Python全栈-magedu-2018-笔记10
第三章 - Python 内置数据结构
集set
- 约定
- set 翻译为集合
- collection 翻译为集合类型,是一个大概念
- set
- 可变的、无序的、不重复的元素的集合
set定义 初始化
- set() -> new empty set object
- set(iterable) -> new set object
s1 = set()
s2 = set(range(5))
s3 = set(list(range(10)))
s4 = {} # dict
s5 = {9,10,11} # set
s6 = {(1,2),3,'a'}
s7 = {[1],(1,),1} # unhashable type: 'list'
set的元素
- set的元素要求必须可以hash(因为set就是哈希表啊)
- 目前学过的不可hash的类型有list、set
- 元素不可以索引,因为无序
- set可以迭代
set增加
- add(elem)
- 增加一个元素到set中
- 如果元素存在,什么都不做
- update(*others)
- 合并其他元素到set集合中来
- 参数others必须是可迭代对象
- 就地修改
set删除
- remove(elem)
- 从set中移除一个元素
- 元素不存在,抛出KeyError异常。为什么是KeyError?
- discard(elem)
- 从set中移除一个元素
- 元素不存在,什么都不做
- pop() -> item
- 移除并返回任意的元素。为什么是任意元素?
- 空集返回KeyError异常
- clear()
- 移除所有元素
set修改、查询
- 修改
- 要么删除,要么加入新的元素
- 为什么没有修改?
- 查询
- 非线性结构,无法索引
- 遍历
- 可以迭代所有元素
- 成员运算符
- in 和 not in 判断元素是否在set中
- 效率呢?与索引访问列表的效率是差不多的,O(1)
set成员运算符的比较
- list和set的比较
- lst1 = list(range(100))
- lst2 = list(range(1000000))
- -1 in lst1、-1 in lst2 看看效率
- set1 = set(range(100))
- set2 = set(range(1000000))
- -1 in set1、-1 in set2 看看效率
set成员运算符的比较
%%timeit lst1=list(range(100))
a = -1 in lst1
%%timeit lst1=list(range(1000000))
a = -1 in lst1
%%timeit set1=set(range(100))
a = -1 in set1
%%timeit set1=set(range(1000000))
a = -1 in set1
set不管元素怎么增加遍历的效率都是一样的。
set和线性结构
- 线性结构的查询时间复杂度是O(n),即随着数据规模的增大而增加耗时
set、dict等结构,内部使用hash值作为key,时间复杂度可以做到O(1),查询时间和数据规模无关
- 可hash
- 数值型int、float、complex
- 布尔型True、False
- 字符串string、bytes
- tuple
- None
- 以上都是不可变类型,成为可哈希类型,hashable
set的元素必须是可hash的
集合
- 基本概念
- 全集
- 所有元素的集合。例如实数集,所有实数组成的集合就是全集
- 子集subset和超集superset
- 一个集合A所有元素都在另一个集合B内,A是B的子集,B是A的超集
- 真子集和真超集
- A是B的子集,且A不等于B,A就是B的真子集,B是A的真超集
- 并集:多个集合合并的结果
- 交集:多个集合的公共部分
- 差集:集合中除去和其他集合公共部分
- 全集
集合运算
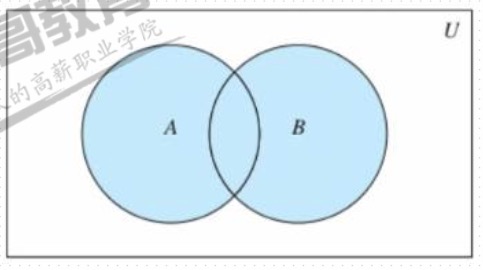
- 并集
- 将两个集合A和B的所有的元素合并到一起,组成的集合称作集合A与集合B的并集
- union(*others)
- 返回和多个集合合并后的新的集合
- | 运算符重载
- 等同union
- update(*others)
- 和多个集合合并,就地修改
- |=
- 等同update
集合运算
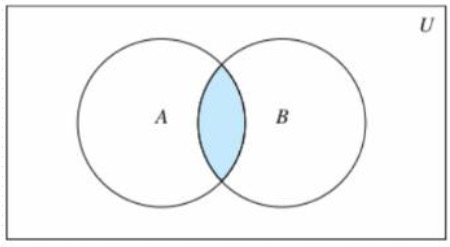
- 交集
- 集合A和B,由所有属于A且属于B的元素组成的集合
- intersection(*others)
- 返回和多个集合的交集
- &
- 等同intersection
- intersection_update(*others)
- 获取和多个集合的交集,并就地修改
- &=
- 等同intersection_update
集合运算
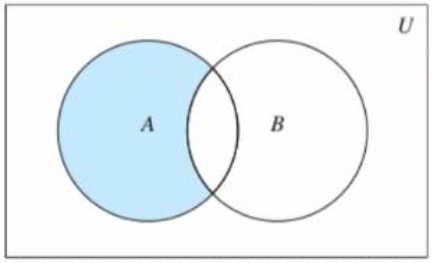
- 差集
- 集合A和B,由所有属于A且不属于B的元素组成的集合
- difference(*others)
- 返回和多个集合的差集
- -
- 等同difference
- difference_update(*others)
- 获取和多个集合的差集并就地修改
- -=
- 等同difference_update
集合运算
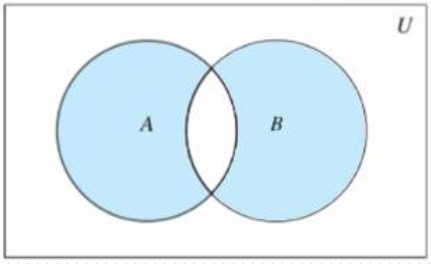
- 对称差集
- 集合A和B,由所有不属于A和B的交集元素组成的集合,记作(A-B)∪(B-A)
- symmetric_differece(other)
- 返回和另一个集合的差集
- ^
- 等同symmetric_differece
- symmetric_differece_update(other)
- 获取和另一个集合的差集并就地修改
- ^=
- 等同symmetric_differece_update
集合运算
- issubset(other)、<=
- 判断当前集合是否是另一个集合的子集
- set1 < set2
- 判断set1是否是set2的真子集
- issuperset(other)、>=
- 判断当前集合是否是other的超集
- set1 > set2
- 判断set1是否是set的真超集
- isdisjoint(other)
- 当前集合和另一个集合没有交集
- 没有交集,返回True
集合应用
- 共同好友
- 你的好友A、B、C,他的好友C、B、D,求共同好友
如果是推荐好友,用差集求,不用查库,在内存中集合运算是非常快的,而且往往用到Redis的
- 你的好友A、B、C,他的好友C、B、D,求共同好友
- 微信群提醒
- XXX与群里其他人都不是微信朋友关系
- 权限判断
- 有一个API,要求权限同时具备A、B、C才能访问,用户权限是B、C、D,判断用户是否能够访问该API
- 有一个API,要求权限具备A、B、C任意一项就可访问,用户权限是B、C、D,判断用户是否能够访问该API
- 一个总任务列表,存储所有任务。一个完成的任务列表。找出为未完成的任务
解决的方法都不是唯一的,下面仅供参考。
集合应用
- 共同好友
- 你的好友A、B、C,他的好友C、B、D,求共同好友
- 交集问题:{'A', 'B', 'C'}.intersection({'B', 'C', 'D'})
- 微信群提醒
- XXX与群里其他人都不是微信朋友关系
- 并集:userid in (A | B | C | ...) == False,A、B、C等是微信好友的并集,用户ID不在这个并集中,说明他和任何人都不是朋友
集合应用
- 权限判断
- 有一个API,要求权限同时具备A、B、C才能访问,用户权限是B、C、D,判断用户是否能够访问该API
- API集合A,权限集合P
- A - P = {} ,A-P为空集,说明P包含A
- A.issubset(P) 也行,A是P的子集也行
- A & P = A 也行
- 有一个API,要求权限具备A、B、C任意一项就可访问,用户权限是B、C、D,判断用户是否能够访问该API
- API集合A,权限集合P
- A & P != {} 就可以
- A.isdisjoint(P) == False 表示有交集
- 有一个API,要求权限同时具备A、B、C才能访问,用户权限是B、C、D,判断用户是否能够访问该API
集合应用
- 一个总任务列表,存储所有任务。一个已完成的任务列表。找出为未完成的任务
- 业务中,任务ID一般不可以重复
- 所有任务ID放到一个set中,假设为ALL
- 所有已完成的任务ID放到一个set中,假设为COMPLETED,它是ALL的子集
- ALL - COMPLETED = UNCOMPLETED
集合练习
- 随机产生2组各10个数字的列表,如下要求:
- 每个数字取值范围[10,20]
- 统计20个数字中,一共有多少个不同的数字?
- 2组中,不重复的数字有几个?分别是什么?
- 2组中,重复的数字有几个?分别是什么?
集合练习
- 随机产生2组各10个数字的列表,如下要求:
- 每个数字取值范围[10,20]
- 统计20个数字中,一共有多少个不同的数字?
- 2组比较,不重复的数字有几个?分别是什么?
- 2组比较,重复的数字有几个?分别是什么?
a = [1, 9, 7, 5, 6, 7, 8, 8, 2, 6]
b = [1, 9, 0, 5, 6, 4, 8, 3, 2, 3]
s1 = set(a)
s2 = set(b)
print(s1)
print(s2)
print(s1.union(s2))
print(s1.symmetric_difference(s2))
print(s1.intersection(s2))
最后
本文的另外链接是:https://herodanny.github.io/python-magedu-2018-notes10.html
Python全栈-magedu-2018-笔记10的更多相关文章
- 自学Python全栈开发第一次笔记
我已经跟着视频自学好几天Python全栈开发了,今天决定听老师的,开始写blog,听说大神都回来写blog来记录自己的成长. 我特别认真的跟着这个视频来学习,(他们开课前的保证书,我也写 ...
- Python全栈之jQuery笔记
jQuery runnoob网址: http://www.runoob.com/jquery/jquery-tutorial.html jQuery API手册: http://www.runoob. ...
- python全栈开发之OS模块的总结
OS模块 1. os.name() 获取当前的系统 2.os.getcwd #获取当前的工作目录 import os cwd=os.getcwd() # dir=os.listdi ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
- 学习笔记之Python全栈开发/人工智能公开课_腾讯课堂
Python全栈开发/人工智能公开课_腾讯课堂 https://ke.qq.com/course/190378 https://github.com/haoran119/ke.qq.com.pytho ...
- 老男孩最新Python全栈开发视频教程(92天全)重点内容梳理笔记 看完就是全栈开发工程师
为什么要写这个系列博客呢? 说来讽刺,91年生人的我,同龄人大多有一份事业,或者有一个家庭了.而我,念了次985大学,年少轻狂,在大学期间迷信创业,觉得大学里的许多课程如同吃翔一样学了几乎一辈子都用不 ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
随机推荐
- Linux下使用crontab对MYSQL进行备份以及定时清
数据备份是一个项目必需的工作,保证数据库出问题时,将损失减小到最低.本文记录下linux服务器中使用脚本对MYSQL数据备份,并且定时清除7天前的备份. crontab定时备份 1.创建备份目录 ...
- vue知多少,你对vue的认识比别人高在哪?
1.beforeCreated/created区别? beforeCreated钩子能干什么 2.data中使用props 3.get/set依赖收集 get收集依赖(观察者) set 观察者重新求值 ...
- Python学习笔记-EXCEL操作
环境Python3 创建EXCEL,覆盖性创建 #conding=utf-8 import xlwt def BuildExcel(ExcelName,SheetName,TitleList,Data ...
- find xargs 简单组合使用
简单总结下,留作自己以后拾遗...... 一.find xargs 简单组合 ## mv 小结find ./ -type f -name "*.sh"|xargs mv -t /o ...
- Beta 冲刺(3/7)
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:beta冲刺(3/7) 团队部分 后敬甲(组长) 过去两天完成了哪些任务 整理博客 ppt模板 接下来的计划 做好机动. ...
- 【原创】Linux基础之redhat6升级glibc-2.12到2.14
redhat6自带glibc-2.12,升级到glibc-2.14过程 # strings /lib64/libc.so.6 |grep GLIBC_GLIBC_2.2.5GLIBC_2.2.6GLI ...
- 【原创】大数据基础之ElasticSearch(5)重要配置及调优
Index Settings 重要索引配置 Index level settings can be set per-index. Settings may be: 1 static 静态索引配置 Th ...
- Maven全局配置
Maven的全局配置文件是Maven安装目录conf/settings.xml文件,该文件可以配置仓库.代理.profile.镜像.插件等 <settings> <localRepo ...
- greenplum加密
--如下为greenplum5.0数据库加解密--加密函数select encrypt('123456','aa','aes');--加解密函数select convert_from(decrypt( ...
- C#+EntityFramework编程方式详细之Model First
Model First Model First模式即“模型优先”,这里的模型指的是“ADO.NET Entity Framework Data Model”,此时你的应用并没有设计相关数据库,在VS中 ...