Spark SQL官网阅读笔记
Spark SQL是Spark中用于结构化数据处理的组件。
Spark SQL可以从Hive中读取数据。
执行结果是Dataset/DataFrame。
DataFrame是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
DataSet是Spark 1.6之后加入的,同时提供了RDD和Spark SQL执行引擎的优点。可以从jvm对象创建,然后通过transformation算子(map, flatMap, filter, etc)转换得到。
DataFrame被DataSet中的RowS替代。
Scala中用DataSet[Row],Java中用DataSet<Row>。
SparkSession
Spark中所有功能的入口点是SparkSession类(Spark 1.x叫SQLContext http://spark.apache.org/docs/2.0.0/api/java/index.html#org.apache.spark.sql.SparkSession)
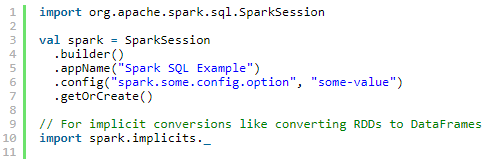
Spark 2.0内置支持Hive,如使用HiveQL查询,访问Hive UDFs,从Hive获取数据。不需要安装Hive。
创建DataFrames
使用SparkSession,可以从已有的RDD,Hive表,或Spark数据源创建DataFrames。
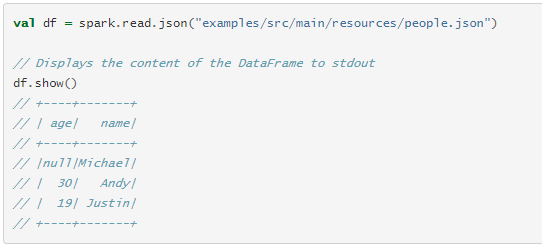
Dataset 操作(也叫做 DataFrame 操作)
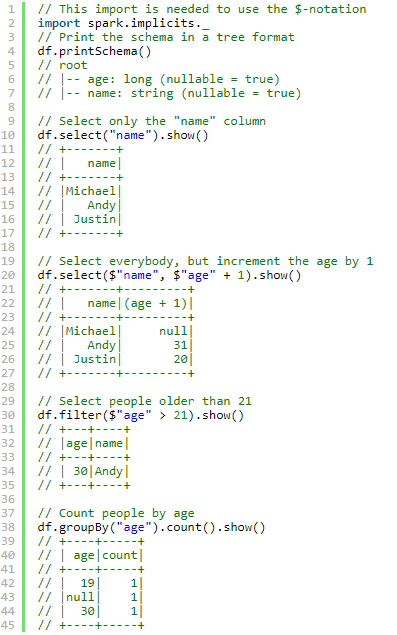
API文档: http://spark.apache.org/docs/2.0.0/api/scala/index.html#org.apache.spark.sql.Dataset
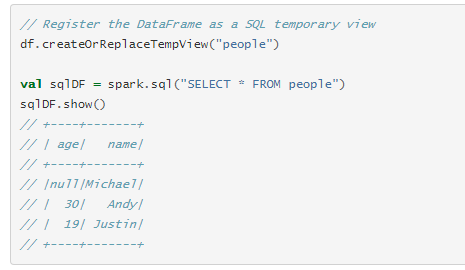
运行 SQL 查询
查询结果是DataFrame类型。
创建 Datasets
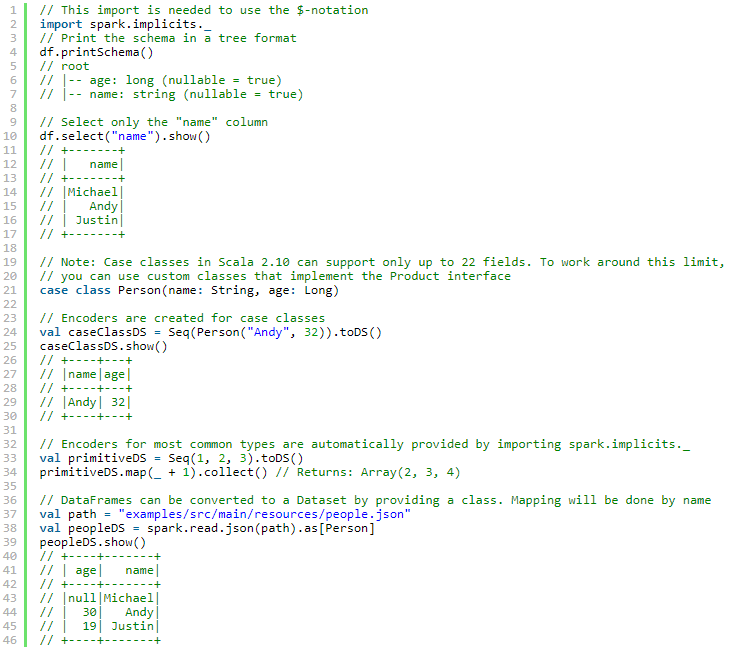
与RDD互操作
两种方式
1.反射
这种基于反射的方法可以得到更简洁的代码,并且在编写Spark应用程序时,当已经知道模式时,它可以很好地工作。
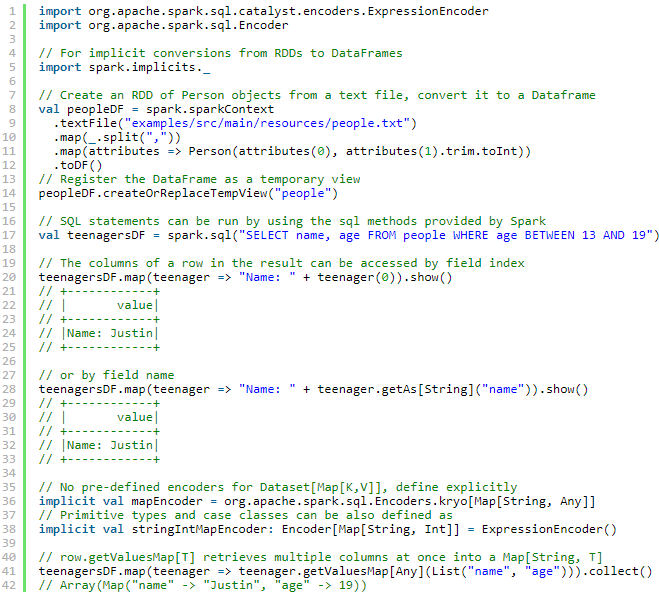
2.通过编程接口创建
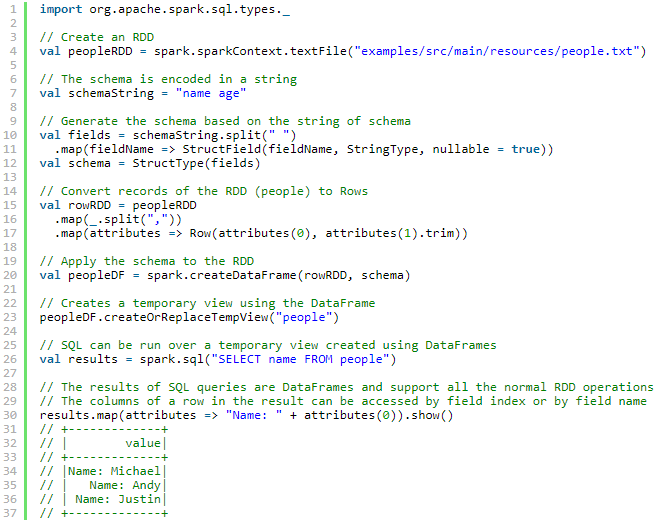
数据源
load、save
1. 默认数据源
parquet

2.手动指定

3.在文件上直接运行SQL

保存模式
保存操作的时候可以指定一个SaveMode

存储到持久化表中
可以使用saveAsTable将DataFrame存储到Hive metastore中。saveAsTable会实例化在Hive metastore中的DataFrame内容,并创建一个指针指向它。持久化表会一直存在,即使重启了Spark,只要保持同一个metastore的连接。
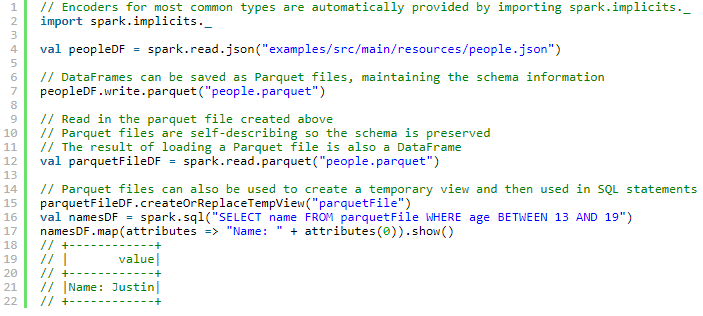
Parquet 文件
Spark SQL支持对Parquet文件的读写。
分区发现
表分区是Hive等系统中常用的优化方法。
从spark 1.6.0开始,默认情况下,分区发现仅查找给定路径下的分区
Schema 合并
和 ProtocolBuffer, Avro, and Thrift, Parquet 也支持schema变化。可以增加列。
但是代价高。
1.5.0之后默认被关闭了。
Hive metastore 和Parquet table的转换
当从Hive metastore中读写Parquet table时,Spark SQL为了更好的性能,会尝试使用它自己的支持而不是Hive SerDe。这个行为由spark.sql.hive.convertMetastoreParquet配置,默认开启。
Metadata 刷新
Spark SQL缓存了Parquet metadata
// spark is an existing SparkSession
spark.catalog.refreshTable("my_table")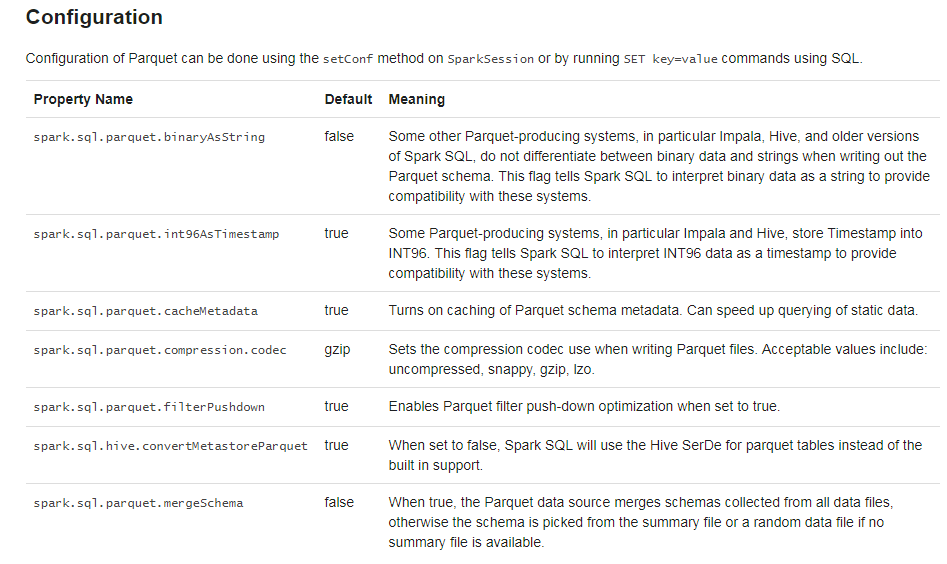
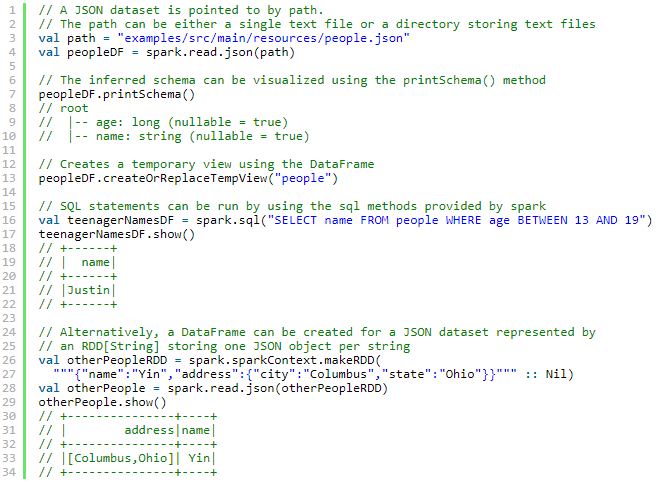
JSON Datasets
请注意,作为JSON文件提供的文件不是典型的JSON文件。每一行必须包含一个独立的、自包含的有效JSON对象。因此,常规的多行JSON文件通常会失败。
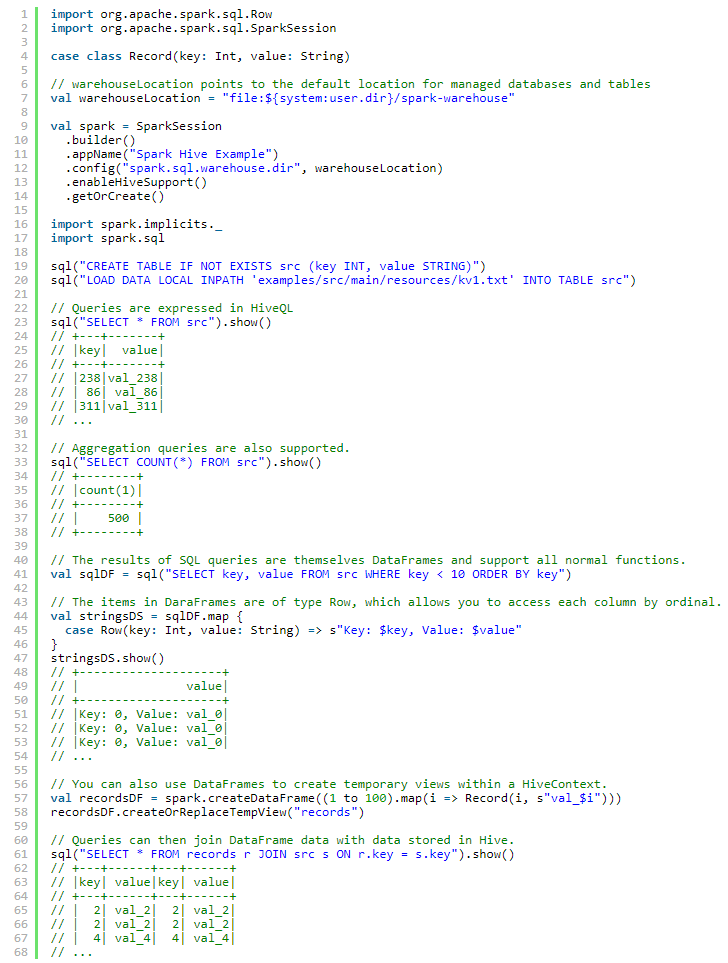
Hive Tables
Spark SQL支持读写存储在Hive中的数据
注意hive-site.xml 中的hive.metastore.warehouse.dir 从Spark 2.0.0开始已经过时了,用spark.sql.warehouse.dir.
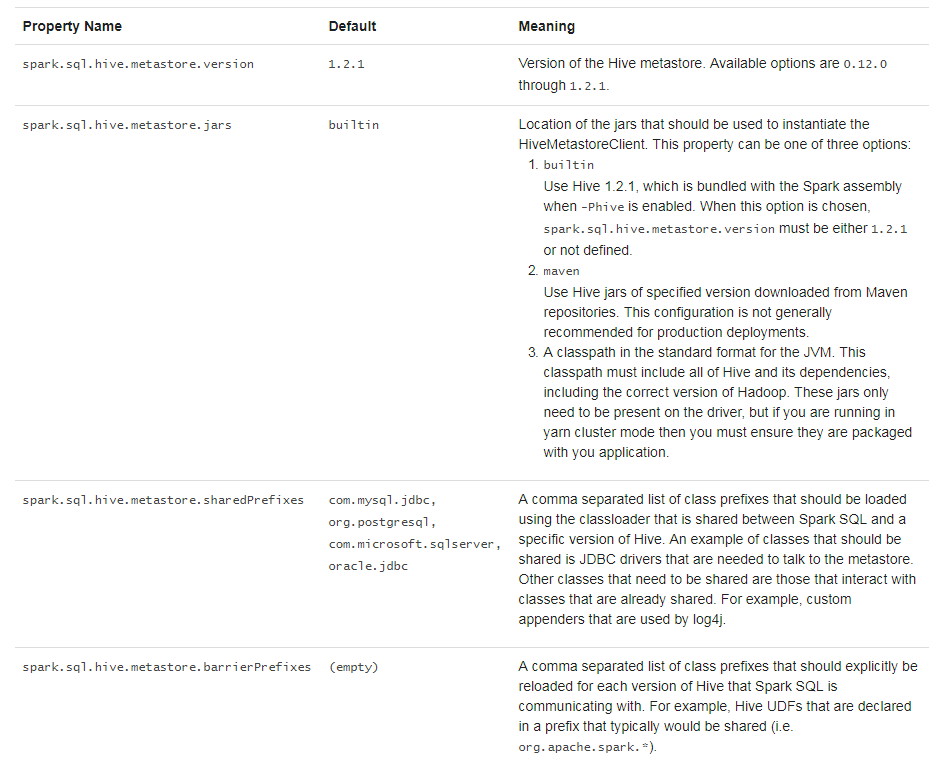
与不同版本的Hive metastore交互
使用JDBC和其它数据库交互
最好使用JdbcRDD
性能调优
可以通过调用spark.cacheTable("tableName") 或 dataFrame.cache().使Spark SQL以列格式缓存表。然后spark sql将只扫描所需的列,并自动调整压缩以最小化内存使用和GC压力。
调用spark.uncacheTable("tableName")移除缓存中表。
通过SparkSession或在SQL中以SET Key = Value形式来设置。

分布式SQL引擎
Spark SQL还可以使用其JDBC/ODBC或命令行接口作为分布式查询引擎。在这种模式下,最终用户或应用程序可以直接与Spark SQL交互以运行SQL查询,而无需编写任何代码。
运行Thrift JDBC/ODBC服务器
./sbin/start-thriftserver.sh
This script accepts all bin/spark-submit command line options, plus a --hiveconf option to specify Hive properties. You may run ./sbin/start-thriftserver.sh --help for a complete list of all available options. By default, the server listens on localhost:10000. You may override this behaviour via either environment variables, i.e.:
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh \
--master <master-uri> \
...or system properties:
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...Now you can use beeline to test the Thrift JDBC/ODBC server:
./bin/beeline
Connect to the JDBC/ODBC server in beeline with:
beeline> !connect jdbc:hive2://localhost:10000
Spark SQL官网阅读笔记的更多相关文章
- Spring官网阅读 | 总结篇
接近用了4个多月的时间,完成了整个<Spring官网阅读>系列的文章,本文主要对本系列所有的文章做一个总结,同时也将所有的目录汇总成一篇文章方便各位读者来阅读. 下面这张图是我整个的写作大 ...
- Spring官网阅读(十八)Spring中的AOP
文章目录 什么是AOP AOP中的核心概念 切面 连接点 通知 切点 引入 目标对象 代理对象 织入 Spring中如何使用AOP 1.开启AOP 2.申明切面 3.申明切点 切点表达式 excecu ...
- Spring官网阅读(十六)Spring中的数据绑定
文章目录 DataBinder UML类图 使用示例 源码分析 bind方法 doBind方法 applyPropertyValues方法 获取一个属性访问器 通过属性访问器直接set属性值 1.se ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- Spring官网阅读(十七)Spring中的数据校验
文章目录 Java中的数据校验 Bean Validation(JSR 380) 使用示例 Spring对Bean Validation的支持 Spring中的Validator 接口定义 UML类图 ...
- Spring官网阅读(三)自动注入
上篇文章我们已经学习了1.4小结中关于依赖注入跟方法注入的内容.这篇文章我们继续学习这结中的其他内容,顺便解决下我们上篇文章留下来的一个问题-----注入模型. 文章目录 前言: 自动注入: 自动注入 ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
- Spring官网阅读(十一)ApplicationContext详细介绍(上)
文章目录 ApplicationContext 1.ApplicationContext的继承关系 2.ApplicationContext的功能 Spring中的国际化(MessageSource) ...
随机推荐
- 学习STM32F769DK-OTA例程之百度云平台建立MQTT服务器
@2019-04-17 [小记] 百度云平台建立MQTT服务器时需要设置权限组,否则连接失败
- ubuntu18.04安装mysql
ubuntu18.04中,默认情况下mysql默认包含在apt软件存储库中,要安装它只需要更新服务器上的包索引并安装默认包apt-get. 1.安装mysql sudo apt-get update ...
- 转载:Linux命令之查看文件占用空间大小-du,df
转载自:<du命令>-linux命令五分钟系列之三 du(disk usage),顾名思义,查看目录/文件占用空间大小 #查看当前目录下的所有目录以及子目录的大小$ du -h $ du ...
- Windows 10 x64 下编译 Hadoop 源码
Windows 10 x64 下编译 Hadoop 源码 环境准备 Hadoop并没有提供官方的 Windows 10 下的安装包,所以需要自己手动来编译,官方文档中 BUILDING.txt 文件中 ...
- 001 Nibiru SDK 调试工具介绍
为方便调试 Unity 项目,Nibiru 提供调试工具用于模拟手柄键值或直连主机手 柄 要求:Unity 开发环境和调试工具运行在同一台电脑上 Nibiru SDK 调试工具主要用于开发过程中对操控 ...
- Oracle DB 总结(SQL)
--SQL结构查询语言 数据库定义语言(DDL)用于建立.删除和修改数据库对象 CREATE ALTER DROP TRUNCATE 数据库操纵语言(DML)用于改变数据库表中的数据 INSERT U ...
- Python——使用第三方库Pillow生成图片缩略图
流程如下: 1.首先确认是否安装了pip 在命令提示符窗口下输入pip,如果Windows提示未找到命令,可以重新运行安装程序添加pip. 2.在命令提示符窗口下输入pip install Pillo ...
- js中函数和方法的区别
函数(function)是一段代码,需要通过名字来进行调用.它能将一些数据(函数的参数)传递进去进行处理,然后返回一些数据(函数的返回值),也可以不返回数据. 方法(method)是通过对象调用的ja ...
- 获取iframe 内容
parent.$.find("iframe")[0].contentWindow.getvalue(); h.find("iframe")[0].content ...
- 2018-2019-2 20165234 《网络对抗技术》 Exp1 PC平台逆向破解
实验一 PC平台逆向破解 实验目的 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另 ...