堆溢出学习笔记(linux)
本文主要是linux下堆的数据结构及堆调试、堆溢出利用的一些基础知识
首先,linux下堆的数据结构如下
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
struct malloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
- prev_size, 如果该 chunk 的物理相邻的前一地址chunk(两个指针的地址差值为前一chunk大小)是空闲的话,那该字段记录的是前一个 chunk 的大小(包括 chunk 头)。否则,该字段可以用来存储物理相邻的前一个chunk 的数据。这里的前一 chunk 指的是较低地址的 chunk 。
- size ,该 chunk 的大小,大小必须是 2 * SIZE_SZ 的整数倍。如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。 该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1表示不属于,0表示属于。
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。
- PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的P位都会被设置为1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲chunk之间的合并。
- fd,bk。 chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时,会被添加到对应的空闲管理链表中,其字段的含义如下
- fd 指向下一个(非物理相邻)空闲的 chunk
- bk 指向上一个(非物理相邻)空闲的 chunk
- 通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
- fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适chunk 时挨个遍历。
以上内容摘自CTF-WIKI https://ctf-wiki.github.io/ctf-wiki/pwn/heap/heap_structure/#top-chunk
给出一个简单堆溢出的例子
#include <stdio.h> int main(void)
{
char *chunk;
chunk=malloc();
puts("Get input:");
gets(chunk);
return ;
}
gcc -no-pie -p example1 example1.c编译程序
objdump -d example1查看main函数地址,然后gdb在main函数起始位置下断点。
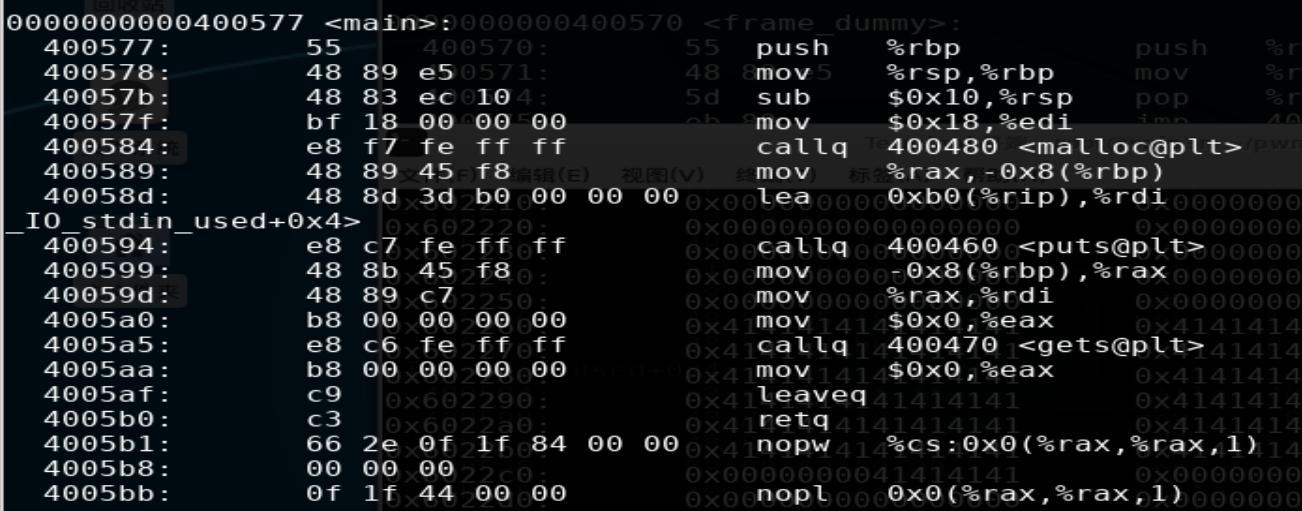
当执行到0x400589时查看rax内容即为malloc分配堆的起始地址。
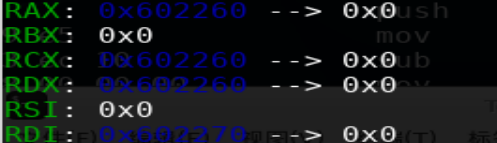
执行完0x405a5时 x/10xg 0x602250用‘A'*100覆盖堆查看堆溢出情况(Gdb指令查看手册https://darkdust.net/files/GDB%20Cheat%20Sheet.pdf)

这里查看0x602250的原因是INTERNAL_SIZE_T默认和size_t一致,32位系统下size_t 4字节,64位系统下size_t 8字节。malloc返回的堆地址指针实际是 struct malloc_chunk* fd的fd,所以64位系统下查看堆首需要用返回的堆地址减去16字节的堆头。
我们在重新看一下堆覆盖之前的堆内容

size部分的最后三个字节分别表示特定含义(见上数据结构),用户真正可用的堆地址是0X602260-0X60226F,共16字节。申请24字节分配16字节的原因是32位系统8字节对齐,64位16位对齐;而分配的16字节能够存储24字节的原因是借用了下一块的pre_size域,16+8=24
关于申请内存到实际分配内存的转换
/* pad request bytes into a usable size -- internal version */
//MALLOC_ALIGN_MASK = 2 * SIZE_SZ -1
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) \
? MINSIZE \
: ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
当申请内存+堆头大于MINSIZE时,返回((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)这个结果。这个结果的意思是(用户申请内存大小+堆头)&~MALLOC_ALIGN_MASK。以64位系统申请24字节堆块为例,24+堆头=40 (101000);MALLOC_ALIGN_MASK 01111取反10000,按位与的结果就是100000了,即32。
这样做可以满足用户申请内存需求的原因是,~(2*SIZE_SZ-1)其实就是操作系统的双字长,比如64位系统就是10000,这样按位与就能保证分配的内存最低4位为0,也就保证了分配堆块的字节对齐。
0X602270是top chunk的内容,top chunk是在第一次执行malloc时heap 会被分为两块,一块给用户,剩下的那块就是 top chunk。top chunk就是当前堆的物理地址最高chunk,这个chunk不属于任何bin。
堆溢出学习笔记(linux)的更多相关文章
- Linux学习笔记-Linux系统简介
Linux学习笔记-Linux系统简介 UNIX与Linux发展史 UNIX是父亲,Linux是儿子. UNIX发行版本 操作系统 公司 硬件平台 AIX IBM PowerPC HP-UX HP P ...
- Linux内核分析第七周学习笔记——Linux内核如何装载和启动一个可执行程序
Linux内核分析第七周学习笔记--Linux内核如何装载和启动一个可执行程序 zl + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study. ...
- 大数据学习笔记——Linux基本知识及指令(理论部分)
Linux学习笔记整理 上一篇博客中,我们详细地整理了如何从0部署一套Linux操作系统,那么这一篇就承接上篇文章,我们仔细地把Linux的一些基础知识以及常用指令(包括一小部分高级命令)做一个梳理, ...
- MongoDB学习笔记—Linux下搭建MongoDB环境
1.MongoDB简单说明 a MongoDB是由C++语言编写的一个基于分布式文件存储的开源数据库系统,它的目的在于为WEB应用提供可扩展的高性能数据存储解决方案. b MongoDB是一个介于关系 ...
- shell入门之函数应用 分类: 学习笔记 linux ubuntu 2015-07-10 21:48 77人阅读 评论(0) 收藏
最近在学习shell编程,文中若有错误的地方还望各位批评指正. 先来看一个简单的求和函数 #!/bin/bash #a test about function f_sum 7 8 function f ...
- Linux菜鸟学习笔记--Linux系统结构
什么是Linux? Linux是一种自由和开放源码的类Unix操作系统,存在着许多不同的Linux版本,但它们都使用了Linux内核.严格来讲,Linux这个词本身只表示Linux内核,但实际上人 ...
- 《马哥出品高薪linux运维教程》wingkeung学习笔记-linux基础入门课程
计算机原理概念: 1.CPU和内存中的存储单元通信线路称为总线(BUS),总线是被指令和数据复用的,所以也称为前端总线. 2.计算机中计算频率的时间标准即晶体振荡器原理,精确计算时间长度,根据相同的时 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- [马哥学习笔记]Linux系统裁剪之制作带网络功能的可启动linux
知识基础: 系统启动流程:POST-->BIOS(boot sequence)-->GRUB(bootloder(stage1:MBR;stage2:grub目录中))-->kern ...
随机推荐
- PWC6345: There is an error in invoking javac. A full JDK (not just JRE) is required
今天在使用jetty运行一个项目的时候报这个错误,仔细看了下,应该是eclipse配置的jdk或者jre出错. 看了下环境变量,发现有些配置没有配置完全. 我个人的解决方法: 在path中,添加%JA ...
- python2.7添加注释后,代码无法保存
最近需要学习一下Python,然后开始学习中,使用的编辑环境是Python自带的IDLE Python的注释使用的是 # 然后我再代码添加注释 #Python的注释是这个字符 发现始终无法保存代码 ...
- 为什么Fourier分析?
本文旨在给出Fourier分析的几个动机. 目录 波动方程 热导方程 Lapalce变换 求和公式 表示论 特征理论 参考资料 波动方程 考虑一维的波动方程最简单的边值问题$$u(x,t), x\in ...
- mysql c connector 多条sql语句执行示例
// 假设参数 sql已经包含多条sql语句.如 sql = "insert into table1(...) values(...); update table2 set a=1;& ...
- 软件工程(GZSD2015) 第三次作业
时间: 2015/4/17-2015/4/23 基本要求: 在之前编写的四则运算程序基础之上做如下改进: 请参照教材Page57:4.2-4.3节中内容,修改原程序,使之符合 "代码风格和设 ...
- 使用axios post 提交数据,后台获取不到
https://www.cnblogs.com/yiyi17/p/9409249.html(copy https://www.cnblogs.com/loveyaxin/p/8385694.html( ...
- sql 书写 规范 优化
规范 做注解 便于修改和优化 规范 <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE map ...
- MySQL 中触发器的应用
在一个教育系统里面,有 科目表 ,章节表(每一科目对应若干大章节),小节表(每一大章节下面有若干小节),习题表(每一小节对应若干习题), 在后台管理系统中 有这样几个功能要实现,在 科目列表页面中 ...
- [模板] 杜教筛 && bzoj3944-Sum
杜教筛 浅谈一类积性函数的前缀和 - skywalkert's space - CSDN博客 杜教筛可以在\(O(n^{\frac 23})\)的时间复杂度内利用卷积求出一些积性函数的前缀和. 算法 ...
- TensorFlow深度学习,一篇文章就够了
http://blog.jobbole.com/105602/ 作者: 陈迪豪,就职小米科技,深度学习工程师,TensorFlow代码提交者. TensorFlow深度学习框架 Google不仅是大数 ...