Mysql中分页查询两个方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下
|
1
2
3
|
SELECT COUNT(*) FROM foo WHERE b = 1;SELECT a FROM foo WHERE b = 1 LIMIT 100,10; |
|
1
|
|
另外一种是使用SQL_CALC_FOUND_ROWS
|
1
2
|
SELECT SQL_CALC_FOUND_ROWS a FROM foo WHERE b = 1 LIMIT 100, 10;SELECT FOUND_ROWS(); |
第二种方式调用SQL_CALC_FOUND_ROWS之后会将WHERE语句查询的行数放在FOUND_ROWS()之中,第二次只需要查询FOUND_ROWS()就可以查出有多少行了。
讨论这两种方法的优缺点:
首先原子性讲,第二种肯定比第一种好。第二种能保证查询语句的原子性,第一种当两个请求之间有额外的操作修改了表的时候,结果就自然是不准确的了。而第二种则不会。但是非常可惜,一般页面需要进行分页显示的时候,往往并不要求分页的结果非常准确。即分页返回的total总数大1或者小1都是无所谓的。所以其实原子性不是我们分页关注的重点。
下面看效率。这个非常重要,分页操作在每个网站上的使用都是非常大的,查询量自然也很大。由于无论哪种,分页操作必然会有两次sql查询,于是就有很多很多关于两种查询性能的比较:
SQL_CALC_FOUND_ROWS真的很慢么?
http://hi.baidu.com/thinkinginlamp/item/b122fdaea5ba23f614329b14
To SQL_CALC_FOUND_ROWS or not to SQL_CALC_FOUND_ROWS?
http://www.mysqlperformanceblog.com/2007/08/28/to-sql_calc_found_rows-or-not-to-sql_calc_found_rows/
老王这篇文章里面有提到一个covering index的概念,简单来说就是怎样才能只让查询根据索引返回结果,而不进行表查询
具体看他的另外一篇文章:
MySQL之Covering Index
http://hi.baidu.com/thinkinginlamp/item/1b9aaf09014acce0f45ba6d3
实验
结合这几篇文章,做的实验:
表:
|
1
2
3
4
5
6
7
|
CREATE TABLE IF NOT EXISTS `foo` (`a` int(10) unsigned NOT NULL AUTO_INCREMENT,`b` int(10) unsigned NOT NULL,`c` varchar(100) NOT NULL,PRIMARY KEY (`a`),KEY `bar` (`b`,`a`)) ENGINE=MyISAM; |
注意下这里是使用b,a做了一个索引,所以查询select * 的时候是不会用到covering index的,select a才会使用到covering index
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
<?php$host = '192.168.100.166';$dbName = 'test';$user = 'root';$password = '';$db = mysql_connect($host, $user, $password) or die('DB connect failed');mysql_select_db($dbName, $db);echo '==========================================' . "\r\n";$start = microtime(true);for ($i =0; $i<1000; $i++) { mysql_query("SELECT SQL_NO_CACHE COUNT(*) FROM foo WHERE b = 1"); mysql_query("SELECT SQL_NO_CACHE a FROM foo WHERE b = 1 LIMIT 100,10");}$end = microtime(true);echo $end - $start . "\r\n";echo '==========================================' . "\r\n";$start = microtime(true);for ($i =0; $i<1000; $i++) { mysql_query("SELECT SQL_NO_CACHE SQL_CALC_FOUND_ROWS a FROM foo WHERE b = 1 LIMIT 100, 10"); mysql_query("SELECT FOUND_ROWS()");}$end = microtime(true);echo $end - $start . "\r\n";echo '==========================================' . "\r\n";$start = microtime(true);for ($i =0; $i<1000; $i++) { mysql_query("SELECT SQL_NO_CACHE COUNT(*) FROM foo WHERE b = 1"); mysql_query("SELECT SQL_NO_CACHE * FROM foo WHERE b = 1 LIMIT 100,10");}$end = microtime(true);echo $end - $start . "\r\n";echo '==========================================' . "\r\n";$start = microtime(true);for ($i =0; $i<1000; $i++) { mysql_query("SELECT SQL_NO_CACHE SQL_CALC_FOUND_ROWS * FROM foo WHERE b = 1 LIMIT 100, 10"); mysql_query("SELECT FOUND_ROWS()");}$end = microtime(true);echo $end - $start . "\r\n"; |
返回的结果:
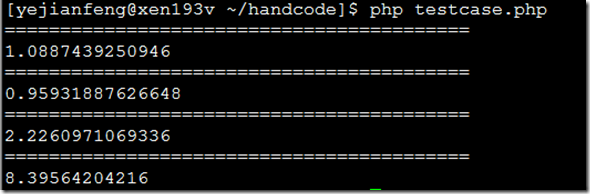
和老王里面文章说的是一样的。第四次查询SQL_CALC_FOUND_ROWS由于不仅是没有使用到covering index,也需要进行全表查询,而第三次查询COUNT(*),且select * 有使用到index,并没进行全表查询,所以有这么大的差别。
总结
PS: 另外提醒下,这里是使用MyISAM会出现三和四的查询差别这么大,但是如果是使用InnoDB的话,就不会有这么大差别了。
所以我得出的结论是如果数据库是InnoDB的话,我还是倾向于使用SQL_CALC_FOUND_ROWS
结论:SQL_CALC_FOUND_ROWS和COUNT(*)的性能在都使用covering index的情况下前者高,在没使用covering index情况下后者性能高。所以使用的时候要注意这个。
原文 http://www.cnblogs.com/yjf512/archive/2012/10/09/2717102.html#undefined
Mysql中分页查询两个方法比较的更多相关文章
- mysql中有关查询的技巧方法
* 查最高值或者最低值对应行的数据: 查询Score表中的最高分的学生学号和课程号: 两种方法(子查询或者排序): 子查询法:select sno,cno from score where degre ...
- MYSQL的慢查询两个方法
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MYSQL的慢查询以及没有得用索引的查询. ================================================== ...
- Oracle中的SQL分页查询原理和方法详解
Oracle中的SQL分页查询原理和方法详解 分析得不错! http://blog.csdn.net/anxpp/article/details/51534006
- 【spring boot】14.spring boot集成mybatis,注解方式OR映射文件方式AND pagehelper分页插件【Mybatis】pagehelper分页插件分页查询无效解决方法
spring boot集成mybatis,集成使用mybatis拖沓了好久,今天终于可以补起来了. 本篇源码中,同时使用了Spring data JPA 和 Mybatis两种方式. 在使用的过程中一 ...
- mybatis中分页查询
1 如果在查询方法中有多个参数,可以使用map对象将所有数据都存储进去.比如分页查询,需要用到两个参数,可以将这两个参数包装到map中. 例子:分页查询 dao层方法 public List<S ...
- 【原创】7. MYSQL++中的查询结果获取(各种Result类型)
在本节中,我将首先介绍MYSQL++中的查询的几个简单例子用法,然后看一下mysqlpp::Query中的几个与查询相关的方法原型(重点关注返回值),最后对几个关键类型进行解释. 1. MYSQL++ ...
- Oracle和MySql的分页查询区别和PL/SQL的基本概念
Oracle和MySql的分页查询区别: Oracle的分析查询,之前Oracle的分页是使用伪列 ROWNUM 结合子查询实现,mysql的分页更简单,直接使用 LIMIT 关键字就可以实现 ...
- 【面经】面试官:如何以最高的效率从MySQL中随机查询一条记录?
写在前面 MySQL数据库在互联网行业使用的比较多,有些小伙伴可能会认为MySQL数据库比较小,存储不了很多的数据.其实,这些小伙伴是真的不了解MySQL.MySQL的小不是说使用MySQL存储的数据 ...
- mysql中模糊查询的四种用法介绍
下面介绍mysql中模糊查询的四种用法: 1,%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示. 比如 SELECT * FROM [user] ...
随机推荐
- span-wise drag/lift forces of cylinder
span-wise drag/lift forces of cylinder SR Description: Dear Sir/Madam, I am trying to simulate a 3 ...
- C语言学习8
计算某日是该年的第几天 编写一个计算天数的程序,用户从键盘输入年.月.日,在屏幕中输出此日期是该年的第几天. /******************************************** ...
- Thawte SSL Web Server 多域型SSL证书
Thawte SSL Web Server 多域型SSL证书,最多支持25个域名,需要验证域名所有权和申请单位信息,属于企业验证型SSL证书,提供40位/56位/128位,最高支持256位自适应加密. ...
- 慕课笔记利用css进行布局【混合布局】
<html> <head> <title>混合布局学习</title> <style type="text/css"> ...
- 九度oj 题目1060:完数VS盈数
题目1060:完数VS盈数 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:6461 解决:2426 题目描述: 一个数如果恰好等于它的各因子(该数本身除外)子和,如:6=3+2+1.则称其 ...
- 九度oj 题目1023:EXCEL排序
题目1023:EXCEL排序 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:20699 解决:4649 题目描述: Excel可以对一组纪录按任意指定列排序.现请你编写程序实现类似 ...
- 南邮CTF密码学,mixed_base64
# -*- coding:utf-8 -*- from base64 import * flag = open("code.txt").readline() # 读取密文 for ...
- hdu 4091 数学思维题贪心
/* 参看博客地址:http://blog.csdn.net/oceanlight/article/details/7857713 重点是取完最优的后剩余的rest=n%lcm+lcm;中性价比小的数 ...
- POJ 3415 (后缀自动机)
POJ 3415 Common Substrings Problem : 给两个串S.T (len <= 10^5), 询问两个串有多少个长度大于等于k的子串(位置不同也算). Solution ...
- ssh远程登录
ssh root@192.168.124.128 密钥登录: 1).ssh-keygen 生成公钥和私钥 [root@rhel5 ~]# ssh-keygen -t rsa Generating pu ...