【kafka学习之一】 kafka初识
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
一、kafka是什么?
(1)kafka是一个高吞吐的分部式消息系统.
(2)消息列队常见应用场景:系统之间解耦合;峰值压力缓冲;异步通信;
二、kafka特点:
1、生产者消费者模型,FIFO。partition内部是FIFO的,partition之间呢不是FIFO的,当然我们可以把topic设为一个partition,这样就是严格的FIFO
2、高性能:单节点支持上千个客户端,百MB/s吞吐
3、持久性:消息直接持久化在普通磁盘上且性能好,直接写到磁盘里面去,就是直接append到磁盘里面去,这样的好处是直接持久话,数据不会丢,第二个好处是顺序写,然后消费数据也是顺序的读,所以持久化的同时还能保证顺序读写
可靠性保证
-自己不丢数据,将消息持久化到磁盘,默认保存1周;
-消费者不丢数据:“至少一次,严格一次”
4、分布式:数据副本冗余、流量负载均衡、可扩展
分布式,数据副本,也就是同一份数据可以到不同的broker上面去,当一份数据,磁盘坏掉的时候,数据不会丢失,比如3个副本,就是在3个机器磁盘都坏掉的情况下数据才会丢。
5、很灵活:消息长时间持久化+Client维护消费状态
消费方式非常灵活,第一原因是消息持久化时间跨度比较长,一天或者一星期等;
第二消费状态自己维护消费到哪个地方了,可以自定义消费偏移量
三、kafka与其他消息队列对比
• RabbitMQ:分布式,支持多种MQ协议,重量级
• ActiveMQ:与RabbitMQ类似
• ZeroMQ:以库的形式提供,使用复杂,无持久化
ZeroMQ是一个socket的通信库,它是以库的形式提供的,所以说你需要写程序来实现消息系统,它只管内存和通信那一块,持久化也得自己写,还是那句话它是用来实现消息队列的一个库,其实在storm里面呢,storm0.9之前,那些spout和bolt,bolt和bolt之间那些底层的通信就是由ZeroMQ来通信的,它并不是一个消息队列,就是一个通信库,在0.9之后呢,因为license的原因,ZeroMQ就由Netty取代了,Netty本身就是一个网络通信库嘛,所以说更合适是在通信库这一层,不应该是MessageQueue这一层
• redis:单机、纯内存性好,持久化较差
Redis,本身是一个内存的KV系统,但是它也有队列的一些数据结构,能够实现一些消息队列的功能,当然它在单机纯内存的情况下,性能会比较好,持久化做的稍差,当持久化的时候性能下降的会比较厉害
• kafka:分布式,较长时间持久化,高性能,轻量灵活
Kafka的亮点,天生是分布式的,不需要你在上层做分布式的工作,另外有较长时间持久化,前面的几个MQ基本消费完就干掉了,另外在长时间持久化下性能还比较高,顺序读和顺序写,另外还通过sendFile这样0拷贝的技术直接从文件拷贝到网络,减少内存的拷贝,还有批量读批量写来提高网络读取文件的性能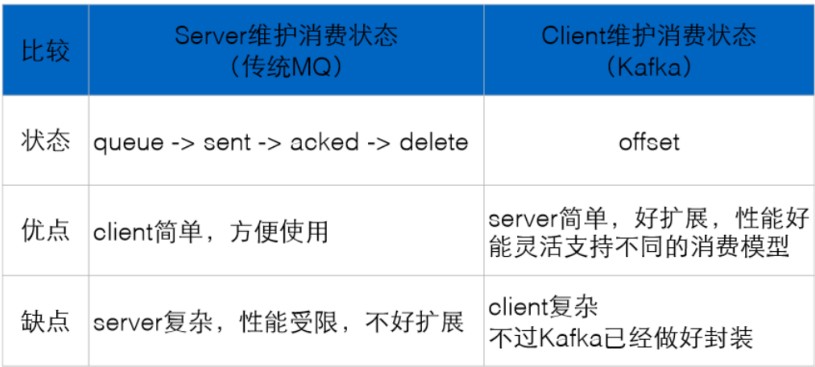
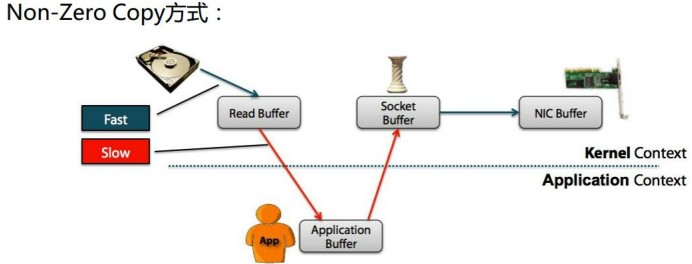
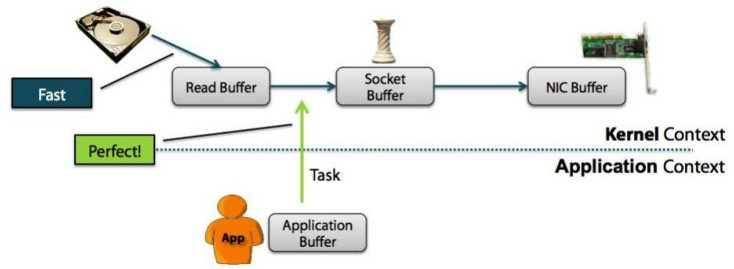
四、零拷贝
零拷贝是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
普通拷贝:
零拷贝:
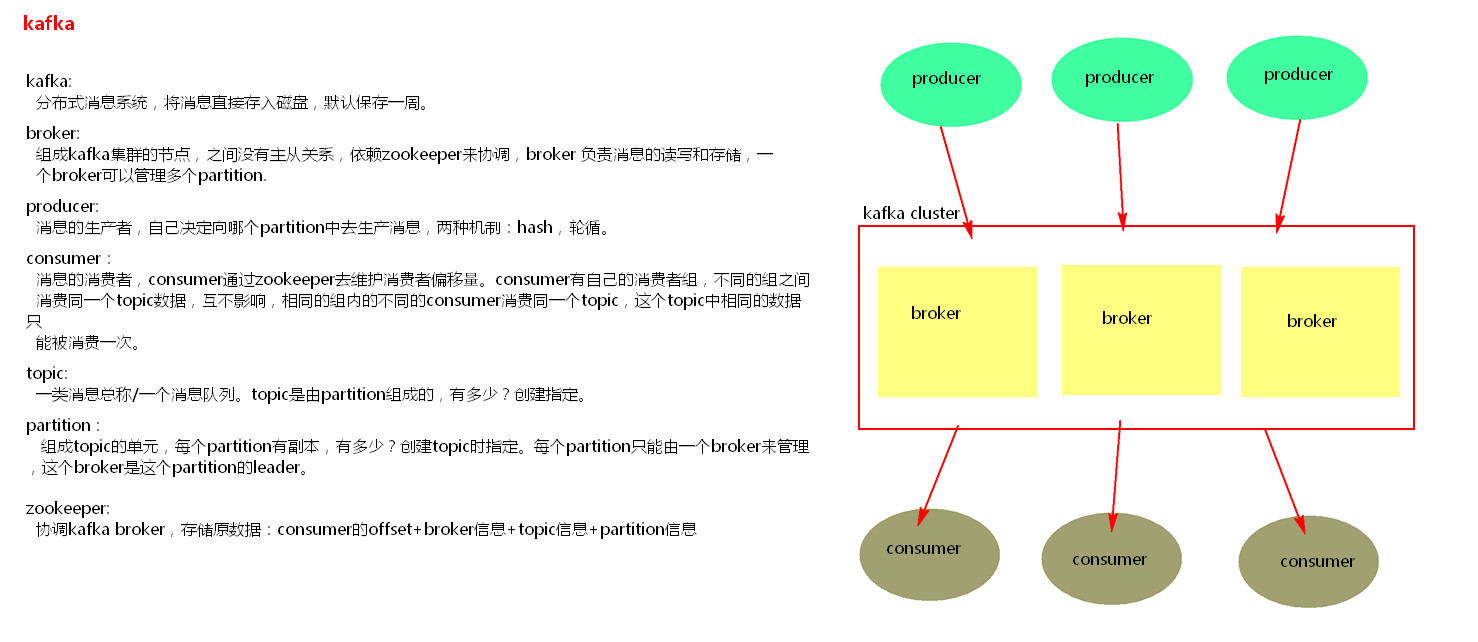
五、kafka的架构
六、kafka的消息存储和生产消费模型
(1)kafka里面的消息由topic来组织的,可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition内部消息强有序,相当于有序的队列,其中每个消息都有个序号offset,比如0到12,从前面读往后面写。
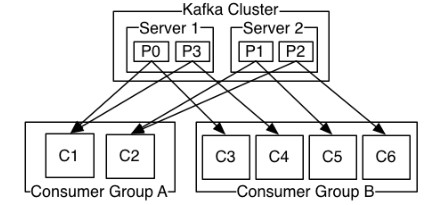
(2)一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。
(3)这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,消息不经过内存缓冲,直接写入文件,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念。
(4)producer自己决定往哪个partition里面去写,这里有一些的策略,譬如如果hash,不用多个partition之间去join数据了。
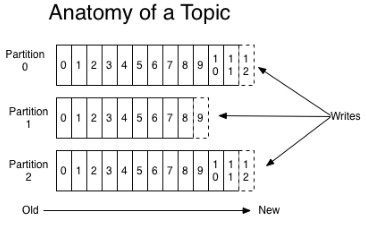
(5)consumer自己维护消费到哪个offset
(6)每个consumer都有对应的group,
(7)group内是queue消费模型(各个consumer消费不同的partition,因此一个消息在group内只消费一次)
(8)group间是publish-subscribe消费模型
(9)各个group各自独立消费,互不影响,因此一个消息在被每个group消费一次。
【kafka学习之一】 kafka初识的更多相关文章
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- Kafka学习之四 Kafka常用命令
Kafka常用命令 以下是kafka常用命令行总结: 1.查看topic的详细信息 ./kafka-topics.sh -zookeeper 127.0.0.1:2181 -describe -top ...
- kafka 学习资料
kafka 学习资料 kafka 学习资料 网址 kafka 中文教程 http://orchome.com/kafka/index
- kafka学习(一)初识kafka
文章更新时间:2020/06/08 一.简介 定义:kafka是一个分布式,基于zookeeper协调的发布/订阅模式的消息系统,本质是一个MQ(消息队列Message Queue),主要用于大数据实 ...
- Kafka学习(一)kafka指南(about云翻译)
kafka 权威指南中文版 问题导读 1. 为什么数据管道是数据驱动企业的一个关键组成部分? 2. 发布/订阅消息的概念及其重要性是什么? 第一章 初识 kafka 企业是由数据驱动的.我们获取信息, ...
- Kafka学习(二)
作者:程序员cxuan链接:https://www.zhihu.com/question/53331259/answer/1262483551来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- Kafka学习-简介
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.S ...
- Kafka学习-入门
在上一篇kafka简介的基础之上,本篇主要介绍如何快速的运行kafka. 在进行如下配置前,首先要启动Zookeeper. 配置单机kafka 1.进入kafka解压目录 2.启动kafka bin\ ...
- kafka学习笔记1:测试环境搭建
最近因为架构中引入了kafka,一些之前在代码中通过RPC调用强耦合但是适合异步处理的内容可以用kafka重构一下. 考虑从头学一下kafka了解其特性和使用场景. 环境选择 首先是测试环境的搭建,平 ...
随机推荐
- python提取xml属性导入Mysql
xml文档来自ganglia-gmond端telnet localhost 8649产生出来的文档,由于ganglia每隔一段时间就更新数据,为了永久保存数据到MySQL中,就用python写了最开始 ...
- [LeetCode] K-th Symbol in Grammar 语法中的第K个符号
On the first row, we write a 0. Now in every subsequent row, we look at the previous row and replace ...
- JavaScript学习day3 (基本语法下)
if/else for while 函数的使用 JavaScript语句 if/else 语句 JavaScript 中的if/else 判断选择,语法格式是这样的 switch/case 语句 在做 ...
- html页面转成jsp页面之后样式变化的问题解决方法
转载:https://blog.csdn.net/zeb_perfect/article/details/51172859
- SOAPwebservice 与Restfull webservice之间的区别
简单对象访问协议(Simple Object Access Protocol,SOAP)是一种基于 XML 的协议,可以和现存的许多因特网协议和格式结合使用,包括超文本传输协议(HTTP),简单邮件传 ...
- js表单提交到后台对象接收
$.extend({ StandardPost:function(url,args){ var form = $("<form method='post' target='_blank ...
- Dynamics 365 解决方案导出报错
之前导出解决方案异常,按照CRM社区的方法解决成功,但是没有了解原因,今天看到有朋友解答了原因,也分享给大家 先来看看异常 我那时导出的是default解决方案,这是模拟 导出异常 “业务流程错误”- ...
- 内置对象之request对象
内置对象就是(容器)已经创建好的对象,可以被直接使用.当用户发送一个请求给容器,它就会自动创建一个对象来处理客户端发送来的消息,如request这个对象,可以获取到用户(客户端)发送来的信息.它的常见 ...
- AVL树的Java实现
AVL树:平衡的二叉搜索树,其子树也是AVL树. 以下是我实现AVL树的源码(使用了泛型): import java.util.Comparator; public class AVLTree< ...
- linux上创建svn服务器(centos7.3)
1.安装svn yum -y install subversion 2.创建svn版本仓库 mkdir /var/svn/svnrepos svnadmin create /var/svn/svnre ...