CvT: Introducing Convolutions to Vision Transformers-首次将Transformer应用于分类任务
CvT: Introducing Convolutions to Vision Transformers
Paper:https://arxiv.org/pdf/2103.15808.pdf
Code:https://github.com/rishikksh20/convolution-vision-transformers/
Motivation:在相似尺寸下,VIT的性能要弱于CNN架构;VIT所需的训练数据量要远远大于CNN模型
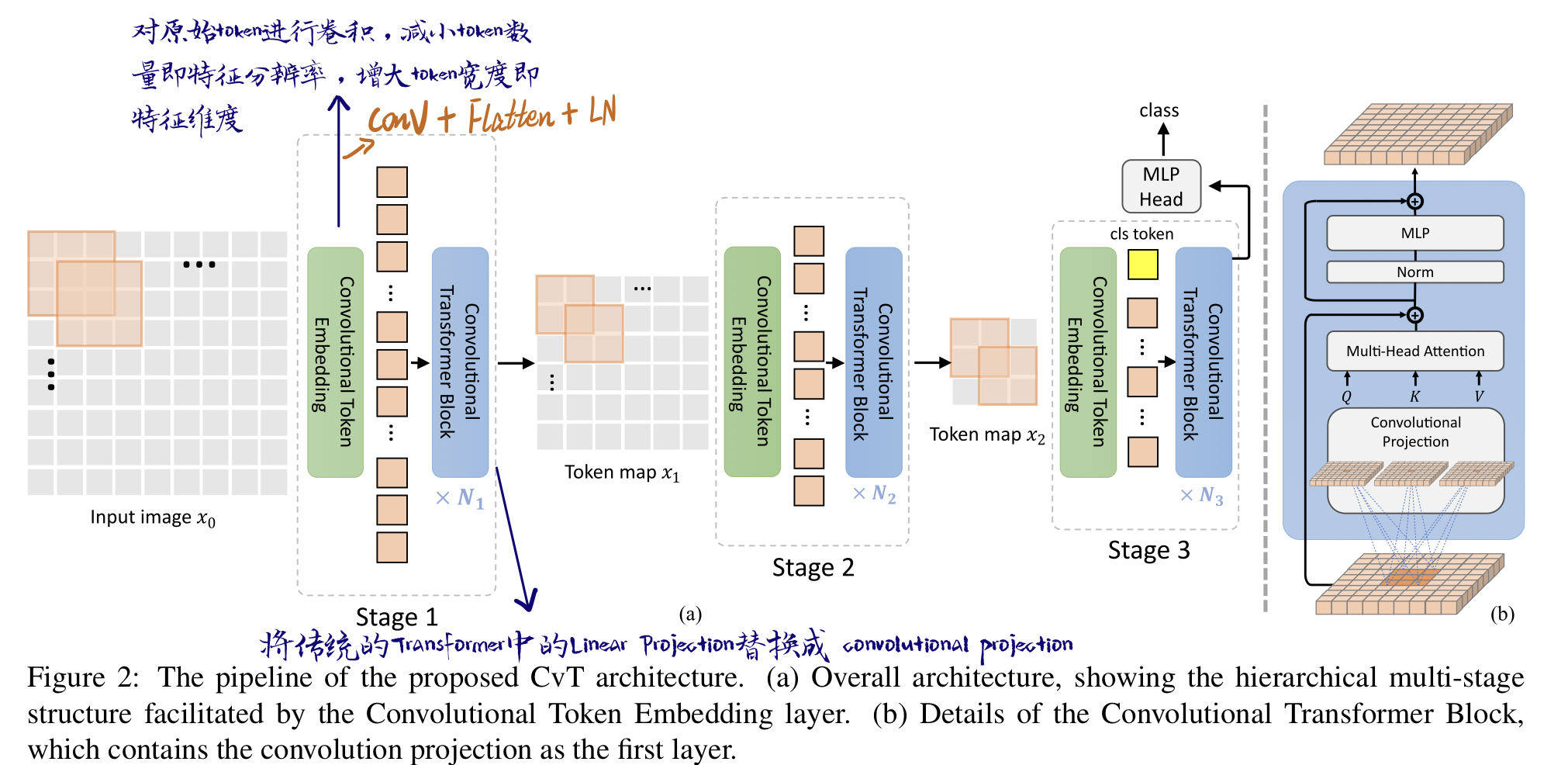
CvT将卷积引入Transformer,总架构是一个multi-stage的hierarchical的结构:
首先embedding的方式变成了卷积操作,在每个Multi-head self-attention之前都进行Convolutional Token Embedding。其次在 Self-attention的Projection操作不再使用传统的Linear Projection,而是使用Convolutional Projection。
Linear Projection->convolutional Projection
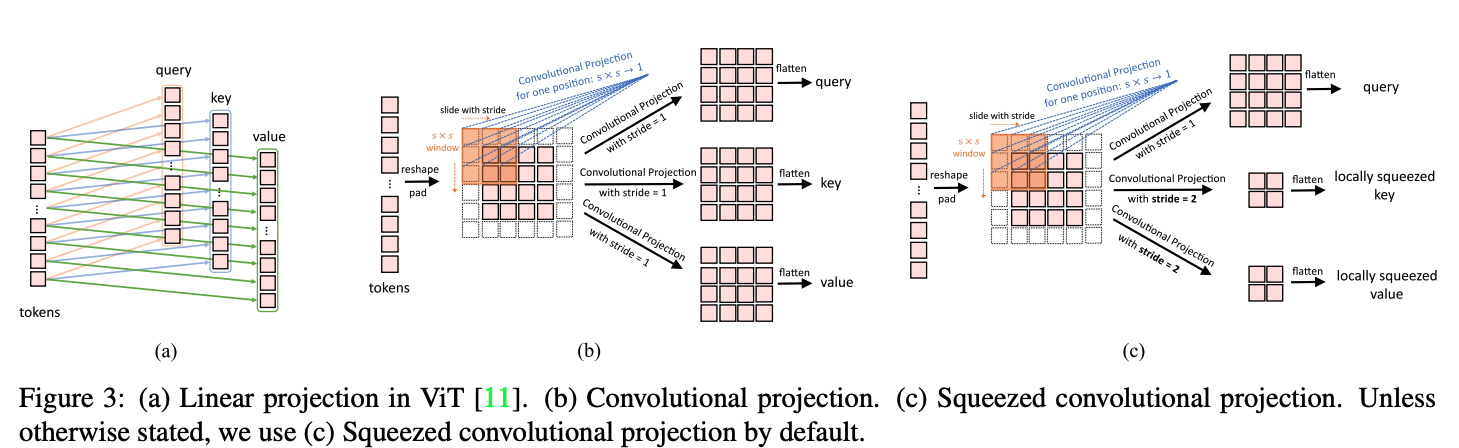
(c)这一步可以补偿分辨率下降的损失
为什么不用位置编码:卷机操作的zero-padding暗含位置信息
CvT: Introducing Convolutions to Vision Transformers-首次将Transformer应用于分类任务的更多相关文章
- How Do Vision Transformers Work?[2202.06709] - 论文研读系列(2) 个人笔记
[论文简析]How Do Vision Transformers Work?[2202.06709] 论文题目:How Do Vision Transformers Work? 论文地址:http:/ ...
- EdgeFormer: 向视觉 Transformer 学习,构建一个比 MobileViT 更好更快的卷积网络
前言 本文主要探究了轻量模型的设计.通过使用 Vision Transformer 的优势来改进卷积网络,从而获得更好的性能. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟 ...
- ICCV2021 | 重新思考视觉transformers的空间维度
论文:Rethinking Spatial Dimensions of Vision Transformers 代码:https://github.com/naver-ai/pit 获取:在CV技 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- Transformers 简介(下)
作者|huggingface 编译|VK 来源|Github Transformers是TensorFlow 2.0和PyTorch的最新自然语言处理库 Transformers(以前称为pytorc ...
- 利用 iOS 14 Vision 的手势估测功能 实作无接触即可滑动的 Tinder App
Vision 框架在 2017 年推出,目的是为了让行动 App 开发者轻松利用电脑视觉演算法.具体来说,Vision 框架中包含了许多预先训练好的深度学习模型,同时也能充当包裹器 (wrapper) ...
- CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
前言 本文深入探讨了如何设计神经网络.如何使得训练神经网络具有更加优异的效果,以及思考网络设计的物理意义. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘 ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 机器学习(ML)十一之CNN各种模型
深度卷积神经网络(AlexNet) 在LeNet提出后的将近20年里,神经网络一度被其他机器学习方法超越,如支持向量机.虽然LeNet可以在早期的小数据集上取得好的成绩,但是在更大的真实数据集上的表现 ...
随机推荐
- 查找大文件-清理linux磁盘
https://www.cnblogs.com/kerrycode/p/4391859.html find . -type f -size +800M -print0 | xargs -0 du - ...
- safari iframe 滚动问题(iframe--- iphone中的iframe没有滚动,要设置滚动;)
_::-webkit-full-page-media, _:future, :root #frameBody>.frame-pnl{ overflow:auto; -webkit-overflo ...
- 力扣53. 最大子数组和(dp)
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和. 子数组 是数组中的一个连续部分. 示例 1: 输入:nums = [-2,1,-3,4,-1 ...
- Yolov3-v5正负样本匹配机制
本文来自公众号"AI大道理". 什么是正负样本? 正负样本是在训练过程中计算损失用的,而在预测过程和验证过程是没有这个概念的. 正样本并不是手动标注的GT. 正负样本都是针 ...
- 如何使用css绘制三角形
背景 用迪卡侬官方主页进行页面练习,发现头部导航栏需要使用到梯形 分析 图形分解 通过图片我们可以发现该梯形可以分解成一个长方形和一个直角三角形,长方形:110*65:直角三角形:11*65(底边*另 ...
- jeecgboot <j-popup
<a-col :span="24"> <a-form-item label=" 规格" :labelCol="labelCol&qu ...
- 从各种点理解Unity中的协程
这个写的很好,https://zhuanlan.zhihu.com/p/59619632
- win的安全更新安装不成功,可用下面命令进行强制更新
- iOS的一些性能优化
1. 卡顿优化-CPU 尽量使用轻量级的对象,比如用不到事件处理的地方,可以考虑使用CALayer取代UIView 不要频繁地调用UIView的相关属性,比如frame.bounds.tranform ...
- linux安装IB驱动
一.准备 1.Linux操作系统7.6(根据实际情况变更,此处用redhat7.6系统举例) 2.驱动:MLNX_OFED_LINUX-4.6-1.0.1.1-rhel7.6-x86_64.tgz(根 ...