Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中。
目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/top250
1)确定目标网站的请求头:
打开目标网站,在网页空白处点击鼠标右键,选择“检查”。(小编使用的是谷歌浏览器)。
点击“network”,在弹出页面若长时间没有数据显示,则试一下F5刷新。
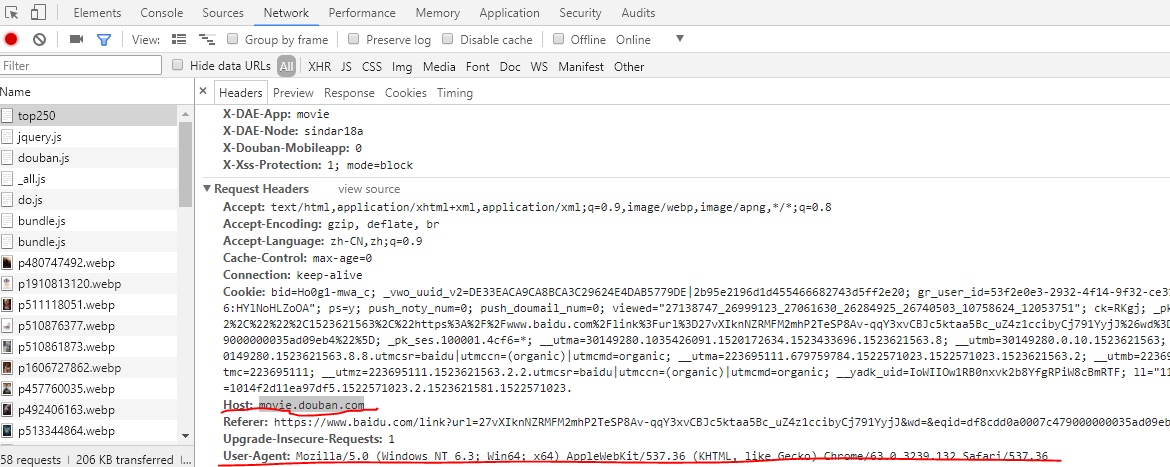
可以得到目标网页中Host和User-Agent两项。
2)找到爬取目标数据(即电影名称)在页面中的位置
右键“检查”,选择“Elements”。
或者直接找到一个电影名称,比如《肖申克的救赎》,对它右键,选择“检查”。
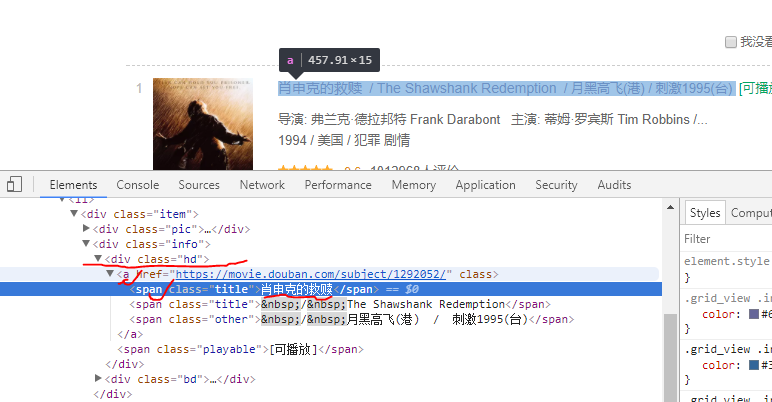
3)相关代码:
import requests
from bs4 import BeautifulSoup
def get_movies():
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host':'movie.douban.com'
} #定义爬取目标网页的请求头,务必和我们前面通过‘检查’到的请求头一致
movie_list=[]
for i in range(0,10): #目标所包含的250项数据分布在10页之中
link='https://movie.douban.com/top250?start='+str(i*25) #定义每页的网址
r=requests.get(link,headers=headers,timeout=10) #构建每页中的抓取请求request
print (str(i+1),'页码响应状态码:',r.status_code)
soup=BeautifulSoup(r.text,'lxml') #使用BeautifulSoup模块对抓取到的网页内容进行解析
div_list=soup.find_all('div',class_='hd') #将得到的目标电影数据所在的div存储到list中
for each in div_list:
movie=each.a.span.text.strip() #获取精确的目标电影数据(即电影名字)
movie_list.append(movie)
return movie_list
movies=get_movies()
print(movies)
输出:
1 页码响应状态码: 200
2 页码响应状态码: 200
3 页码响应状态码: 200
4 页码响应状态码: 200
5 页码响应状态码: 200
6 页码响应状态码: 200
7 页码响应状态码: 200
8 页码响应状态码: 200
9 页码响应状态码: 200
10 页码响应状态码: 200
['肖申克的救赎', '霸王别姬', '这个杀手不太冷', '阿甘正传', '美丽人生', '千与千寻', '泰坦尼克号', '辛德勒的名单', '盗梦空间', '机器人总动员', '海上钢琴师', '三傻大闹宝莱坞', '忠犬八公的故事', '放牛班的春天', '大话西游之大圣娶亲', '楚门的世界', '龙猫', '教父', '熔炉', '星际穿越', '乱世佳人', '触不可及', '无间道', '当幸福来敲门', '天堂电影院', '怦然心动', '十二怒汉', '搏击俱乐部', '少年派的奇幻漂流', '鬼子来了', '蝙蝠侠:黑暗骑士', '指环王3:王者无敌', '活着', '天空之城', '疯狂动物城', '罗马假日', '大话西游之月光宝盒', '飞屋环游记', '窃听风暴', '两杆大烟枪', '飞越疯人院', '控方证人', '闻香识女人', '哈尔的移动城堡', '海豚湾', 'V字仇杀队', '辩护人', '死亡诗社', '教父2', '美丽心灵', '指环王2:双塔奇兵', '指环王1:魔戒再现', '情书', '饮食男女', '摔跤吧!爸爸', '美国往事', '狮子王', '钢琴家', '天使爱美丽', '七宗罪', '素媛', '被嫌弃的松子的一生', '小鞋子', '致命魔术', '看不见的客人', '音乐之声', '勇敢的心', '剪刀手爱德华', '本杰明·巴顿奇事', '低俗小说', '西西里的美丽传说', '拯救大兵瑞恩', '黑客帝国', '沉默的羔羊', '入殓师', '蝴蝶效应', '让子弹飞', '玛丽和马克思', '春光乍泄', '大闹天宫', '心灵捕手', '阳光灿烂的日子', '幽灵公主', '末代皇帝', '第六感', '重庆森林', '禁闭岛', '大鱼', '布达佩斯大饭店', '狩猎', '哈利·波特与魔法石', '射雕英雄传之东成西就', '致命ID', '甜蜜蜜', '断背山', '一一', '告白', '猫鼠游戏', '阳光姐妹淘', '加勒比海盗', '上帝之城', '摩登时代', '穿条纹睡衣的男孩', '阿凡达', '爱在黎明破晓前', '消失的爱人', '风之谷', '爱在日落黄昏时', '侧耳倾听', '倩女幽魂', '红辣椒', '超脱', '恐怖直播', '萤火虫之墓', '驯龙高手', '幸福终点站', '菊次郎的夏天', '小森林 夏秋篇', '喜剧之王', '岁月神偷', '借东西的小人阿莉埃蒂', '神偷奶爸', '七武士', '杀人回忆', '海洋', '真爱至上', '电锯惊魂', '贫民窟的百万富翁', '谍影重重3', '喜宴', '东邪西毒', '记忆碎片', '雨人', '怪兽电力公司', '疯狂原始人', '黑天鹅', '英雄本色', '燃情岁月', '卢旺达饭店', '虎口脱险', '恋恋笔记本', '海边的曼彻斯特', '傲慢与偏见', '7号房的礼物', '哈利·波特与死亡圣器(下)', '小森林 冬春篇', '萤火之森', '完美的世界', '教父3', '纵横四海', '二十二', '魂断蓝桥', '猜火车', '荒蛮故事', '穿越时空的少女', '玩具总动员3', '花样年华', '雨中曲', '唐伯虎点秋香', '超能陆战队', '时空恋旅人', '我是山姆', '蝙蝠侠:黑暗骑士崛起', '人工智能', '心迷宫', '浪潮', '冰川时代', '香水', '朗读者', '罗生门', '追随', '爆裂鼓手', '一次别离', '撞车', '未麻的部屋', '可可西里', '请以你的名字呼唤我', '战争之王', '血战钢锯岭', '地球上的星星', '恐怖游轮', '梦之安魂曲', '达拉斯买家俱乐部', '被解救的姜戈', '阿飞正传', '牯岭街少年杀人事件', '谍影重重', '谍影重重2', '魔女宅急便', '碧海蓝天', '忠犬八公物语', '惊魂记', '头脑特工队', '房间', '再次出发之纽约遇见你', '青蛇', '秒速5厘米', '哪吒闹海', '东京物语', '海盗电台', '末路狂花', '绿里奇迹', '终结者2:审判日', '源代码', '模仿游戏', '勇闯夺命岛', '新龙门客栈', '黑客帝国3:矩阵革命', '这个男人来自地球', '卡萨布兰卡', '一个叫欧维的男人决定去死', '城市之光', '变脸', '荒野生存', '迁徙的鸟', '你的名字。', 'E.T. 外星人', '初恋这件小事', '无耻混蛋', '发条橙', '美国丽人', '黄金三镖客', '英国病人', '小萝莉的猴神大叔', '爱在午夜降临前', '燕尾蝶', '无人知晓', '非常嫌疑犯', '叫我第一名', '穆赫兰道', '疯狂的石头', '勇士', '无敌破坏王', '国王的演讲', '步履不停', '血钻', '上帝也疯狂', '彗星来的那一夜', '枪火', '蓝色大门', '大卫·戈尔的一生', '遗愿清单', '我爱你', '千钧一发', '荒岛余生', '爱·回家', '黑鹰坠落', '麦兜故事', '暖暖内含光', '聚焦']
完成既定目标。
4)进阶拓展
爬取TOP250电影的英文名。
import requests
from bs4 import BeautifulSoup
def get_movies():
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host':'movie.douban.com'
}
movie_list=[]
for i in range(0,10):
link='https://movie.douban.com/top250?start='+str(i*25)
r=requests.get(link,headers=headers,timeout=10)
print (str(i+1),'页码响应状态码:',r.status_code)
soup=BeautifulSoup(r.text,'lxml')
div_list=soup.find_all('div',class_='hd')
for each in div_list:
# movie=each.a.span.text.strip()
movie=each.a.contents[3].text.strip()
movie=movie[2:]
movie_list.append(movie)
#print(each.a.contents[3].text.strip())
return movie_list
movies=get_movies()
print(movies)
注意到更改部分为for循环中的部分。
代码中,
each.a.span只会定位到a标签下第一个span标签的内容。
each.a.contents则会定位到a标签下所有的子标签内容(包括换行符‘\n’),例如在for循环中添加一句print(each.a.contents),则输出内容为(以“肖申克的救赎一项为例展示”):
['\n', <span class="title">肖申克的救赎</span>, '\n', <span class="title"> / The Shawshank Redemption</span>, '\n', <span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>, '\n']
即包括换行符“\n”,所以若用 each.a.contents[0] 定位到的则是开头的换行符,不是我们需要的有价值的信息。
故我们需要的部分的索引应为3(英文名),当我们直接用 movie=each.a.contents[3].text.strip() 进行输出时候,则发现输出的为(以“肖申克的救赎一项为例展示”):
['/\xa0The Shawshank Redemption',
我们发现在英文名前面有一个“/”(这个是网页页面文本中本来就有的),还有一个“\xa0”,这个代表不间断空白符
注意:若遇到“\u3000”,则表示全角的空白符。
参考博客:https://www.cnblogs.com/BlackStorm/p/6359005.html
故需要 movie=movie[2:] 进行截取。
修改后的代码运行结果为:
1 页码响应状态码: 200
2 页码响应状态码: 200
3 页码响应状态码: 200
4 页码响应状态码: 200
5 页码响应状态码: 200
6 页码响应状态码: 200
7 页码响应状态码: 200
8 页码响应状态码: 200
9 页码响应状态码: 200
10 页码响应状态码: 200
['The Shawshank Redemption', '再见,我的妾 / Farewell My Concubine', 'Léon', 'Forrest Gump', 'La vita è bella', '千と千尋の神隠し', 'Titanic', "Schindler's List", 'Inception', 'WALL·E', "La leggenda del pianista sull'oceano", '3 Idiots', "Hachi: A Dog's Tale", 'Les choristes', '西遊記大結局之仙履奇緣', 'The Truman Show', 'となりのトトロ', 'The Godfather', '도가니', 'Interstellar', 'Gone with the Wind', 'Intouchables', '無間道', 'The Pursuit of Happyness', 'Nuovo Cinema Paradiso', 'Flipped', '12 Angry Men', 'Fight Club', 'Life of Pi', 'Devils on the Doorstep', 'The Dark Knight', 'The Lord of the Rings: The Return of the King', '人生 / Lifetimes', '天空の城ラピュタ', 'Zootopia', 'Roman Holiday', '西遊記第壹佰零壹回之月光寶盒', 'Up', 'Das Leben der Anderen', 'Lock, Stock and Two Smoking Barrels', "One Flew Over the Cuckoo's Nest", 'Witness for the Prosecution', 'Scent of a Woman', 'ハウルの動く城', 'The Cove', 'V for Vendetta', '변호인', 'Dead Poets Society', 'The Godfather: Part Ⅱ', 'A Beautiful Mind', 'The Lord of the Rings: The Two Towers', 'The Lord of the Rings: The Fellowship of the Ring', 'Love Letter', '飲食男女', 'Dangal', 'Once Upon a Time in America', 'The Lion King', 'The Pianist', "Le fabuleux destin d'Amélie Poulain", 'Se7en', '소원', '嫌われ松子の一生', 'بچههای آسمان', 'The Prestige', 'Contratiempo', 'The Sound of Music', 'Braveheart', 'Edward Scissorhands', 'The Curious Case of Benjamin Button', 'Pulp Fiction', 'Malèna', 'Saving Private Ryan', 'The Matrix', 'The Silence of the Lambs', 'おくりびと', 'The Butterfly Effect', '让子弹飞一会儿 / 火烧云', 'Mary and Max', '春光乍洩', '大闹天宫 上下集 / The Monkey King', 'Good Will Hunting', 'In the Heat of the Sun', 'もののけ姫', 'The Last Emperor', 'The Sixth Sense', '重慶森林', 'Shutter Island', 'Big Fish', 'The Grand Budapest Hotel', 'Jagten', "Harry Potter and the Sorcerer's Stone", '射鵰英雄傳之東成西就', 'Identity', 'Comrades: Almost a Love Story', 'Brokeback Mountain', 'Yi yi / Yi yi: A One and a Two', '自白 / 母亲', 'Catch Me If You Can', '써니', 'Pirates of the Caribbean: The Curse of the Black Pearl', 'Cidade de Deus', 'Modern Times', 'The Boy in the Striped Pajamas', 'Avatar', 'Before Sunrise', 'Gone Girl', '風の谷のナウシカ', 'Before Sunset', '耳をすませば', '倩女幽魂(87版) / A Chinese Ghost Story', 'パプリカ', 'Detachment', '더 테러 라이브', '火垂るの墓', 'How to Train Your Dragon', 'The Terminal', '菊次郎の夏', 'リトル・フォレスト 夏・秋', '喜劇之王', '歲月神偷', '借りぐらしのアリエッティ', 'Despicable Me', '七人の侍', '살인의 추억', 'Océans', 'Love Actually', 'Saw', 'Slumdog Millionaire', 'The Bourne Ultimatum', '囍宴', '東邪西毒', 'Memento', 'Rain Man', 'Monsters, Inc.', 'The Croods', 'Black Swan', 'A Better Tomorrow / Gangland Boss', 'Legends of the Fall', 'Hotel Rwanda', 'La grande vadrouille', 'The Notebook', 'Manchester by the Sea', 'Pride & Prejudice', '7번방의 선물', 'Harry Potter and the Deathly Hallows: Part 2', 'リトル・フォレスト 冬・春', '蛍火の杜へ', 'A Perfect World', 'The Godfather: Part III', '緃横四海', 'Twenty Two / 22', 'Waterloo Bridge', 'Trainspotting', 'Relatos salvajes', '時をかける少女', 'Toy Story 3', '花樣年華', "Singin' in the Rain", '唐伯虎點秋香', 'Big Hero 6', 'About Time', 'I Am Sam', 'The Dark Knight Rises', 'Artificial Intelligence: AI', '殡棺 / The Coffin in the Mountain', 'Die Welle', 'Ice Age', 'Perfume: The Story of a Murderer', 'The Reader', '羅生門', 'Following', 'Whiplash', 'جدایی نادر از سیمین', 'Crash', 'Perfect Blue', 'Kekexili: Mountain Patrol', 'Call Me by Your Name', 'Lord of War', 'Hacksaw Ridge', 'Taare Zameen Par', 'Triangle', 'Requiem for a Dream', 'Dallas Buyers Club', 'Django Unchained', '阿飛正傳', '牯嶺街少年殺人事件', 'The Bourne Identity', 'The Bourne Supremacy', '魔女の宅急便', 'Le grand bleu', 'ハチ公物語', 'Psycho', 'Inside Out', 'Room', 'Begin Again', 'Green Snake', '秒速5センチメートル', "Prince Nezha's Triumph Against Dragon King / Nezha nao hai", '東京物語', 'The Boat That Rocked', 'Thelma & Louise', 'The Green Mile', 'Terminator 2: Judgment Day', 'Source Code', 'The Imitation Game', 'The Rock', '新龍門客棧', 'The Matrix Revolutions', 'The Man from Earth', 'Casablanca', 'En man som heter Ove', 'City Lights', 'Face/Off', 'Into the Wild', 'Le peuple migrateur', '君の名は。', 'E.T.: The Extra-Terrestrial', 'สิ่งเล็กเล็กที่เรียกว่า...รัก', 'Inglourious Basterds', 'A Clockwork Orange', 'American Beauty', 'Il buono, il brutto, il cattivo.', 'The English Patient', 'Bajrangi Bhaijaan', 'Before Midnight', 'スワロウテイル', '誰も知らない', 'The Usual Suspects', 'Front of the Class', 'Mulholland Dr.', 'Crazy Stone', 'Warrior', 'Wreck-It Ralph', "The King's Speech", '歩いても 歩いても', 'Blood Diamond', 'The Gods Must Be Crazy', 'Coherence', '鎗火', '藍色大門', 'The Life of David Gale', 'The Bucket List', '그대를 사랑합니다', 'Gattaca', 'Cast Away', '집으로...', 'Black Hawk Down', '麥兜故事', 'Eternal Sunshine of the Spotless Mind', 'Spotlight']
其中for循环中内容的修改方法来自于BeautifulSoup的官网文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/#name
参考书目:唐松,来自《Python 网络爬虫:从入门到实践》
Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据的更多相关文章
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- python网络爬虫-静态网页抓取(四)
静态网页抓取 在网站设计中,纯HTML格式的网页通常被称之为静态网页,在网络爬虫中静态网页的数据比较容易抓取,因为说有的数据都呈现在网页的HTML代码中.相对而言使用Ajax动态加载的玩个的数据不一定 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- Python开源爬虫项目代码:抓取淘宝、京东、QQ、知网数据--转
数据来源:数据挖掘入门与实战 公众号: datadw scrapy_jingdong[9]- 京东爬虫.基于scrapy的京东网站爬虫,保存格式为csv.[9]: https://github.co ...
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
- BT网站--Python开发爬虫代替.NET
BT网站-奥修磁力-Python开发爬虫代替.NET写的爬虫,主要演示访问速度和在一千万左右的HASH记录中索引效率. IBMID 磁力下载- WWW.IBMID.COM 现在用的是Python + ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
随机推荐
- SQL Server Cast、Convert数据类型转换
一.概述 本篇文章转载来着官网在线文档,文章主要介绍SQL Server数据类型转换相关语法.隐式转换.Date样式等. 语法 Syntax for CAST: CAST ( expression A ...
- Hystrix概念设计
1. Hystrix概念设计 1.1. 大纲 1.2. 基本的容错模式 1.3. 断路器模式 1.4. 舱壁隔离模式 1.5. 容错理念 凡事依赖都可能失败 凡事资源都有限制 网络并不可靠 延迟是应用 ...
- Npoi简单读写Excel
什么是NPOI ? 简而言之,NPOI就是可以在没有Office的情况下对Word或Excel文档进行读写等操作. 使用方式 : 1.准备NPOI的dll文件 下载链接:https://npoi.co ...
- 【git】idea /git bash命令 操作分支
1.需求 因为目前要对项目做一些改动,而项目又即将上线,这些新的改动又不需要一起上线,所以这个时候需要在原有的master分支上重新拉出一个分支进行开发. 2.分支操作 打开git bash工具→切换 ...
- .NET Core实战项目之CMS 第十一章 开发篇-数据库生成及实体代码生成器开发
上篇给大家从零开始搭建了一个我们的ASP.NET Core CMS系统的开发框架,具体为什么那样设计我也已经在第十篇文章中进行了说明.不过文章发布后很多人都说了这样的分层不是很合理,什么数据库实体应该 ...
- 『ice 离散化广搜』
ice(USACO) Description Bessie 在一个冰封的湖面上游泳,湖面可以表示为二维的平面,坐标范围是-1,000,000,000..1,000,000,000. 湖面上的N(1 & ...
- HashTable与ConcurrentHashMap的区别
- JVM垃圾回收
1. 概念理解 1.1. 并行(Parallel)与并发(Concurrent) 并行:指多个垃圾收集线程并行工作,但此时用户线程仍然处于等待状态 并发:指用户线程与垃圾收集线程同时执行 1.2. ...
- Gulp介绍与入门实践
Gulp,一个基于流的构建工具. 这是自己写的一个构建的demo,只是一个纯演示的示例,并没有完成什么项目工作.下面根据这个demo介绍一下Gulp. 上代码: gulpfile.js 'use st ...
- JSP面试题都在这里
下面是我整理下来的JSP知识点: 图上的知识点都可以在我其他的文章内找到相应内容. JSP常见面试题 jsp静态包含和动态包含的区别 jsp静态包含和动态包含的区别 在讲解request对象的时候,我 ...