数据结构与算法之美学习笔记:B+树(第48讲)
一、解决问题的前提是定义清楚问题
通过对一些模糊需求进行假设,来限定要解决问题的范围
根据某个值查找数据,比如 select * from use where id=1234;
根据区间值来查询某些数据比如 select * from use where id > 1234 and id < 2345
性能方面的需求,我们主要考察时间和空间两方面,也就是执行效率和存储空间
执行效率:我么你希望通过索引,查询数据的效率尽可能的高;
存储空间方面:我们希望索引不需要消耗太多的内存空间
二、尝试用学过的数据结构解决这个问题
支持快速查询、插入等操作的动态数据结构,我们已经学过散列表、平衡二叉树、跳表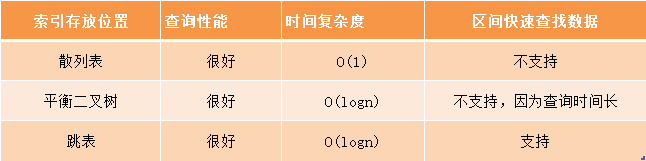

这样看来,跳表是可以解决这个问题,实际上,数据库索引所用到的数据结构跟跳表非常相似,叫做B+树
它是通过跳表演化雇来的,而非跳表
三、改造二叉查找树来解决这个问题
1、实现代码
/**
* 这是 B+ 树非叶子节点的定义。
*
* 假设 keywords=[3, 5, 8, 10]
* 4 个键值将数据分为 5 个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5 个区间分别对应:children[0]...children[4]
*
* m 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = (m-1)*4[keywordss 大小]+m*8[children 大小]
*/
public class BPlusTreeNode {
public static int m = 5; // 5 叉树
public int[] keywords = new int[m-1]; // 键值,用来划分数据区间
public BPlusTreeNode[] children = new BPlusTreeNode[m];// 保存子节点指针
} /**
* 这是 B+ 树中叶子节点的定义。
*
* B+ 树中的叶子节点跟内部结点是不一样的,
* 叶子节点存储的是值,而非区间。
* 这个定义里,每个叶子节点存储 3 个数据行的键值及地址信息。
*
* k 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = k*4[keyw.. 大小]+k*8[dataAd.. 大小]+8[prev 大小]+8[next 大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 数据的键值
public long[] dataAddress = new long[k]; // 数据地址 public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点
public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}
2、实现步骤

3、实现思路
分裂合并
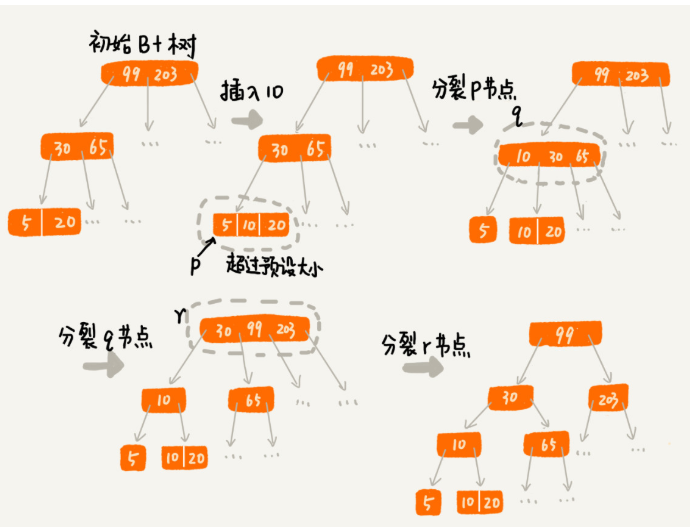
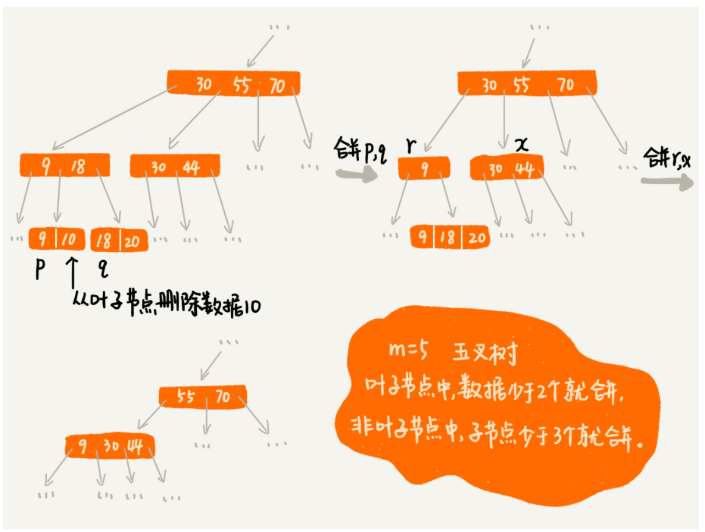
4、删除操作的例子
四、总结引申
1、每个节点中子节点的个数不能超过m,也不能小于m/2
2、根节点的子节点个数不可超过m/2,这是一个例外
3、M叉树只存储索引,并不真正存储数据,这个有点类似跳表
4、通过链表将叶子阶段串联在一次,这样可以方便区间查询
5、一般情况下,根节点会被存储在内存中,其他节点存储在磁盘中
数据结构与算法之美学习笔记:B+树(第48讲)的更多相关文章
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- 【数据结构与算法Python版学习笔记】树——二叉树的应用:解析树
解析树(语法树) 将树用于表示语言中句子, 可以分析句子的各种语法成分, 对句子的各种成分进行处理 语法分析树 程序设计语言的编译 词法.语法检查 从语法树生成目标代码 自然语言处理 机器翻译 语义理 ...
- 【数据结构与算法Python版学习笔记】树——相关术语、定义、实现方法
概念 一种基本的"非线性"数据结构--树 根 枝 叶 广泛应用于计算机科学的多个领域 操作系统 图形学 数据库 计算机网络 特征 第一个属性是层次性,即树是按层级构建的,越笼统就越 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
- 【数据结构与算法Python版学习笔记】树——二叉查找树 Binary Search Tree
二叉搜索树,它是映射的另一种实现 映射抽象数据类型前面两种实现,它们分别是列表二分搜索和散列表. 操作 Map()新建一个空的映射. put(key, val)往映射中加入一个新的键-值对.如果键已经 ...
- 【数据结构与算法Python版学习笔记】树——树的遍历 Tree Traversals
遍历方式 前序遍历 在前序遍历中,先访问根节点,然后递归地前序遍历左子树,最后递归地前序遍历右子树. 中序遍历 在中序遍历中,先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树. 后序遍 ...
- 数据结构与算法C++描述学习笔记1、辗转相除——欧几里得算法
前面学了一个星期的C++,以前阅读C++代码有些困难,现在好一些了.做了一些NOI的题目,这也是一个长期的目标中的一环.做到动态规划的相关题目时发现很多问题思考不通透,所以开始系统学习.学习的第一本是 ...
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
随机推荐
- 学习RenderScript,以此来修改LiveWallpaper
先留个坑,花5天的时间来填满.
- 使用GDB调试Android Native 层代码
--------------步骤:0. adb root0. adb shell0. ps | grep browser1. gdbserver :5039 --attach pid2. adb fo ...
- 快速排序实现及其pivot的选取
coursera上斯坦福的算法专项在讲到快速排序时,称其为最优雅的算法之一.快速排序确实是一种比较有效的排序算法,很多类库中也都采用了这种排序算法,其最坏时间复杂度为$O(n^2)$,平均时间复杂度为 ...
- Jenkins实现简单的CI功能
步骤一:安装JDK.Tomcat,小儿科的东西不在此详细描述 步骤二:下载安装Jenkins下载链接:https://jenkins.io/download/ 步骤三:将下载的jenkins.war部 ...
- 「Python」为什么Python里面,整除的结果会是小数?
2018-06-08 参考资料:Python学习笔记(4)负数除法和取模运算 先来看三个式子(!这是在Python3.0下的运算结果): 输出结果: ‘//’明明是整除,为什么结果不是整数,而会出现小 ...
- iOS中Safari浏览器select下拉列表文字太长被截断的处理方法
网页中的select下拉列表,文字太长的话在iOS的Safari浏览器里会被自动截断,显示成下面这种: 安卓版的浏览器则没有这个问题. 如何让下拉列表中的文字在iOS的Safari浏览器里显示完整呢? ...
- git tag 打标签
注意:在哪个分支上打tag一定要先提交该分支到远程gitlab仓库 标签(tag)操作 1. 查看所有标签 git tag 默认标签是打在最新提交的commit上的 2.本地打新标签 git tag ...
- jupyter notebook修改默认路径和浏览器
1.jupyter notebook --generate-config 2.修改jupyter_notebook_config.py配置文件 3.修改默认路径: c.NotebookApp.note ...
- C#使用异步操作时的注意要点(翻译)
异步操作时应注意的要点 使用异步方法返回值应避免使用void 对于预计算或者简单计算的函数建议使用Task.FromResult代替Task.Run 避免使用Task.Run()方法执行长时间堵塞线程 ...
- Airtest自动化测试工具
一开始知道Airtest大概是在年初的时候,当时,看了一下官方的文档,大概是类似Sikuli的一个工具,主要用来做游戏自动化的,通过截图的方式用来解决游戏自动化测试的难题.最近,移动端测试的同事尝试用 ...