Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的)。想要开发UDF程序,需要继承org.apache.hadoop.ql.exec.UDF类,并重载evaluate方法。Hive API提供@Description声明,使用声明可以在代码中添加UDF的具体信息。在Hive中可以使用DESCRIBE语句来展现这些信息。
Hive的源码本身就是编写UDF最好的参考资料。在Hive源代码中很容易就能找到与需求功能相似的UDF实现,只需要复制过来,并加以适当的修改就可以满足需求。
下面是一个具体的UDF例子,该例子的功能是将字符串全部转化为小写字母
package com.madhu.udf;
import org.apache.hadoop.hive.ql.exec.Desription;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
//add jar samplecode.jar;
//create temporary function to_upper as 'com.madhu.udf.UpercaseUDF';
@Desription(
name="to_upper",
value="_FUNC_(str) -Converts a string to uppercase",
extended="Example:\n" +
" > select to_upper(producer) from videos_ex;\n" +
" JOHN MCTIERNAN"
)
public class UpercaseUDF extends UDF{
public Text evaluate(Text input){
Text result = new Text("");
if (input != null){
result.set(input.toString().toUpperCase());
}
return result;
}
}
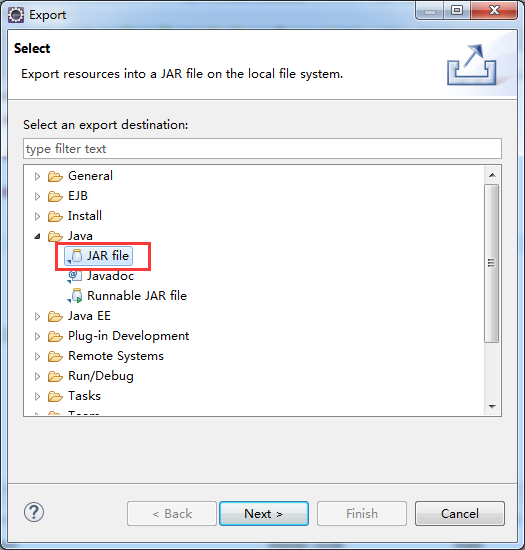
UDF只有加入到Hive系统路径,并且使用唯一的函数名注册后才能在Hive中使用。UDF应该被打成JAR包。
上传打好的 samplecode.jar,然后如下
下面的语句可以把JAR条件放入Hive系统路径,并注册相关函数:
hive > add jar samplecode.jar 这个目录,根据自己的情况而定
Added samplecode.jar to class path
Added resource:samplecode.jar
hive> create temporary function to_upper as 'com.madhu.udf.UppercaseUDF';
现在可以在Hive中使用这个函数了:
hive > describe function to_upper;
OK
to_upper(str) -Converts a string to uppercase
Time taken:0.039 seconds,Fetched:1 row(s)
hive > describe function extended to_upper;
OK
to_upper(str) - Converts a string to uppercase
Example:
> select to_upper(producer) from videos_ex;
JOHN MCTIERNAN
Time taken:0.07 seconds,Fetched:4 row(s)
手动的话,见
3 hql语法及自定义函数 + hive的java api
自动的话,见
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)

这里,我自己写了一个hiveEvaluateUDF 自定义函数,实现某一个我们自己想要的功能。比如,我这里是转换功能。开始编写代码
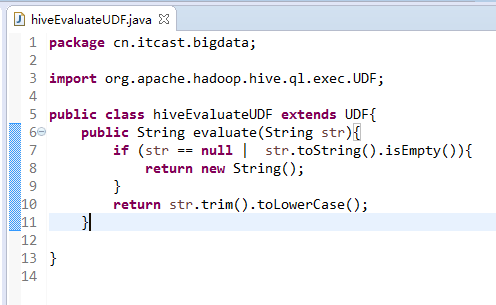
package cn.itcast.bigdata;
import org.apache.hadoop.hive.ql.exec.UDF;
public class hiveEvaluateUDF extends UDF{
public String evaluate(String str){
if (str == null | str.toString().isEmpty()){
return new String();
}
return str.trim().toLowerCase();
}
}
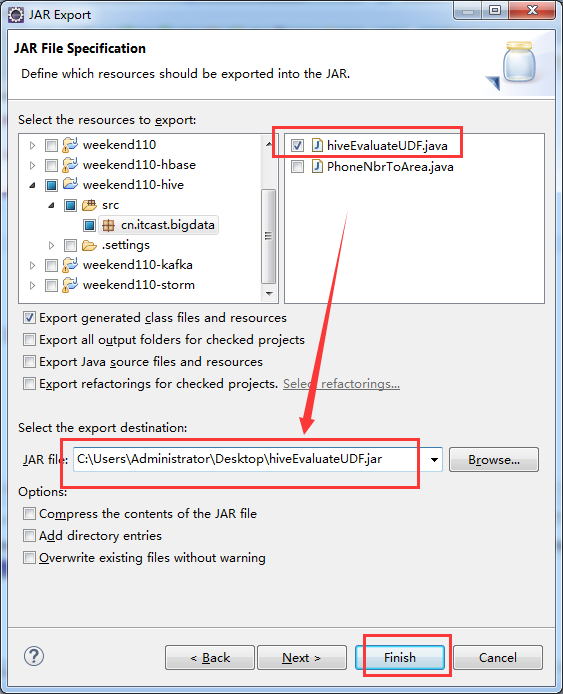


hive> add jar hiveEvaluateUDF.jar;

得到 cn.itcast.bigdata.hiveEvaluateUDF
hive> create temporary function to_lower as 'cn.itcast.bigdata.hiveEvaluateUDF';
剩下的,自行去尝试。
如何用好自己写好的自定义UDF函数
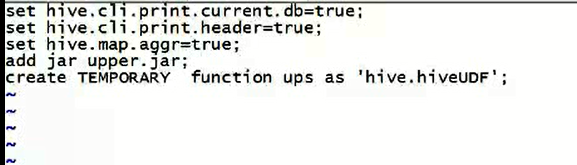
方法一:
比如,我这里,有个转大写的自定义UDF函数,自己写个vi hiveupperrc文件。每次执行这个文件,这个自定义的转大写函数能用了。
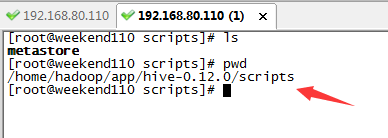
方法二:
在$HIVE_HOME/scripts目录下,写个如 hiveupperrc.sh脚本。
Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)的更多相关文章
- Hadoop HBase概念学习系列之HBase里的列式数据库(十七)
列式数据库,从数据存储方式上有别于行式数据库,所有数据按列存取. 行式数据库在做一些列分析时,必须将所有列的信息全部读取出来 而列式数据库由于其是按列存取,因此只需在特定列做I/O即可完成查询与分析, ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里的HiveQL——查询语言(十五)
Hive的操作与传统关系型数据库SQL操作十分类似. Hive主要支持以下几类操作: DDL 1.DDL:数据定义语句,包括CREATE.ALTER.SHOW.DESCRIBE.DROP等. 详细点, ...
- Hadoop Hive概念学习系列之hive里如何显示当前数据库及传参(十九)
这个小知识点,看似简单,用处极大. $ hive --hiveconf hive.cli.print.current.db=true $ hive --hiveconf hive.cli.print. ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
- Hadoop Hive概念学习系列之hive里的分区(九)
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”. 分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助. 分 ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
随机推荐
- 腾讯云,体验域名注册解析与SSL证书
体验域名注册解析与SSL证书 购买域名 任务时间:30min ~ 60min 在腾讯云上购买域名 首先需要在腾讯云上购买域名, 点击以下链接可以观看购买操作的指引 如何在腾讯云上购买域名 域名解析 域 ...
- Java基础学习总结(77)——Java枚举再总结
在Java SE5之前,我们要使用枚举类型时,通常会使用static final 定义一组int常量来标识,代码如下 public static final int MAN = 0; public s ...
- 【BZOJ4514】数字配对(费用流)
题意: 有 n 种数字,第 i 种数字是 ai.有 bi 个,权值是 ci. 若两个数字 ai.aj 满足,ai 是 aj 的倍数,且 ai/aj 是一个质数, 那么这两个数字可以配对,并获得 ci× ...
- SiteMesh2-示例工程
了解SiteMesh的最佳方法是使用它.假设SiteMesh设置在您的Web应用程序中,本教程将展示如何掌握SiteMesh最强大的方面,如下所示装饰页面: 效果发生在第2步,其中Menu.jsp页面 ...
- shell中的四种模式匹配
POSIX为shell为进行模式匹配提供了四种参数替换结构(老版本的shell可能不支持),每种结构有两个参数:变量名(或变量号)及模式. 第一种模式: ${variable%pattern}, ...
- uva 11212 - Editing a Book(迭代加深搜索 IDA*) 迭代加深搜索
迭代加深搜索 自己看的时候第一遍更本就看不懂..是非常水,但智商捉急也是没有办法的事情. 好在有几个同学已经是做过了这道题而且对迭代加深搜索的思路有了一定的了解,所以在某些不理解的地方询问了一下他们的 ...
- OC-内存管理的一些要点
创建一个BOOK对象,对其属性进行声明 定义. @property 属性声明 定义了对属性的赋值 -(void) dealloc 方法在对象销毁的时候进行调用. #import <Foundat ...
- 连载:面向对象葵花宝典:思想、技巧与实践(34) - DIP原则
DIP,dependency inversion principle,中文翻译为"依赖倒置原则". DIP是大名鼎鼎的Martin大师提出来的.他在1996 5月的C++ Repo ...
- 关于require.js的用法总结
require.js就是将多个js文件集中化处理,在要运行的HTML文件里,写入<script data-main='js/main.js' src='js/require.js'>< ...
- iOS常用的宏定义总结
字符串是否为空 1 #define kStringIsEmpty(str) ([str isKindOfClass:[NSNull class]] || str == nil || [str le ...