(五)--内部类
内部类简单来说就是把一个类的定义放到另一个类的定义内部 内部类分为:成员内部类.局部内部类.匿名内部类.静态内部类 成员内部类:最常见的内部类 public class Outter { privat ...
- 用Docker构建Tomcat镜像
构建tomcat镜像 创建工作目录 [root@elk-node2 tomcat]# mkdir tomcat [root@elk-node2 tomcat]# cd tomcat [root@elk ...