CvT: Introducing Convolutions to Vision Transformers-首次将Transformer应用于分类任务
CvT: Introducing Convolutions to Vision Transformers
Paper:https://arxiv.org/pdf/2103.15808.pdf
Code:https://github.com/rishikksh20/convolution-vision-transformers/
Motivation:在相似尺寸下,VIT的性能要弱于CNN架构;VIT所需的训练数据量要远远大于CNN模型
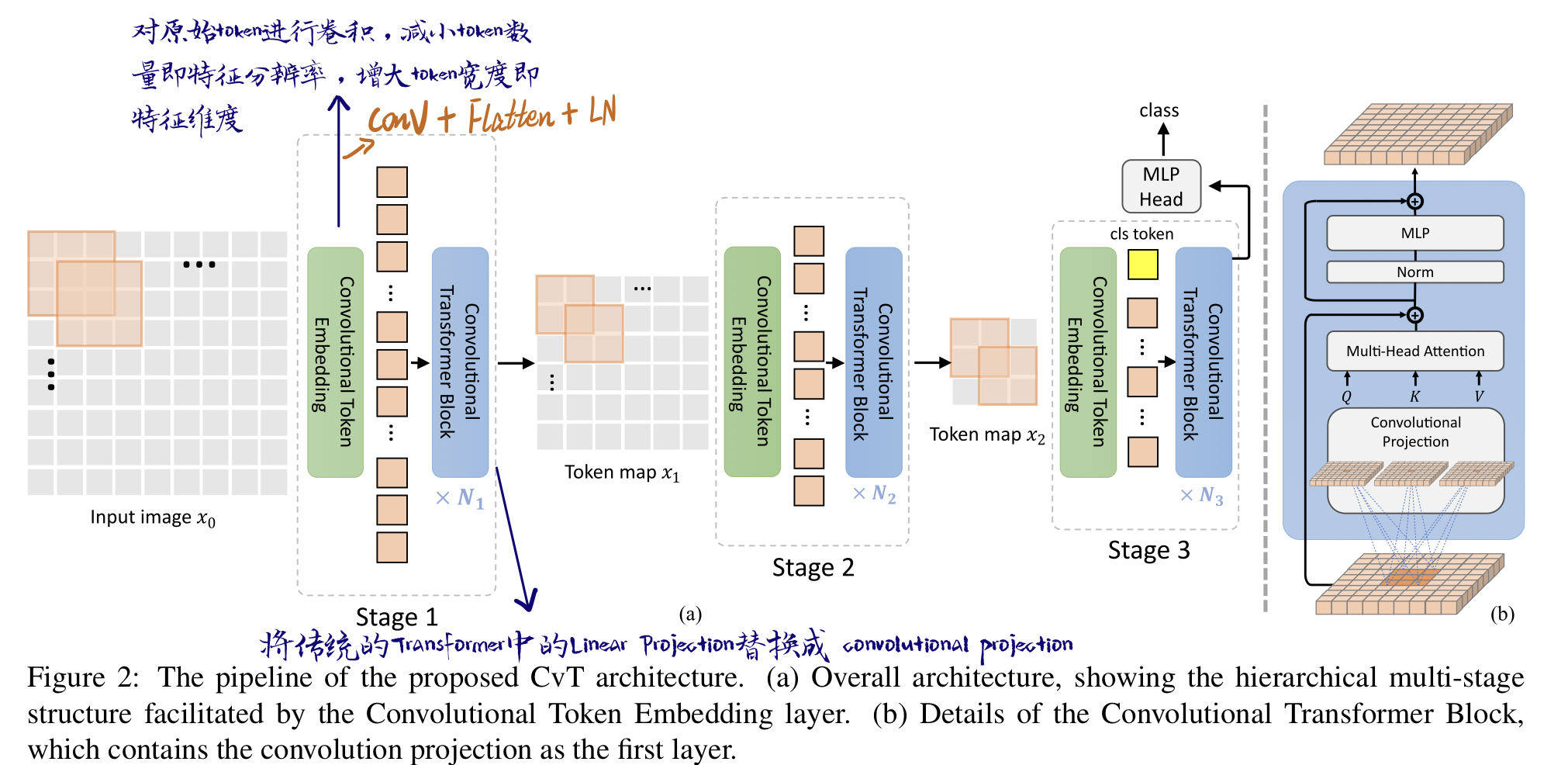
CvT将卷积引入Transformer,总架构是一个multi-stage的hierarchical的结构:
首先embedding的方式变成了卷积操作,在每个Multi-head self-attention之前都进行Convolutional Token Embedding。其次在 Self-attention的Projection操作不再使用传统的Linear Projection,而是使用Convolutional Projection。
Linear Projection->convolutional Projection
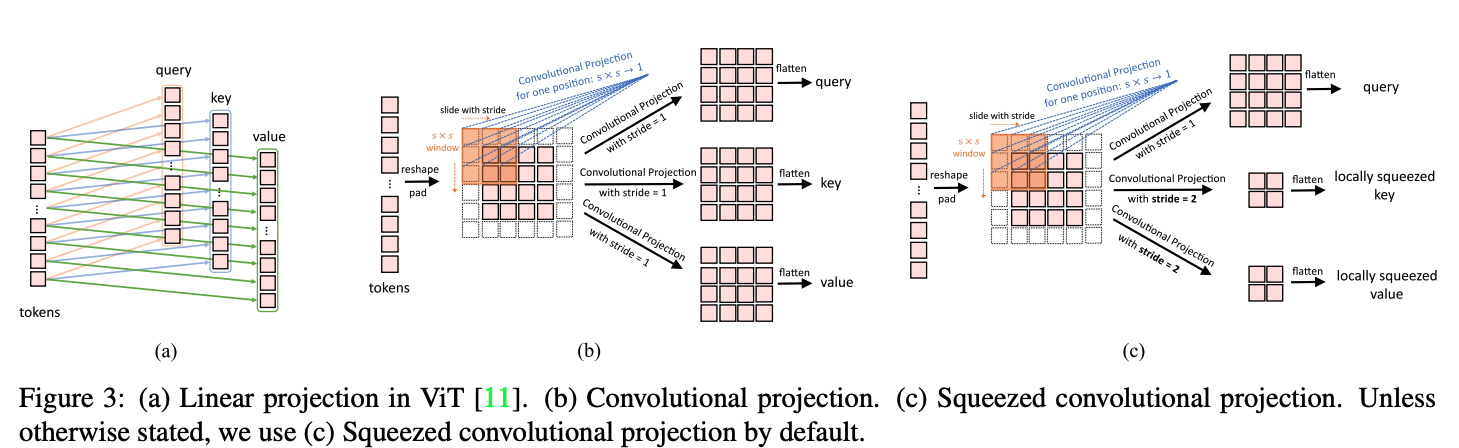
(c)这一步可以补偿分辨率下降的损失
为什么不用位置编码:卷机操作的zero-padding暗含位置信息
CvT: Introducing Convolutions to Vision Transformers-首次将Transformer应用于分类任务的更多相关文章
- How Do Vision Transformers Work?[2202.06709] - 论文研读系列(2) 个人笔记
[论文简析]How Do Vision Transformers Work?[2202.06709] 论文题目:How Do Vision Transformers Work? 论文地址:http:/ ...
- EdgeFormer: 向视觉 Transformer 学习,构建一个比 MobileViT 更好更快的卷积网络
前言 本文主要探究了轻量模型的设计.通过使用 Vision Transformer 的优势来改进卷积网络,从而获得更好的性能. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟 ...
- ICCV2021 | 重新思考视觉transformers的空间维度
论文:Rethinking Spatial Dimensions of Vision Transformers 代码:https://github.com/naver-ai/pit 获取:在CV技 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- Transformers 简介(下)
作者|huggingface 编译|VK 来源|Github Transformers是TensorFlow 2.0和PyTorch的最新自然语言处理库 Transformers(以前称为pytorc ...
- 利用 iOS 14 Vision 的手势估测功能 实作无接触即可滑动的 Tinder App
Vision 框架在 2017 年推出,目的是为了让行动 App 开发者轻松利用电脑视觉演算法.具体来说,Vision 框架中包含了许多预先训练好的深度学习模型,同时也能充当包裹器 (wrapper) ...
- CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
前言 本文深入探讨了如何设计神经网络.如何使得训练神经网络具有更加优异的效果,以及思考网络设计的物理意义. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘 ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 机器学习(ML)十一之CNN各种模型
深度卷积神经网络(AlexNet) 在LeNet提出后的将近20年里,神经网络一度被其他机器学习方法超越,如支持向量机.虽然LeNet可以在早期的小数据集上取得好的成绩,但是在更大的真实数据集上的表现 ...
随机推荐
- gird 布局控制元素都显示在一行
gird 布局控制元素都显示在一行 <ul class="list"> <li v-for="(li, index) in list" :ke ...
- Django的urls的配置
在一个请求到达的时候,最先达到的就是视图层,然后根据url映射到视图函数.这一部分我们来说明url的配置. 概述 为了给一个应用设计URL,你需要创建一个Python 模块,通常称为URLconf(U ...
- fetchAll 的小小分析
includes\database\prefetch.inc line 425 $this->defaultFetchStyle: fetch_object int 5protected $de ...
- vue html转pdf并打印
//文件名随便取一个如:htmlToPdf.js // 导出页面为PDF格式 import html2Canvas from 'html2canvas' import JsPDF from 'jspd ...
- vue-awesome-swiper使用中的一些问题
项目中使用了vue-awesome-swiper,发现autoplay不能用.网上找了半天,说是版本问题.最后在main.js中添加以下代码解决. import VueAwesomeSwiper fr ...
- 【Python】容器:列表(list)/字典(dict)/元组(tuple)/集合(set)
三.Python容器:列表(list)/字典(dict)/元组(tuple)/集合(set) 1.列表(list) 1.1 什么是列表 是一个'大容器',可以存储N多个元素简单来说就是其他语言中的数组 ...
- HTML语言基本标签
创建一个HTML文档 <html></html> 设置文档标题以及其他不在WEB网页上显示的信息 <head></head> 设置文档的可见部分 < ...
- css如何将content、background、background-image生成的背景进行翻转
方法 transform: scaleX(-1); 本例是水平翻转180度,方向可修改X为Y/Z. 注意如果是content,需要设置display: inline-block/block;
- Pytorch Dropout函数
Dropout layers class torch.nn.Dropout(p=0.5, inplace=False) 随机将输入张量中部分元素设置为0.对于每次前向调用,被置0的元素都是随机的. 参 ...
- Webservice EASLogin登录接口说明
https://club.kingdee.com/forum.php?mod=viewthread&tid=1332944