Spark环境搭建(三)-----------yarn环境搭建及测试作业提交
配置好HDFS之后,接下来配置单节点的yarn环境
1,修改配置文件
文件 : /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site-xml
插入
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
文件: /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml
插入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2,启动yarn
命令: sbin/start.yarn.sh
3,验证yarn启动成功
1) 命令:jps
显示
7945 Jps
6227 SecondaryNameNode
6060 DataNode
5745 NameNode
5031 NodeManager
4922 ResourceManager
2) 浏览器:
http://hadoop001:8088/
4,提交作业到yarn执行(以wordcount为例)
1) 现将一个文本文件上传到HDFS中
2)执行一个Jar文件,使用命令
hadoop jar /home/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /data/wc-text.txt /output/wc/
3) 使用浏览器查看任务
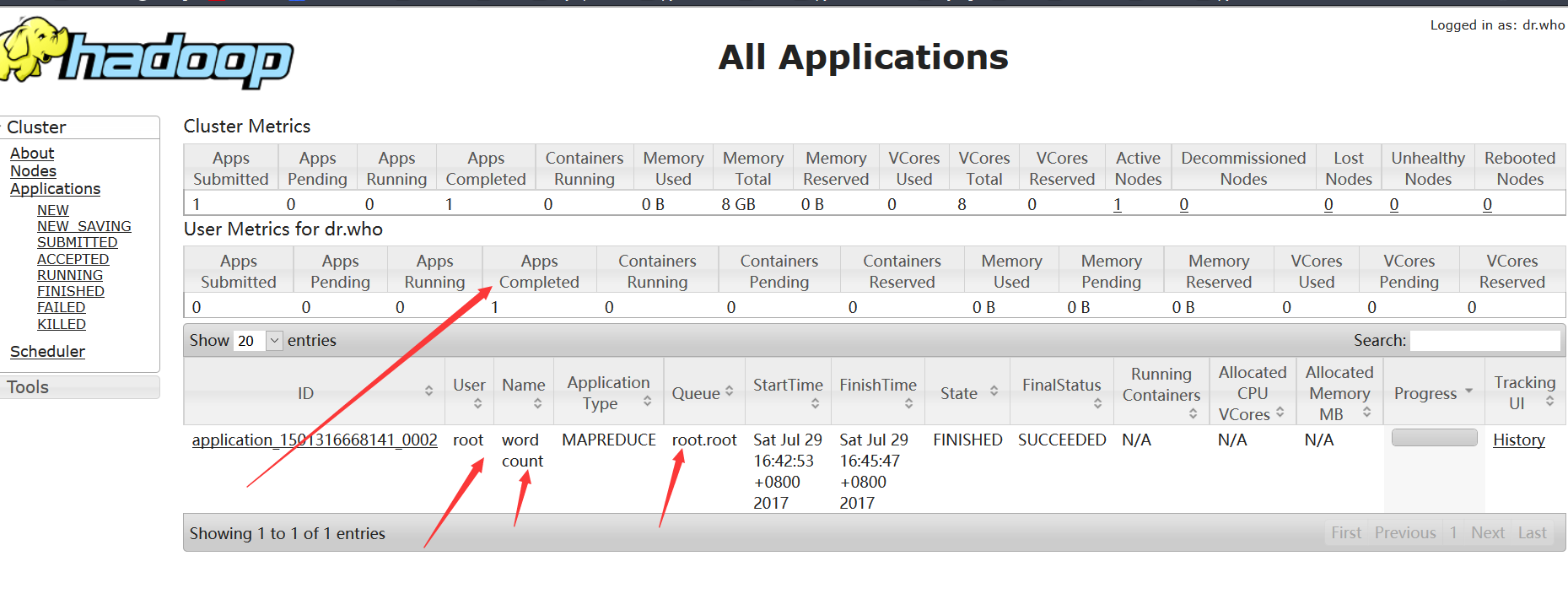
4)在HDFS中查看结果
命令: hadoop fs -ls -R /
hadoop fs -cat /output/wc/part-r-00000
5)结果:

原文件:

至此,yarn环境搭建完毕
Spark环境搭建(三)-----------yarn环境搭建及测试作业提交的更多相关文章
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建三:配置spring并测试
这一部分的主要目的是 配置spring-service.xml 也就是配置spring 并测试service层 是否配置成功 用IntelliJ IDEA 开发Spring+SpringMVC+M ...
- Java学习笔记之linux配置java环境变量(三种环境变量)
0x00 压安装jdk 在shell终端下进入jdk-6u14-linux-i586.bin文件所在目录, 执行命令 ./jdk-6u14-linux-i586.bin 这时会出现一段协议,连继敲回车 ...
- 【源码学习之spark core 1.6.1 standalone模式下的作业提交】
说明:个人原创,转载请说明出处 http://www.cnblogs.com/piaolingzxh/p/5656876.html 未完待续
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(2 配置spring-dao和测试)
用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(1 搭建目录环境和依赖) 四:在\resources\spring 下面 ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
- Spark开发环境搭建和作业提交
Spark高可用集群搭建 在所有节点上下载或上传spark文件,解压缩安装,建立软连接 配置所有节点spark安装目录下的spark-evn.sh文件 配置slaves 配置spark-default ...
- 搭建Data Mining环境(Spark版本)
前言:工欲善其事,必先利其器.倘若不懂得构建一套大数据挖掘环境,何来谈Data Mining!何来领悟“Data Mining Engineer”中的工程二字!也仅仅是在做数据分析相关的事罢了!此文来 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
随机推荐
- request对象的方法及其参数的传递
先设计一个简单的登录界面index.htm: <html><head><title>request的使用</title></head>< ...
- 搭建vsf
参考: 1.https://blog.csdn.net/liuzhenwen/article/details/7026263 我是全部替换了/lib/为/lib64/ 2.https://blog.c ...
- qt: 系统默认程序打开文件或者软件;
Qt提供了QDesktopServices类, 可以利用openUrl函数调用默认程序打开文件: 源码参考: #ifdef Q_OS_WIN32 m_szHelpDoc = QString(" ...
- 分布式监控系统开发【day37】:服务端生成配置数据(四)
一.目录结构 二.引子与代码 1.客户端获取服务列表接口 1.解决了什么问题 客户端要给我获取服务列表的的时候,他肯定要告诉他是谁?他怎么告诉我,客户端必须有一个id号 Saltsack你装一个客户端 ...
- flyway和liquibase的使用样例
在代码上我们有svn和git等诸多的版本控制方法. 但是在数据库上却没有相应的工具.一度导致多环境见的数据库同步难以维持. flyway和liquibase都是常见的数据库版本控制工具. flyway ...
- Vim使用技巧:将Tab转换为4个空格
一 Tab转成4个空格 为了防止因为在不同系统中Tab键的宽度不一致而导致代码缩进显示混乱的情况,有必要将Tab键转换成空格,推荐的空格数为4.将下面的代码写入你的.vimrc文件中即可实现在Vim编 ...
- 第九节:基于MVC5+AutoFac+EF+Log4Net的基础结构搭建
一. 前言 从本节开始,将陆续的介绍几种框架搭建组合形式,分析每种搭建形式的优势和弊端,剖析搭建过程中涉及到的一些思想和技巧. (一). 技术选型 1. DotNet框架:4.6 2. 数据库访问:E ...
- JGUI源码:Accordion鼠标中键滚动和手机端滑动实现(2)
本文是抽屉组件在PC端滚动鼠标中键.手机端滑动时,滚动数据列表实现方法,没有使用iscroll等第三方插件,支持火狐,谷歌,IE8+等浏览器. 演示在:www.jgui.com Github地址:ht ...
- $L^p$ 调和函数恒为零
设 $u$ 是 $\bbR^n$ 上的调和函数, 且 $$\bex \sen{u}_{L^p}=\sex{\int_{\bbR^n}|u(y)|^p\rd y}^{1/p}<\infty. \e ...
- Maven 构建浏览器解析userAgent类
创建Maven项目 添加pom.xml 依赖 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&qu ...