HBase在大搜车金融业务中的应用实践
摘要: 2017云栖大会HBase专场,大搜车高级数据架构师申玉宝带来HBase在大搜车金融业务中的应用实践。本文主要从数据大屏开始谈起,进而分享了GPS风控实践,包括架构、聚集分析等,最后还分享了流式数据统计,包括数据流、数据合流和服务监控等。
2017云栖大会HBase专场,大搜车高级数据架构师申玉宝带来HBase在大搜车金融业务中的应用实践。本文主要从数据大屏开始谈起,进而分享了GPS风控实践,包括架构、聚集分析等,最后还分享了流式数据统计,包括数据流、数据合流和服务监控等。
以下是精彩内容整理:
数据大屏实践
最近几年二手车业务发展非常迅猛,大搜车一直做B端的业务,我们在B端里面4S店的市场占有率已经达到90%以上。今年年初我们觉得时机成熟了,我们就做了弹个车,它是比较典型的汽车金融。无论是车商业务,还是金融业务,都对我们数据采集、数据整理、数据使用提出了非常多的挑战。而HBase性能比较稳定,也可以水平拓展,很好地支撑了我们的业务。
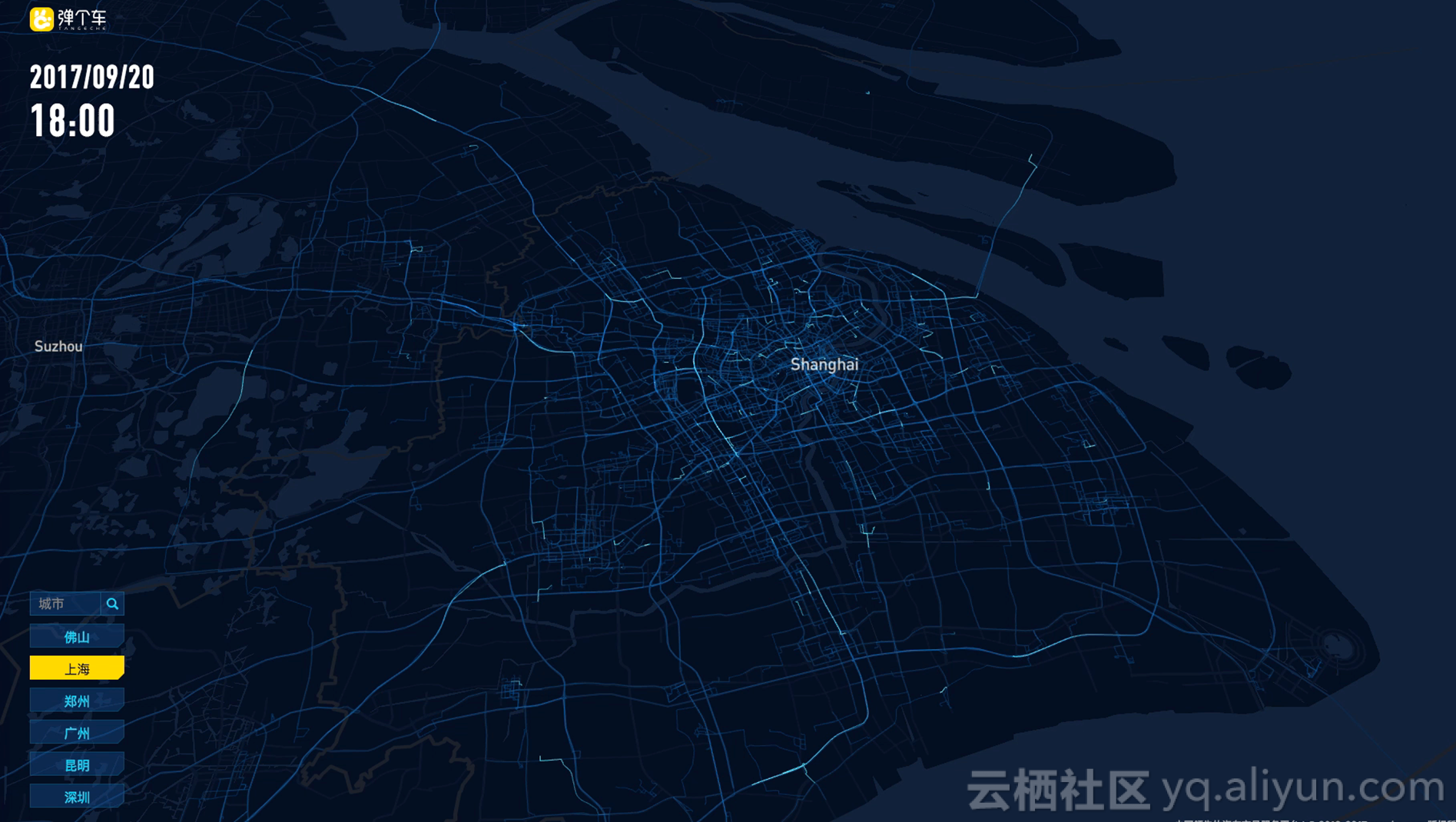
图为我们其中一个数据大屏,它是上海地区弹个车业务一个小时以内的行驶轨迹,看起来还是比较震撼的。该大屏还有一个配置的页面,用户可以选择时间、城市,业务同学可以自己配备报表,方便他们对外做一些商务事务。
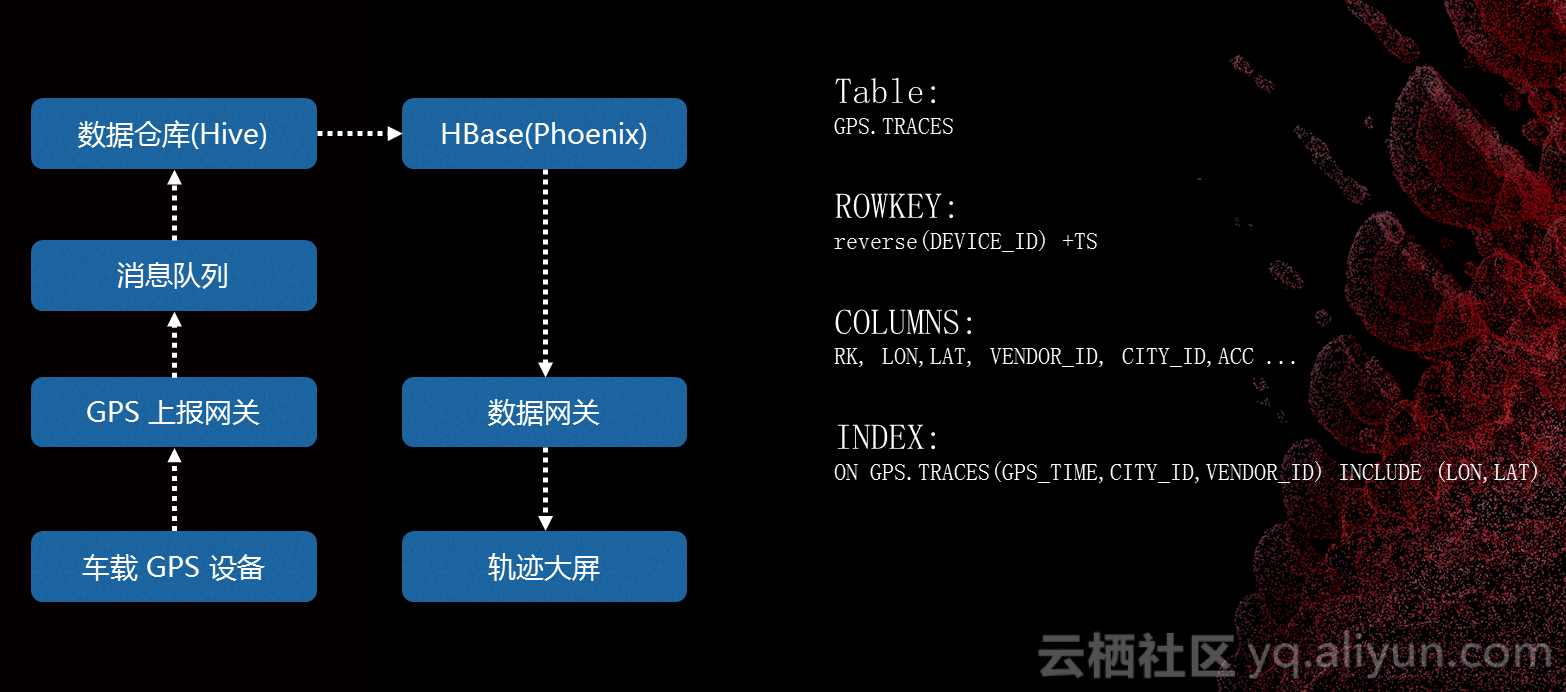
我们看一下报表是如何实现的。这个报表的数据源来自车载GPS设备,GPS设备会定时上报一些数据,包括精度、纬度、点火状态的数据,这些数据会先经过GPS上报,会做状态的管理、里程,之后生成想要的报表,数据到达终点。这个数据会通过数据网关,数据网关是对外提供产品都要经过的地方,并且会进行系统跟踪等。车载设备上传各种的基础数据会存到GPS。针对这个场景,我们根据时间、城市来查数据,所以我们要对报表单独建立一个索引。因为我们在查数据的时候,这个场景只需要精度和纬度,这样在查数据的时候直接在索引中就可以完成所有数据查询,不用再回主表,大大减少了产品的耗时。
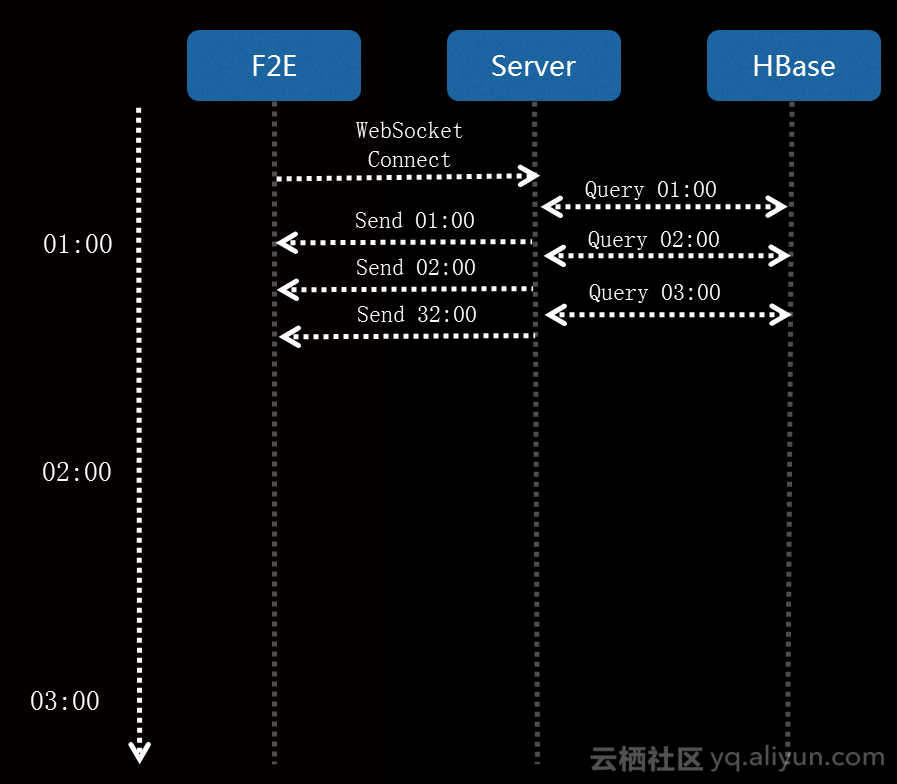
我们在报表的应用层也做了一些优化,大屏里面是该地区所有车辆轨迹,这个数据量是非常巨大的,如果直接浏览就会卡死,所以我们首先做了分片。刚开始只查询一个小时的少量数据,这个数据拿到以后开始渲染,数据请求下一时间段的数据,前端渲染是不停的,后端数据也一直往上堆积,所以我们在打开页面的时候可以立即开始整个页面的展示。另外,因为数据传输非常频繁,使用Websocket减少建立 HTTP 请求耗时。
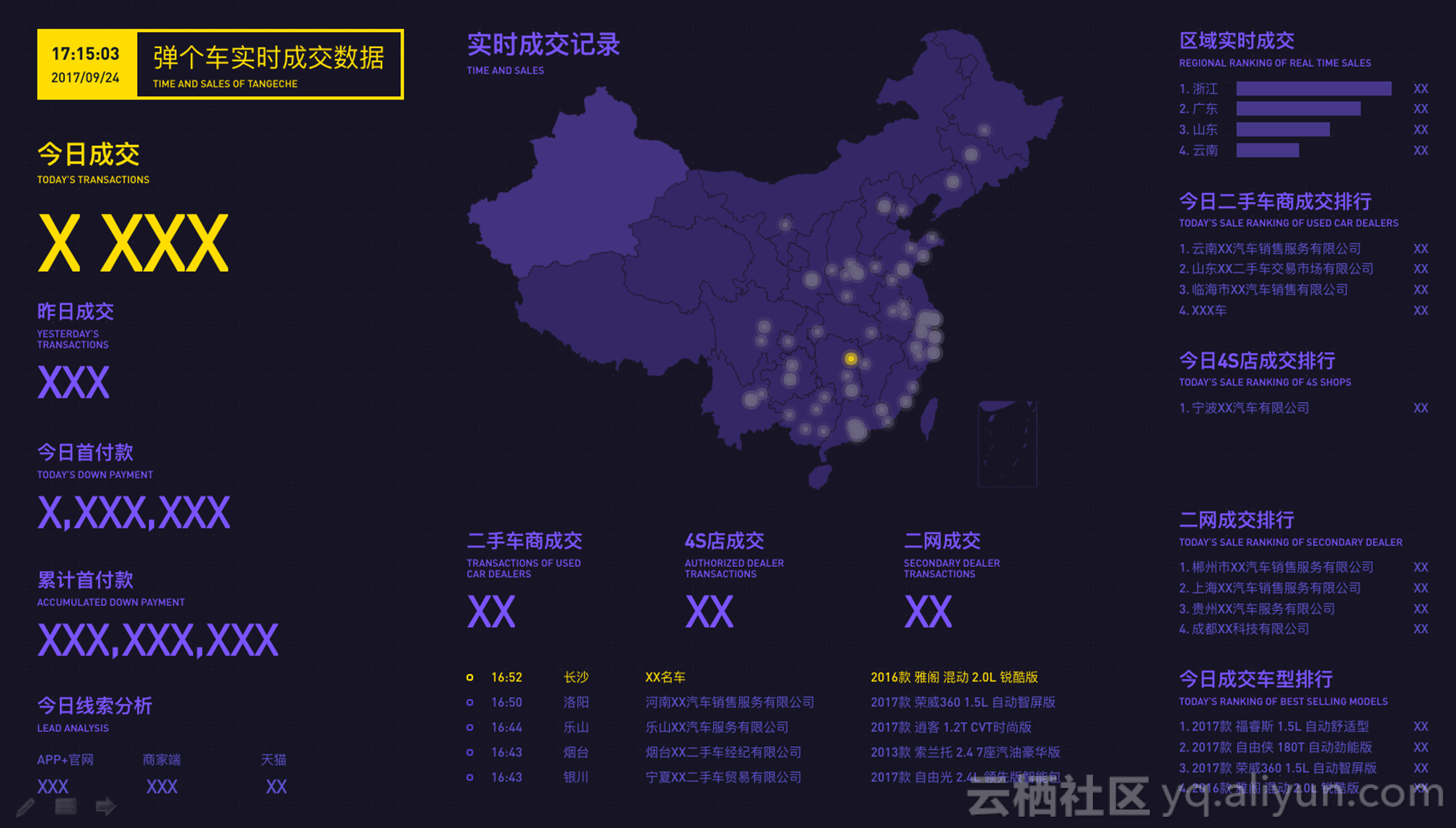
刚才的大屏是离线大屏,而现实中实时业务大屏非常常见,这是弹个车实时成交数据大屏。大屏数据来自我们的业务埋点日志,大屏当中也会用到基础的纬度数据,我们直接拉到了MySQL,我们内部的计算框架会根据MQ进行数据的处理,组装成我们需要的数据,放到终点Phoenix当中。
GPS风控实践
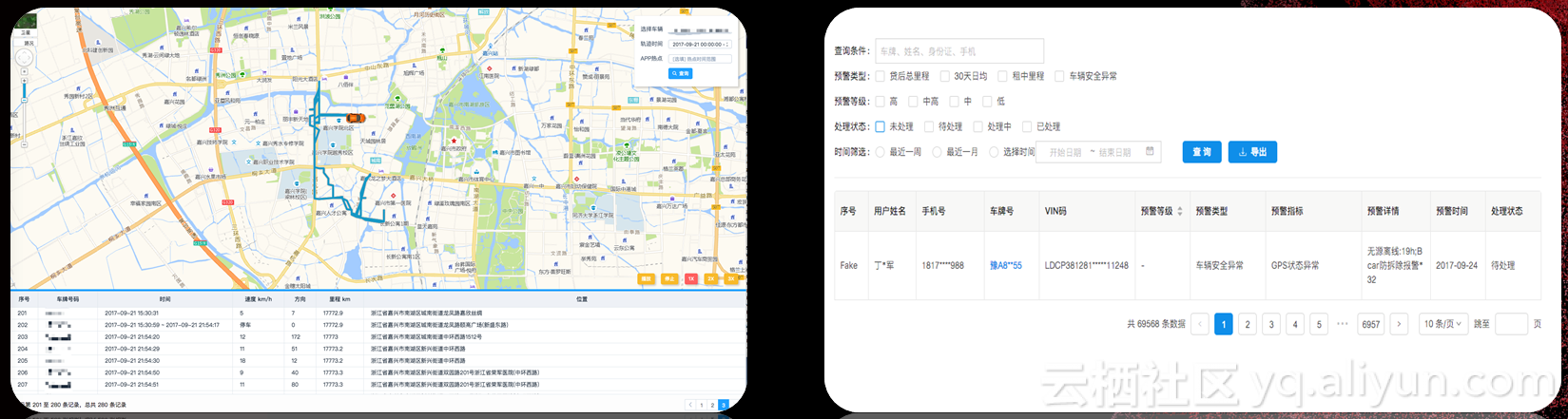
对汽车金融来说风控是生命线,如果风控搞不好分分钟就会破产。我们有一个轨迹监控大屏,通过时间和车辆可以察看车辆在一段时间内的型式轨迹,它的速度、地理位置,还有后台可以设置一些风险区域,比如澳门赌场等正常用户应该不会去的地方,这些地方出没的会有一些贷款风险。还有风控模型,GPS里面会把各种数据统计为模型特征,再交给模型,最后由风控引擎针对这些线上数据判定有没有特征,发出报警。
业务架构
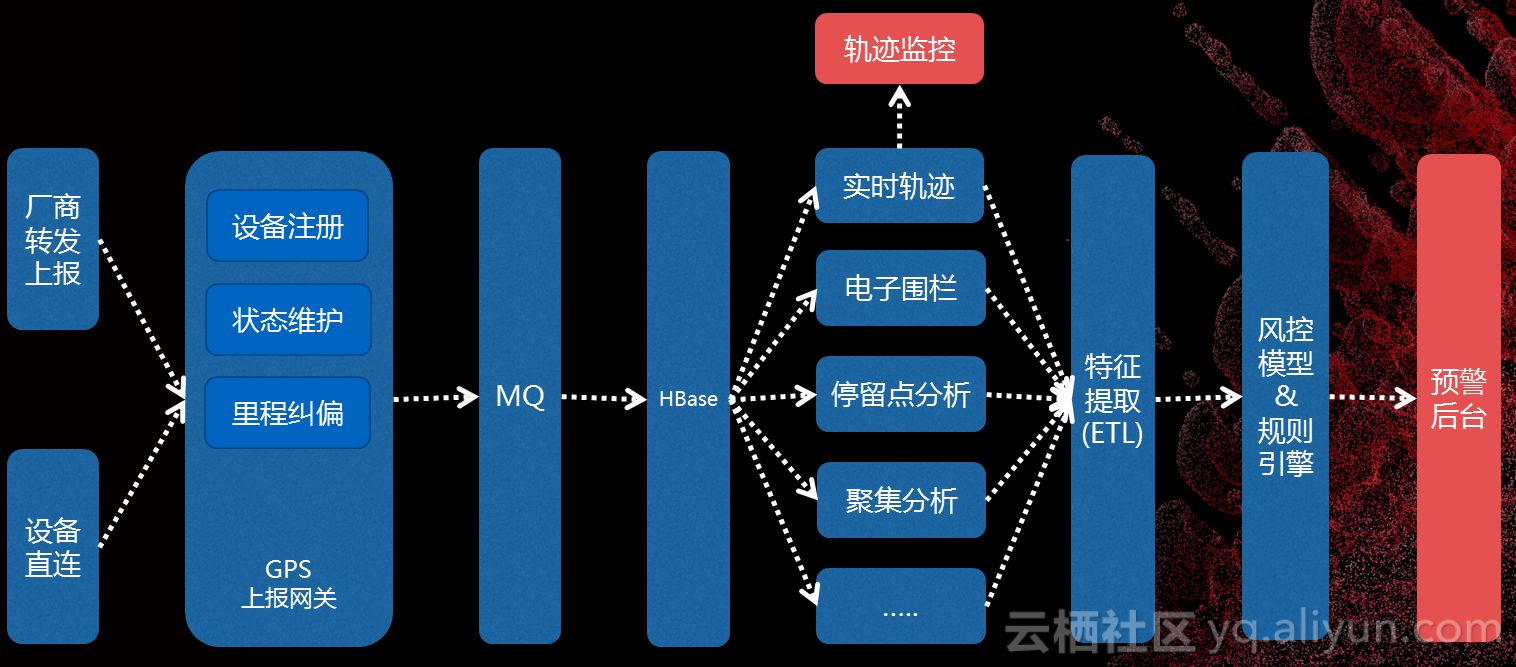
最早设备是来自厂商上报的,后来因为对接的厂商比较多,发现了一些故障。我们上报到网关,包括设备注册、状态维护、里程纠偏,设计运营环境非常复杂,有可能这辆车没有电了,里面存储的数据没有了,也有可能跑到非常偏远的地方,没有办法上报数据,还有一些上报的里程非常奇怪,本来是两万多,突然变成一万,表现在数据上可能会是非常诡异的点,。针对这部分,我们做了一些清洗,比如说偏移,我们会根据前后一些点的关系做一些数据的过滤。还有里程纠偏,我们对时间做了一些分片,每分钟都会有一个点,我们会统计这分钟结束时间减去起始,计算出真正的里程,可以对这块数据作出处理,对一天的影响就非常小。我们在这里花了大量的精力,一大半时间都在清洗数据。
接下来数据通过MQ到HBase,实时轨迹、电子围栏、停留点分析、聚焦分析,这些数据会和材料验证一块提供给我们的贷后运维同学来判断风险。我们发现很多骗贷的并不是个人,而是一些机构,有些村子都是骗贷的团伙,有些是负责伪造材料,有些是负责申请贷款,我们针对这些场景,把每个车的具体情况分析出来,因为正常是面向C端用户,不应该大量车聚焦在一个地方。最后这些数据进入到预警后台。
聚集分析
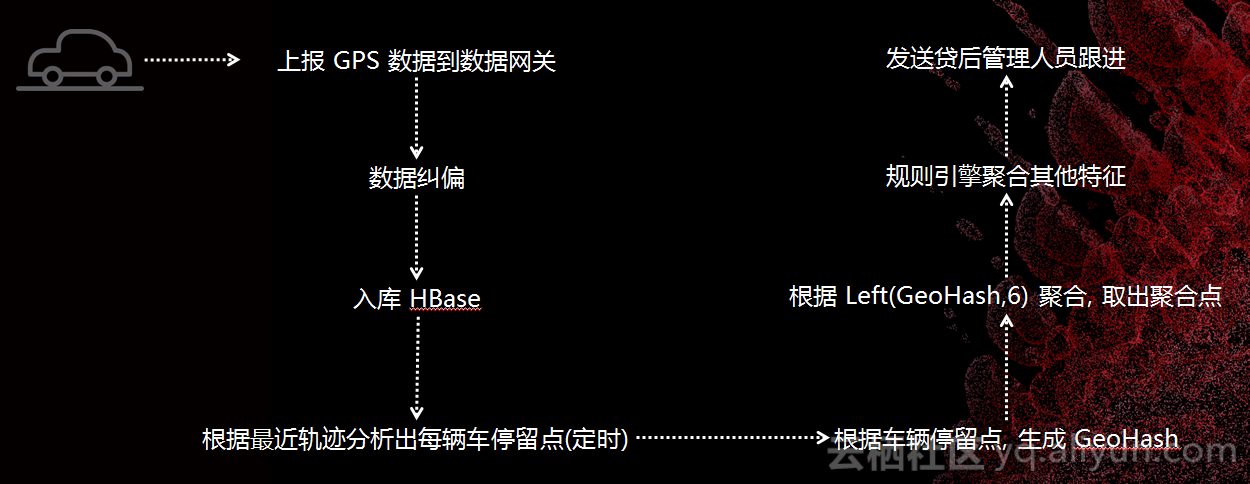
使用GeoHash先对地球进行二维平面化,把地球分成好多个区域,对每一个区域再分成32个区域,不断地细分,让一个区域不断地精确。Base32编码字符串,每个字符由5bit 组成。将每辆车的停留点算出来,再把停留点算出GeoHash值,按照这些区域聚合好选择聚合的点,算出每一个点到底有多少辆车,最后形成一个特征,生成模型。
数据存储部分,原始轨迹支持按设备、时间维度查询详细轨迹,查聚集点按区域、时间维度查询聚集数据。
流式数据统计
有些车辆列表大家看到的并不是动态的,会根据流量数量、地理位置来决定一个智能点的排序,这就需要很多特征、流式计算的场景。全国实时车交数据和报表,产品经理都比较人性化,所有数据都想立刻在报表里面更新,所以这些也是我们主要的场景。
这些业务特点:
- 实时数据间隔非常短,我们会要求10秒或者5秒的时间窗口就要更新过来;
- 数据量比较大,我们遇到了一些百万兆、亿兆的;
- 这些场景还有并发要求,毕竟是线上业务,我们是一个B端业务,所以对内部要求还没有太高,100QPS就可以满足我们这个阶段的要求;
- 业务变化非常快,如果一个需求真的做一个月,做完了以后规则就变了,所以查询纬度很多、变化很大,针对这些我们会细分一些性能,然后提高开放的速度。
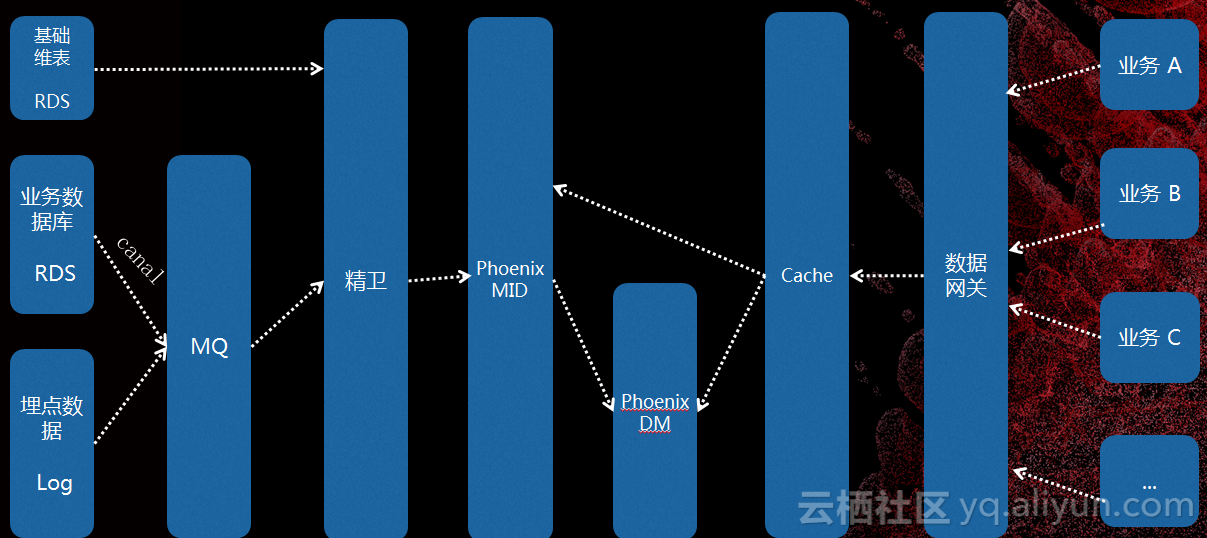
这是数据流,最多的数据还是来自RDS,把数据库的各种数据变更转化成MQ消息,再加上以前还有很多埋点消息都会统一到MQ。所有数据会在我们计算框架里面聚合起来,按照我们的业务场景把它放在Phoenix里面,先放到明细数据。我们针对每个场景单独聚合好,可以直接查询。还有一些场景计算量很大,会有一些统计数据,以此来支撑我们的线上业务。A、B、C业务通过数据网关来访问数据。
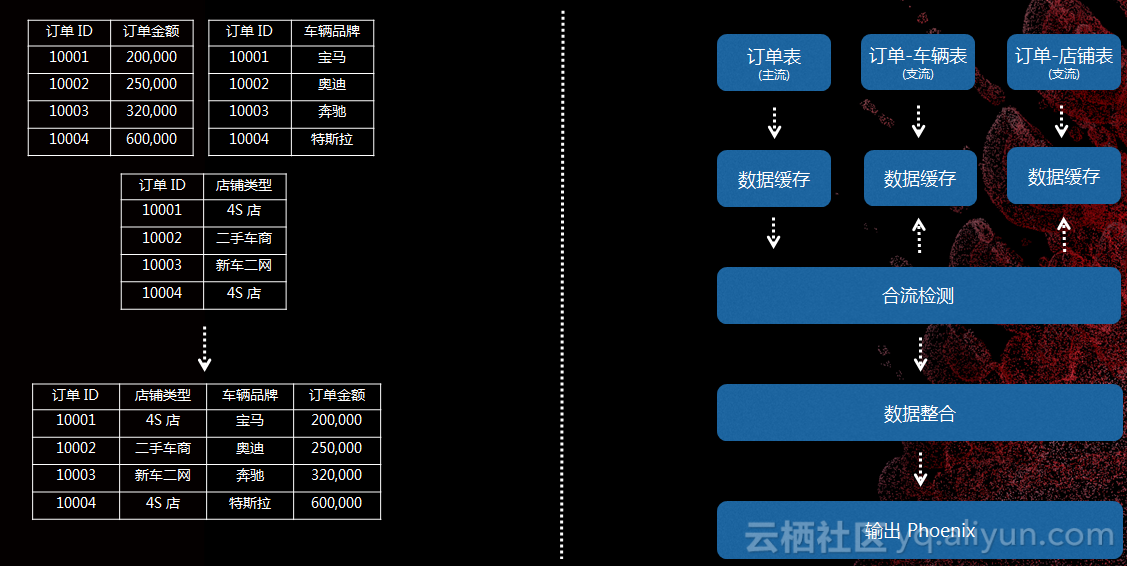
数据合流是我们现在遇到的比较大的问题,有一个定单表,里面有金额、品牌等等,需要把所有数据合并到一起提供服务,对流式处理来说这个问题非常棘手,因为数据是流式到达的,而且到达是无序的。我们也做了一些处理,对每一个处理流里面立一个表为主表,每次数据到达的时候会有一个监测模块,看是否符合合流条件,会从库里面检查数据是否真的到达了,按照业务规则组合数据。这里也要做优化,并不是直接查,是要经过数据缓存。
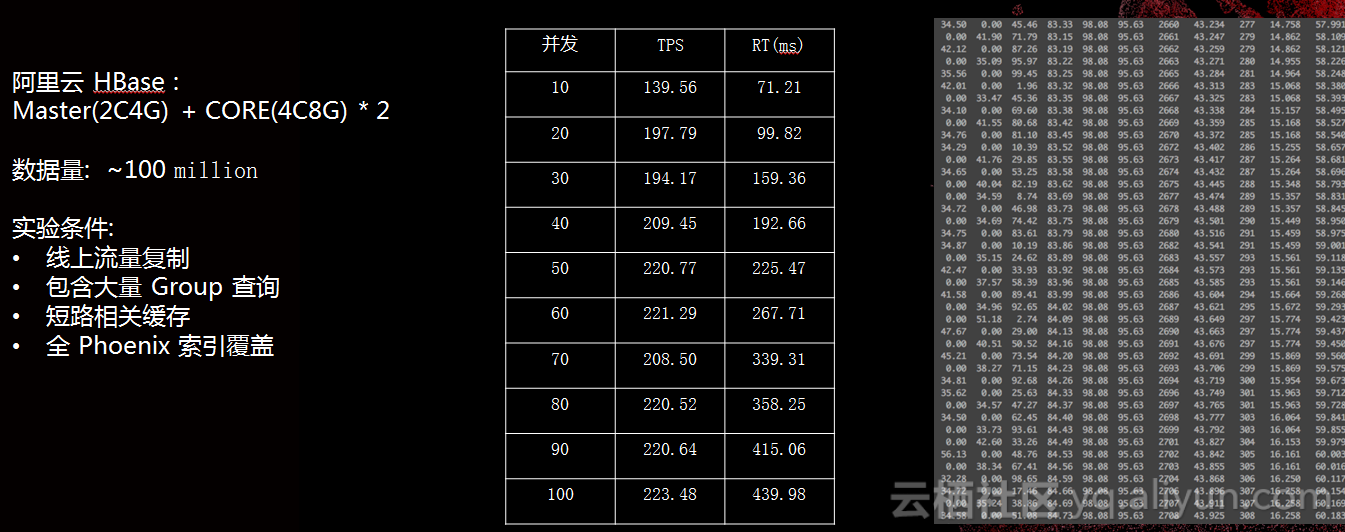
性能测试方面我们找最低配的集群,Master(2C4G)+CORE(4C8G)×2,数据量:—100Million,这对我们场景来说已经绰绰有余,再加上Phoenix性能的拓展非常方便。这些性能测试其实跟性能条件关系非常大,这只是我们内部的测试,更标准的数据还要参考官方的数据。
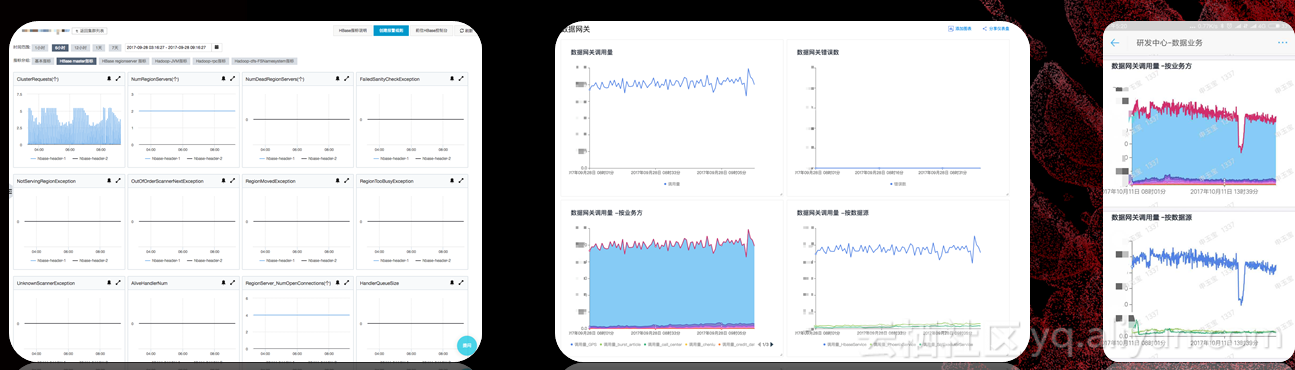
服务监控上,流式和离线不太一样,流式数据一天24小时在线,所以它的稳定性非常重要,不能跑着跑着就挂了。阿里云后台本身的监控可以看到一些机器的信息。另外,我们内部开发了一套业务监控系统,我们所有请求都是通过数据网关,数据网关的重要功能就是整个服务的监控,它每次访问都会记一个日志,日志里面有访问的数量、访问的时间,按表来查,这样对我们查询问题帮助非常大。另外,我们业务监控系统也有移动版,以前出什么问题在公交车上都得拿出电脑,现在直接在移动端里查,比较方便。
交流
如果大家对HBase有兴趣,致力于使用HBase解决实际的问题,欢迎加入Hbase技术社区群交流:
微信HBase技术社区群,假如微信群加不了,可以加秘书微信: SH_425 ,然后邀请您。

钉钉HBase技术社区群

HBase在大搜车金融业务中的应用实践的更多相关文章
- 车架号VIN码识别,合格证,购车发票,房产证,车牌,驾驶证,行驶证,征信报告等等识别 从易鑫、大搜车、淘车网,看汽车金融发展新模式
随着我国汽车保有量和产销量的持续增长,汽车技术的日趋成熟,以及互联网+对汽车行业的不断影响,汽车金融的市场规模逐步扩大,市场主体逐步丰富,汽车金融模式也在不断演进. 2016年左右,美国主要汽车厂商通 ...
- 回客科技 面试的 实现ioc 容器用到的技术,简述BeanFactory的实现原理,大搜车面试的 spring 怎么实现的依赖注入(DI)
前言:这几天的面试,感觉自己对spring 的整个掌握还是很薄弱.所以需要继续加强. 这里说明一下spring的这几个面试题,但是实际的感觉还是不对的,这种问题我认为需要真正读了spring的源码后说 ...
- 大搜车知乎live中的面试题结题方法记录
1.HTML&CSS(分别10分) 1. 一个div,宽度是100px,此时设置padding是20px,添加一个什么css属性可以让div的实际宽度仍然保持在100px,而不是140px? ...
- Java线程池实现原理及其在美团业务中的实践
本文转载自Java线程池实现原理及其在美团业务中的实践 导语 随着计算机行业的飞速发展,摩尔定律逐渐失效,多核CPU成为主流.使用多线程并行计算逐渐成为开发人员提升服务器性能的基本武器.J.U.C提供 ...
- Java线程池实现原理及其在美团业务中的实践(转)
转自美团技术团队:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html 随着计算机行业的飞速发展,摩尔定律逐 ...
- Nebula Graph 在网易游戏业务中的实践
本文首发于 Nebula Graph Community 公众号 当游戏上知识图谱,网易游戏是如何应对大规模图数据的管理问题,Nebula Graph 又是如何帮助网易游戏落地游戏内复杂的图的业务呢? ...
- 区块链Fabric技术在托管业务中的运用初探
区块链Fabric技术在托管业务中的运用初探 什么是Fabric技术 HyperLedger是IBM.Intel等多家公司正开展的一个区块链项目,包含了Fabric.Iroha等多项技术,其中最为活跃 ...
- HBase常见问题答疑解惑【持续更新中】
HBase常见问题答疑解惑[持续更新中] 本文对HBase开发及使用过程中遇到过的常见问题进行梳理总结,希望能解答新加入的HBaser们的一些疑惑. 1. HTable线程安全吗? HTable不是线 ...
- redis整合Spring集群搭建及业务中的使用
1.redis安装 Redis是c语言开发的. 安装redis需要c语言的编译环境.如果没有gcc需要在线安装.yum install gcc-c++ 安装步骤: 第一步:redis的源码包上传到li ...
随机推荐
- java io-----转
https://blog.csdn.net/zch19960629/article/details/77917739 输入输出的重要性: 输入和输出功能是Java对程序处理数据能力的提高,Ja ...
- 【HIHOCODER 1605】小Hi的生成树计数
描述 小Hi最近对生成树(包含所有顶点的联通无环子图.)非常的感兴趣,他想知道对于特定的简单平面无向图是不是存在求生成树个数的简单方法. 小Hi定义了这样的图:一个以{0,1,2--n}为顶点的图,顶 ...
- 【HDU 6008】Worried School(模拟)
Problem Description You may already know that how the World Finals slots are distributed in EC sub-r ...
- MyBatis 3 学习
MyBatis是一款优秀的持久化框架,支持定制化SQL.存储过程以及高级映射.MyBatis避免了几乎所有的JDBC代码和手动设置参数以及获得结果集.MyBatis可以使用简单的XML或注解来配置和映 ...
- python接口自动化-token参数关联登录(登录拉勾网)
前言 登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了 登录拉勾网 1.先找到登录首页https://pa ...
- 省市区名称code
https://blog.csdn.net/hichinamobile/article/details/51725090 --省 create table t_base_provinces( id ) ...
- hdu 3879 最大权闭合图(裸题)
/* 裸的最大权闭合图 解:参见胡波涛的<最小割模型在信息学竞赛中的应用 #include<stdio.h> #include<string.h> #include< ...
- C#高级编程第9版 第二章 核心C# 读后笔记
System命名空间包含了最常用的.NET类型.对应前面第一章的.NET基类.可以这样理解:.NET类提供了大部分的功能,而C#语言本身是提供了规则. pseudo-code,哈哈,秀逗code.伪代 ...
- [HDU4607]Park Visit(树上最长链)
HDU#4607. Park Visit 题目描述 Claire and her little friend, ykwd, are travelling in Shevchenko's Park! T ...
- mybatis结合generator进行分页插件PluginAdapter开发
使用org.mybatis.generator生成UserExample时,无法进行分页,使用下面这个类运行generator便可以生成分页相关的属性了 package org.mybatis.gen ...