VSCode一键接入Notebook体验算法套件快速完成水表读数
摘要:本示例围绕真实AI需求场景,介绍VSCode一键接入Notebook体验算法套件快速完成水表读数的使用流程。
本文分享自华为云社区《VSCode一键接入Notebook体验算法套件快速完成水表读数》,作者:HWCloudAI。
本示例围绕真实AI需求场景,介绍VSCode一键接入Notebook体验算法套件快速完成水表读数的使用流程。
算法开发套件中目前提供自研(ivg系列)和开源(mm系列)共两套算法资产,可应用于分类、检测、分割和OCR等任务中。本示例中将组合使用自研分割算法(ivgSegmentation)和开源OCR算法(mmOCR)完成水表读数识别项目,并使用算法开发套件将其部署为华为云在线服务。
说明:
本案例教程仅适用于“华北-北京四”区域,新版Notebook。
准备数据
- 登录OBS控制台,创建OBS对象桶,区域选择“华北-北京四”。
- 登录ModelArts控制台,选择控制台区域为“华北-北京四”。
- 在“全局配置”页面查看是否已经配置授权,允许ModelArts访问OBS。如果没有配置授权,请参考配置访问授权(全局配置)添加授权。
- 分别下载本案例的数据集,水表表盘分割数据集和水表表盘读数OCR识别数据集到OBS桶中,OBS路径示例如下
obs://{OBS桶名称}/water_meter_segmentation 水表表盘分割数据集
obs://{OBS桶名称}/water_meter_crop 水表表盘读数OCR识别数据集
说明:
从AIGallery下载数据集免费,但是数据集存储在OBS桶中会收取少量费用,具体计费请参见OBS价格详情页,案例使用完成后请及时清除资源和数据。
准备开发环境
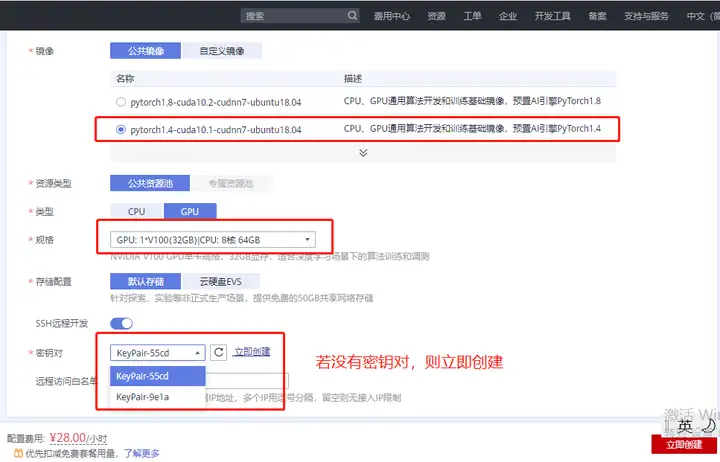
在“ModelArts控制台 > 开发环境 > Notebook(New)”页面中,创建基于pytorch1.4-cuda10.1-cudnn7-ubuntu18.04镜像,类型为GPU的Notebook,具体操作请参见创建Notebook实例章节。
本案例需要使用VS Code 远程连接Notebook,需要开启SSH远程开发。
图1 创建Notebook实例
1.实例的密钥文件需要下载至本地的如下目录或其子目录中:
Windows:C:\Users{{user}}
Mac/Linux: Users/{{user}}
2.在ModelArts控制台->开发环境 Notebook,单击“操作”列的“更多 > VS Code接入”。
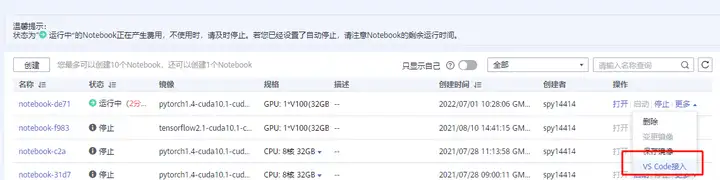
如果本地已安装VS Code,请单击“打开”,进入“Visual Studio Code”页面。
如果本地未安装VS Code,请根据实际选择“win”或“其他”下载并安装VS Code。VS Code安装请参考安装VS Code软件。
如果用户之前未安装过ModelArts VS Code插件,此时会弹出安装提示,请单击“Install and Open”进行安装;如果之前已经安装过插件,则不会有该提示,请跳过此步骤,直接执行后面步骤
安装过程预计1~2分钟,安装完成后右下角会弹出对话框,请单击“Reload Window and Open”。
在弹出的提示中,勾选“Don’t ask again for this extension”,然后单击"Open"。
3.远程连接Notebook实例。
- 远程连接执行前,会自动在(Windows:C:\Users{{user}}.ssh或者downloads,Mac/Linux: Users/{{user}}/.ssh或者downloads)目录下根据密钥名称查找密钥文件,如果找到则直接使用该密钥打开新窗口并尝试连接远程实例,此时无需选择密钥。
- 如果未找到会弹出选择框,请根据提示选择正确的密钥。
- 如果密钥选择错误,则弹出提示信息,请根据提示信息选择正确密钥。
- 当弹出提醒实例连接失败,请关闭弹窗,并查看OUTPUT窗口的输出日志,请查看FAQ并排查失败原因。
使用算法套件进行开发
Step1 创建算法工程
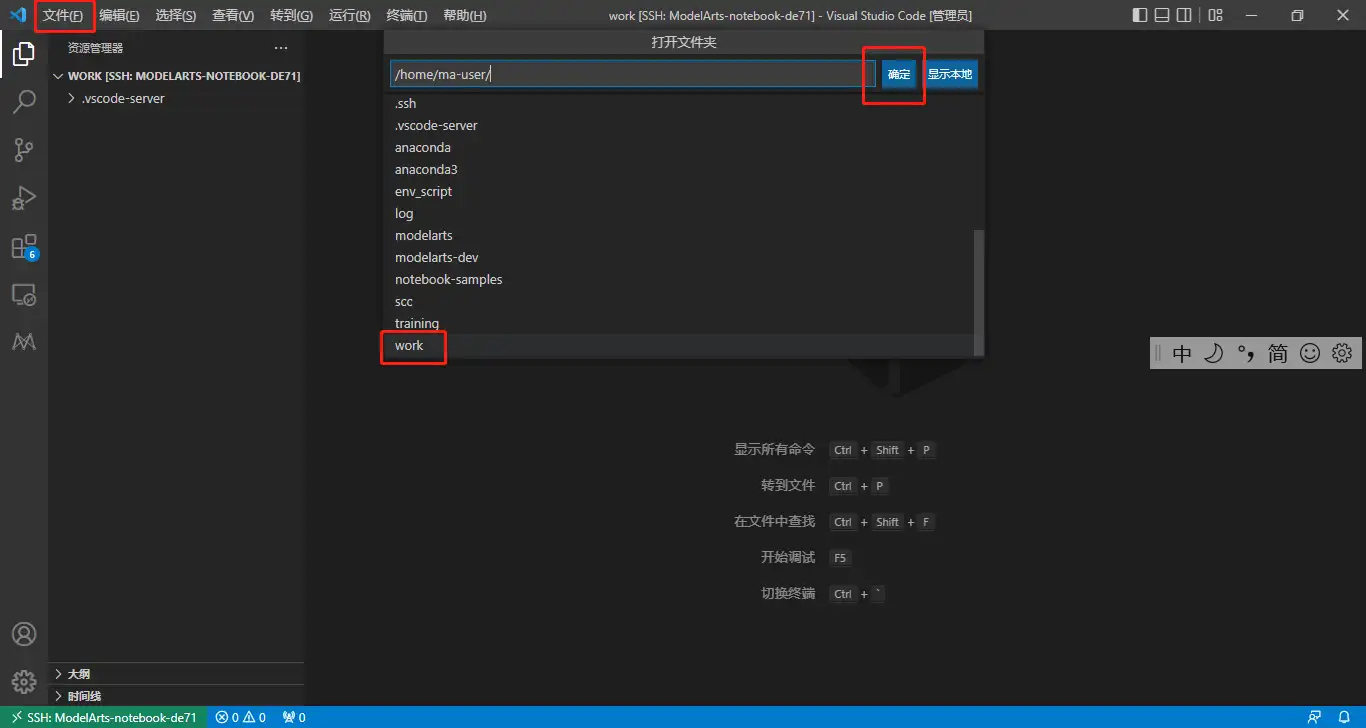
1.成功接入之后,在VS Code页面点击文件->打开文件夹,选择如下文件夹打开
2.新建终端
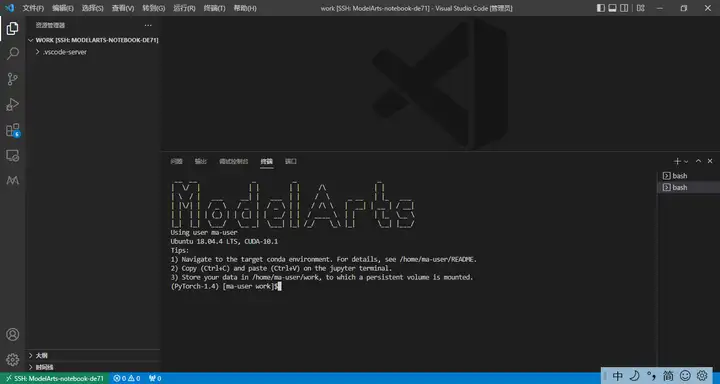
3.在work目录下执行
ma-cli createproject
命令创建工程,根据提示输入工程名称,例如:water_meter。然后直接回车选择默认参数,并选择跳过资产安装步骤(选择6)。

4.执行以下命令进入工程目录。
cd water_meter
5.执行以下命令拷贝项目数据到Notebook中。
python manage.py copy --source {obs_dataset_path} --dest ./data/raw/water_meter_crop
python manage.py copy --source {obs_dataset_path} --dest ./data/raw/water_meter_segmentation
说明:
{obs_dataset_path}路径为Step1 准备数据中下载到OBS中的数据集,比如“obs://{OBS桶名称}/water_meter_segmentation”和“obs://{OBS桶名称}/water_meter_crop”
Step2 使用deeplabv3完成水表区域分割任务
1.首先安装ivgSegmentation套件。
python manage.py install algorithm ivgSegmentation==1.0.2
如果提示ivgSegmentation版本不正确,可以通过命令python manage.py list algorithm查询版本。
2.安装ivgSegmentation套件后,在界面左侧的工程目录中进入“./algorithms/ivgSegmentation/config/sample”文件夹中查看目前支持的分割模型,以sample为例(sample默认的算法就是deeplabv3),文件夹中包括config.py(算法外壳配置)和deeplabv3_resnet50_standard-sample_512x1024.py(模型结构)。
3.表盘分割只需要区分背景和读数区域,因此属于二分类,需要根据项目所需数据集对配置文件进行修改,如下所示:
修改./algorithms/ivgSegmentation/config/sample/config.py文件。
# config.py
alg_cfg = dict(
...
data_root='data/raw/water_meter_segmentation', # 修改为真实路径本地分割数据集路径
...
)
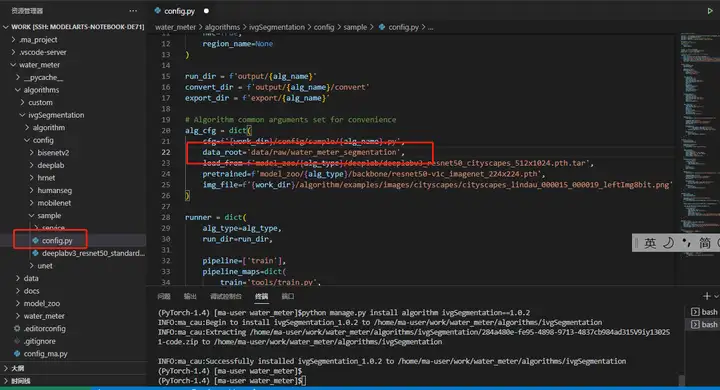
修改完后按Ctrl+S保存。
4.修改./algorithms/ivgSegmentation/config/sample/deeplabv3_resnet50_standard-sample_512x1024.py文件。
# deeplabv3_resnet50_standard-sample_512x1024.py
gpus=[0]
...
data_cfg = dict(
... num_classes=2, # 修改为2类
...
... train_scale=(512, 512), # (h, w)#size全部修改为(512, 512)
... train_crop_size=(512, 512), # (h, w)
... test_scale=(512, 512), # (h, w)
... infer_scale=(512, 512), # (h, w)
)

5.修改完按Ctrl+S保存。
6.在water_meter工程目录下,安装deeplabv3预训练模型。
python manage.py install model ivgSegmentation:deeplab/deeplabv3_resnet50_cityscapes_512x1024
7.训练分割模型。(推荐使用GPU进行训练)
# shell
python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --gpus 0
训练好的模型会保存在指定位置中,默认为output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/中。
8.验证模型效果。
模型训练完成后,可以在验证集上计算模型的指标,首先修改配置文件的模型位置。
修改./algorithms/ivgSegmentation/config/sample/config.py。
# config.py
alg_cfg = dict(
...
load_from='./output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/checkpoint_best.pth.tar', # 修改训练模型的路径
...
)
# shell
python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --pipeline evaluate
9.模型推理。
模型推理能够指定某一张图片,并且推理出图片的分割区域,并进行可视化,首先需要指定需要推理的图片路径。
修改./algorithms/ivgSegmentation/config/sample/config.py
alg_cfg = dict(
...
img_file = './data/raw/water_meter_segmentation/image/train_10.jpg' # 指定需要推理的图片路径
...
)
执行如下命令推理模型效果。
# shell
python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --pipeline infer
推理输出的图片路径在./output/deeplabv3_resnet50_standard-sample_512x1024下。
10.导出SDK。
算法开发套件支持将模型导出成一个模型SDK,方便进行模型部署等下游任务。
# shell
python manage.py export --cfg algorithms/ivgSegmentation/config/sample/config.py --is_deploy
Step3 水表读数识别
1.首先安装mmocr套件。
python manage.py install algorithm mmocr
2.安装mmocr套件后,./algorithms/mmocr/config/textrecog文件夹中包括config.py(算法外壳配置),需要根据所需算法和数据集路径修改配置文件。以下以robust_scanner算法为例。
修改./algorithms/mmocr/algorithm/configs/textrecog/robustscanner_r31_academic.py,
# robustscanner_r31_academic.py
...
train_prefix = 'data/raw/water_meter_crop/' # 修改数据集路径改为水表ocr识别数据集路径
train_img_prefix1 = train_prefix + 'train'
train_ann_file1 = train_prefix + 'train.txt'
test_prefix = 'data/raw/water_meter_crop/'
test_img_prefix1 = test_prefix + ‘val’
test_ann_file1 = test_prefix + ‘val.txt’
3.安装robust_scanner预训练模型。
python manage.py install model mmocr:textrecog/robust_scanner/robustscanner_r31_academic
4.训练OCR模型。
初次使用mmcv时需要编译mmcv-full,该过程较慢,可以直接使用官方预编译的依赖包。
预编译包URL: https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
pip install https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/mmcv_full-1.3.8-cp37-cp37m-manylinux1_x86_64.whl
将./algorithms/mmocr/config/textrecog/config.py中的epoch(迭代数量)改为2,如下图所示:
python manage.py run --cfg algorithms/mmocr/config/textrecog/config.py
训练好的模型会保存在指定位置中,默认为output/${algorithm}中。
5.验证模型效果。
模型训练完成后,可以在验证集上计算模型的指标,首先修改配置文件的模型位置。
修改./algorithms/mmocr/config/textrecog/config.py
# config.py
...
model_path = './output/robustscanner_r31_academic/latest.pth'
...
# shell
python manage.py run --cfg algorithms/mmocr/config/textrecog/config.py --pipeline evaluate
6.模型推理。
模型推理能够指定某一张图片,并且推理出图片的分割区域,并进行可视化。首先需要指定待推理的图片路径,修改algorithms/mmocr/config/textrecog/config.py文件,具体如下。
修改./algorithms/mmocr/algorithm/configs/textrecog/robust_scanner/config.py
...
infer_img_file='./data/raw/water_meter_crop/val/train_10.jpg' # 指定需要推理的图片路径
...
# shell
python manage.py run --cfg algorithms/mmocr/config/textrecog/config.py --pipeline infer
推理输出的图片路径在output/robustscanner_r31_academic/vis下
7.导出SDK。
# shell
python manage.py export --cfg algorithms/mmocr/config/textrecog/config.py
Step4 部署为在线服务
本次展示仅部署OCR服务, 包括本地部署和线上部署, 部署上线后调用部署服务进行本地图片的推理,获取水表的预测读数。部署在线服务,需要指定OBS桶以便保存部署所需要的文件。
1.在algorithms/mmocr/config/textrecog/config.py文件中配置OBS桶,即obs_bucket=<please input your own bucket here>。

2.执行下述命令:
python manage.py export --cfg algorithms/mmocr/config/textrecog/config.py --is_deploy # 导出部署模型
python manage.py deploy --cfg algorithms/mmocr/config/textrecog/config.py # 本地部署
python manage.py deploy --cfg algorithms/mmocr/config/textrecog/config.py --launch_remote#在线部署,会耗时一会儿,请耐心等待
点击此处,查看部署成功的在线服务
Step5 清除资源和数据
通过此示例学习完成创建算法套件流程后,如果不再使用,建议您清除相关资源,避免造成资源浪费和不必要的费用。
- 停止Notebook:在“Notebook”页面,单击对应实例操作列的“停止”。
- 删除数据:点击此处,前往OBS控制台,删除上传的数据,然后删除文件夹及OBS桶。
VSCode一键接入Notebook体验算法套件快速完成水表读数的更多相关文章
- Java实现 蓝桥杯VIP 算法提高 快速幂
算法提高 快速幂 时间限制:1.0s 内存限制:256.0MB 问题描述 给定A, B, P,求(A^B) mod P. 输入格式 输入共一行. 第一行有三个数,N, M, P. 输出格式 输出共一行 ...
- 纸壳CMS(ZKEACMS)体验升级,快速创建页面,直接在页面中修改内容
关于纸壳CMS 纸壳CMS又名 ZKEACMS Core 是ZKEACMS的 .net core 版本,可运行在 .net core 1.1 平台上.是一个开源的CMS. 纸壳CMS对于 ZKEACM ...
- Cloud Insight支持阿里云一键接入了,so what?
前几天 Cloud Insight 上线了一个新功能,考虑到目前只作为公测,所以只是是悄悄地加了一个接入项,希望你看完这偏文章会有兴趣体验一下. 相信体验过的用户(目前还是个位数)第一感受应该是:这个 ...
- (英文版)VScode一键生成.vue模板
1. 安装vscode,官网地址 2.安装一个插件,识别vue文件 插件库中搜索Vetur,下图中的第一个,点击安装(Install) 3.新建代码片段 点击Code(代码)-Preferences( ...
- 虹软人脸识别SDK接入Milvus实现海量人脸快速检索
一.背景 人脸识别是近年来最热门的计算机视觉领域的应用之一,而且现在已经出现了非常多的人脸识别算法,如:DeepID.FaceNet.DeepFace等等.人脸识别被广泛应用于景区.客运.酒店.办公室 ...
- leetcode算法思想快速一览
整理了一下思路,想深入了解还得多去写,无奈时间紧迫的情况下抛砖引玉也不失为下策: 1.Two Sum Easy 给出一个数组,找出其中两个和为目标值的坐标.思路: [1]排序. 和为目标值,一般的思路 ...
- KMP算法(快速模式匹配)
详细理解看这里:http://kb.cnblogs.com/page/176818/ 或者这里:http://blog.csdn.net/yutianzuijin/article/details/11 ...
- 【排序算法】快速插入排序算法 Java实现
基本思想 每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部插入完成. 设数组为a[0...n-1] 初始时,a[0]自成一个有序区,无序区为a[1...n-1] ...
- 关于vscode插件 的一些体验
一 vsCode git 首先vscode 继承了 git 在使用git前 先手动创建一个文件夹 用来clone已有项目 然后将 clone下来的项目放入工作区 右上角的小转转就是 pull文件 更 ...
- 从BZOJ2242看数论基础算法:快速幂,gcd,exgcd,BSGS
LINK 其实就是三个板子 1.快速幂 快速幂,通过把指数转化成二进制位来优化幂运算,基础知识 2.gcd和exgcd gcd就是所谓的辗转相除法,在这里用取模的形式体现出来 \(gcd(a,b)\) ...
随机推荐
- 17、输入一行以空格分隔的英文,判断其共有多少单词,不能包含冠词a
/*输入一行以空格分隔的英文,判断其共有多少单词,不能包含冠词a */ #include <stdio.h> #include <stdlib.h> int isWord(ch ...
- codeforces补题计划
11.15 Codeforces Round #833 (Div. 2) 知识点: D:高位和对低位无影响 E:笛卡尔树上dp 补题传送门
- Day18.2:对象创建的内存分析图解
对象创建的内存分析 我们从两块最常用的内存空间对对象创建进行内存分析 堆内存:存放的是对象的具体信息:在程序之中堆内存空间的开辟是通过new完成的 栈内存:存放的是对象的地址信息,即通过地址找到堆内存 ...
- (C++) C++ 中 shared_ptr weak_ptr
shared_ptr std::shared_ptr<int> sp1 = new int(); // shared count = 1, weak count = 0 std::shar ...
- Easy-Classification-验证码识别
1.背景 Easy-Classification是一个应用于分类任务的深度学习框架,它集成了众多成熟的分类神经网络模型,可帮助使用者简单快速的构建分类训练任务. 案例源代码 Easy-Classi ...
- 一文带你了解 Spring 的@Enablexxx 注解
layout: post categories: Java title: 一文带你了解 Spring 的@Enablexxx 注解 tagline: by 子悠 tags: - 子悠 前面的文章给大家 ...
- SSH(一)架包的引入
一年多未使用了,有些东西真的会忘. 一.ssh的图形化记忆运作流程 二.Struts2.hibernate.spring需要引用的jar包 Struts2: 基本开发:struts-2.3.32\ap ...
- Jmeter——结合Allure展示测试报告
在平时用jmeter做测试时,生成报告的模板,不是特别好.大家应该也知道allure报告,页面美观. 先来看效果图,报告首页,如下所示: 报告详情信息,如下所示: 运行run.py文件,运行成功,如下 ...
- 3.7V升压5V,3.7V转5V电路图芯片
锂离子电池在如今是广泛应用存在我们生活中的方方面面的电子产品中.如,电子玩具,美容仪,医疗产品,智能手表,手机,笔记本,电动汽车等等非常多. 锂电池3.7V升压到5V,3.7V转5V稳压输出的电子产品 ...
- Burpsuite2022.1详细图文安装教程(含工具链接)
应用概述: Burp Suite 是用于攻击web 应用程序的集成平台,包含了许多工具.Burp Suite为这些工具设计了许多接口,以加快攻击应用程序的过程.所有工具都共享一个请求,并能处理对应 ...