理解 YOLO
YOLO包括 V1, V2, V3
YOLO v1:2016
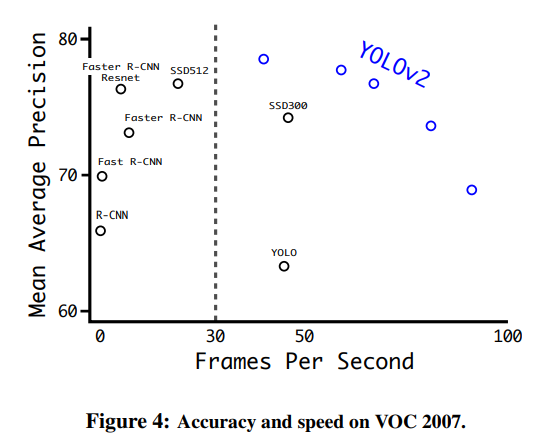
优点:快,45fps,泛化性能好
缺点:检测小物体不太行, 如成群的鸟. 与 Fast R-CNN相比,定位不太准
YOLO的网络结构
YOLO v1 network (没看懂论文上的下图,看下面这个表一目了然了)
24层的卷积层,开始用前面20层来training, 图片是224x224的,然后用448x448 再train 后面4层,最后得到的model 是24层的model.
最后输出7x7个grid cell, 30 表示 2个bounding box (每个5个数字) 加上 20 classes

┌────────────┬────────────────────────┬───────────────────┐
│ Name │ Filters │ Output Dimension │
├────────────┼────────────────────────┼───────────────────┤
│ Conv 1 │ 7 x 7 x 64, stride=2 │ 224 x 224 x 64 │
│ Max Pool 1 │ 2 x 2, stride=2 │ 112 x 112 x 64 │
│ Conv 2 │ 3 x 3 x 192 │ 112 x 112 x 192 │
│ Max Pool 2 │ 2 x 2, stride=2 │ 56 x 56 x 192 │
│ Conv 3 │ 1 x 1 x 128 │ 56 x 56 x 128 │
│ Conv 4 │ 3 x 3 x 256 │ 56 x 56 x 256 │
│ Conv 5 │ 1 x 1 x 256 │ 56 x 56 x 256 │
│ Conv 6 │ 1 x 1 x 512 │ 56 x 56 x 512 │
│ Max Pool 3 │ 2 x 2, stride=2 │ 28 x 28 x 512 │
│ Conv 7 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 8 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 9 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 10 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 11 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 12 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 13 │ 1 x 1 x 256 │ 28 x 28 x 256 │
│ Conv 14 │ 3 x 3 x 512 │ 28 x 28 x 512 │
│ Conv 15 │ 1 x 1 x 512 │ 28 x 28 x 512 │
│ Conv 16 │ 3 x 3 x 1024 │ 28 x 28 x 1024 │
│ Max Pool 4 │ 2 x 2, stride=2 │ 14 x 14 x 1024 │
│ Conv 17 │ 1 x 1 x 512 │ 14 x 14 x 512 │
│ Conv 18 │ 3 x 3 x 1024 │ 14 x 14 x 1024 │
│ Conv 19 │ 1 x 1 x 512 │ 14 x 14 x 512 │
│ Conv 20 │ 3 x 3 x 1024 │ 14 x 14 x 1024 │
│ Conv 21 │ 3 x 3 x 1024 │ 14 x 14 x 1024 │
│ Conv 22 │ 3 x 3 x 1024, stride=2 │ 7 x 7 x 1024 │
│ Conv 23 │ 3 x 3 x 1024 │ 7 x 7 x 1024 │
│ Conv 24 │ 3 x 3 x 1024 │ 7 x 7 x 1024 │
│ FC 1 │ - │ 4096 │
│ FC 2 │ - │ 7 x 7 x 30 (1470) │
└────────────┴────────────────────────┴───────────────────┘ 上图中,至于为什么448x448通过conv成了224x224, 可以参考这里 https://blog.csdn.net/caomin1hao/article/details/80601255,因为一般会做zero-padding, padding = (f-1)/2
预训练的时候用 224x224 的图片,预测时用的448x448的,但是网络结构没有任何变化,只是输出按照比例缩小,比如本来检测网络第20层输出 14 x 14 x 1024 维度,预训练时输出的就是 7x7x1024. 参考的这里 https://blog.csdn.net/qq_30666517/article/details/80572659
v1 两个bounding box 怎么标注?
这里采用2个bounding box,有点不完全算监督算法,而是像进化算法。如果是监督算法,我们需要事先根据样本就能给出一个正确的bounding box作为回归的目标。但YOLO的2个bounding box事先并不知道会在什么位置,只有经过前向计算,网络会输出2个bounding box,这两个bounding box与样本中对象实际的bounding box计算IOU。这时才能确定,IOU值大的那个bounding box,作为负责预测该对象的bounding box。
YOLO v2 (YOLO9000):2016
Yolo v2 的网络结构如下:采用 Darknet-19 backbone, 输出 13x13x (5x25). 引入了 anchor box.
由于v2 去掉了fully connected layer, 这样可以对各种size 的输入进行traning, 这个技术叫 multi-scale traning, input size 的大小为 {320, 352, ..., 608}

Darknet-19 分类模型:

Darknet-19 对象检测模型:

看一下passthrough层。图中第25层route 16,意思是来自16层的output,即26*26*512,这是passthrough层的来源(细粒度特征)。第26层1*1卷积降低通道数,从512降低到64(这一点论文在讨论passthrough的时候没有提到),输出26*26*64。第27层进行拆分(passthrough层)操作,1拆4分成13*13*256。第28层叠加27层和24层的输出,得到13*13*1280。后面再经过3*3卷积和1*1卷积,最后输出13*13*125。
为什么v2 比v1 运行更快,效果更好
faster: 采用了浮点运算更快的darknet-19结构, v1 的运算操作是8.52 billion operations, v2 是only requires 5.58 billion.
v2 的训练过程
YOLO9000依然采用YOLO2的网络结构,不过5个先验框减少到3个先验框,以减少计算量。YOLO2的输出是13*13*5*(4+1+20),现在YOLO9000的输出是13*13*3*(4+1+9418)。假设输入是416*416*3。
YOLO v3 (2018)

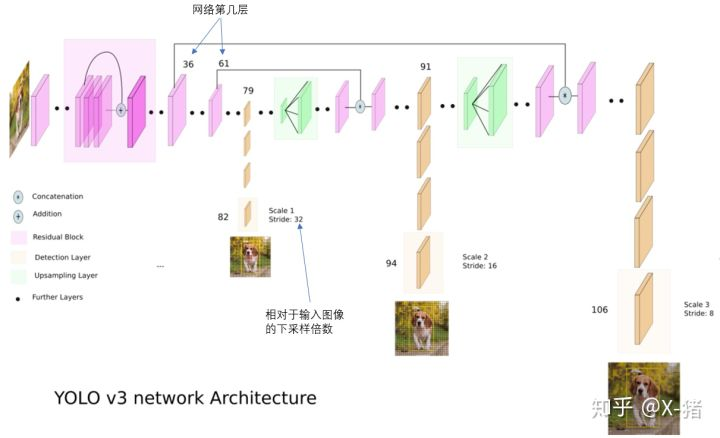
V3 检测网络结构:106层
- YOLO v1深入理解 (v1里面有两个bounding box, 那标注时候到底填哪一个呢?这个文章解释了这个)
- YOLOv1阅读笔记, 这个对yolo v1 的网络结构解释的不错
- 目标检测网络之 YOLOv3
- Understanding YOLO
- <机器爱学习>YOLOv2 / YOLO9000 深入理解
- yolo类检测算法解析——yolo v3
- 目标检测(九)--YOLO v1,v2,v3
- What’s new in YOLO v3?
- https://blog.csdn.net/qq_34784753/article/details/78797213,https://zhuanlan.zhihu.com/p/24916786?utm_source=qq&utm_medium=social, 这个对yolo v1 的cost函数解释的不错
- YOLOv3 深入理解
理解 YOLO的更多相关文章
- Pytorch从0开始实现YOLO V3指南 part1——理解YOLO的工作
本教程翻译自https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/ 视频展示:https://w ...
- 快速理解YOLO目标检测
YOLO(You Only Look Once)论文 近些年,R-CNN等基于深度学习目标检测方法,大大提高了检测精度和检测速度. 例如在Pascal VOC数据集上Faster R-CNN的mAP达 ...
- YOLO理解
一.YOLO v1 1.网络结构 (1)最后一层使用线性激活函数: (2)其他各层使用leaky ReLU的激活函数: 2.Training (1) 将原图划分为SxS的网格.如果一个目标的中心落入某 ...
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
- YOLO V2 代码分析
先介绍YOLO[转]: 第一个颠覆ross的RCNN系列,提出region-free,把检测任务直接转换为回归来做,第一次做到精度可以,且实时性很好. 1. 直接将原图划分为SxS个grid cell ...
- 深度剖析YOLO系列的原理
深度剖析YOLO系列的原理 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/12072225.html 目录 1. ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- YOLO: You Only Look Once论文阅读摘要
论文链接: https://arxiv.org/pdf/1506.02640.pdf 代码下载: https://github.com/gliese581gg/YOLO_tensorflow Abst ...
- Yolo V3整体思路流程详解!
结合开源项目tensorflow-yolov3(https://link.zhihu.com/?target=https%3A//github.com/YunYang1994/tensorflow-y ...
随机推荐
- linux系统ubuntu18.04安装mysql(5.7)
本文是参考mysql官网整理而成,顺便把一些遇到的问题记载下来. ①将MySQLAPT存储库添加到系统的软件存储库列表中 ---->下载APT存储库(下载链接) ---->安装APT存 ...
- WPF中查看PDF文件之MoonPdfLib类库
最近研究了两种PDF文件查看器,MoonPdfLib或者AdobeReader. 今天先说第一种,在网上扒到的很好的WPF中用MoonPdf类库来展示PDF文件. 在Sourceforge上下载到Mo ...
- 把流的形式转化为Base64
public class Test2 { public static String get() throws IOException { InputStream resourceAsStream = ...
- Clion快捷键
快捷键配置 File->Setting->Keymap->Keymaps 选择Visual Studio风格 代码提示的匹配模式 File->Setting->Edito ...
- iOS 使用Instruments的工具小结
使用Instruments的工具 iOSXcodeInstrumentsInstruments是一个官方提供的强大的性能调试工具集. 1.Blank(空模板):创建一个空的模板,可以从Library库 ...
- 初识Haskell 四:函数function之二 常见函数
对Discrete Mathematics Using a Computer的第一章Introduction to Haskell进行总结.环境Windows,关于函数的部分太长了,分开写. 常用的对 ...
- VisualStudio 快捷键
ctrl + o : 打开当前文件所在文件目录 ctrl + 鼠标左键 : 转到方法或者字段定义
- 【翻译】asp.net core2.0中的token认证
原文地址:https://developer.okta.com/blog/2018/03/23/token-authentication-aspnetcore-complete-guide token ...
- [wiki] Unix like
1. Unix的发展历史 2. 纵向的图 3. 来源: https://zh.wikipedia.org/wiki/类Unix系统 4. 中文版 数种“类UNIX操作系统”的相互关系图 类Unix ...
- js 解决两值交换
总结七种办法来交换a和b的变量值 交换变量值方案一 最最最简单的办法就是使用一个临时变量了 不过使用临时变量的方法实在是太low了 var t; t = a; a = b; b = t; 首先把a ...