victoriaMetrics库之布隆过滤器
victoriaMetrics库之布隆过滤器
代码路径:/lib/bloomfilter
概述
victoriaMetrics的vmstorage组件会接收上游传递过来的指标,在现实场景中,指标或瞬时指标的数量级可能会非常恐怖,如果不限制缓存的大小,有可能会由于cache miss而导致出现过高的slow insert。
为此,vmstorage提供了两个参数:maxHourlySeries和maxDailySeries,用于限制每小时/每天添加到缓存的唯一序列。
唯一序列指表示唯一的时间序列,如
metrics{label1="value1",label2="value2"}属于一个时间序列,但多条不同值的metrics{label1="value1",label2="value2"}属于同一条时间序列。victoriaMetrics使用如下方式来获取时序的唯一标识:func getLabelsHash(labels []prompbmarshal.Label) uint64 {
bb := labelsHashBufPool.Get()
b := bb.B[:0]
for _, label := range labels {
b = append(b, label.Name...)
b = append(b, label.Value...)
}
h := xxhash.Sum64(b)
bb.B = b
labelsHashBufPool.Put(bb)
return h
}
限速器的初始化
victoriaMetrics使用了一个类似限速器的概念,限制每小时/每天新增的唯一序列,但与普通的限速器不同的是,它需要在序列级别进行限制,即判断某个序列是否是新的唯一序列,如果是,则需要进一步判断一段时间内缓存中新的时序数目是否超过限制,而不是简单地在请求层面进行限制。
hourlySeriesLimiter = bloomfilter.NewLimiter(*maxHourlySeries, time.Hour)
dailySeriesLimiter = bloomfilter.NewLimiter(*maxDailySeries, 24*time.Hour)
下面是新建限速器的函数,传入一个最大(序列)值,以及一个刷新时间。该函数中会:
- 初始化一个限速器,限速器的最大元素个数为
maxItems - 则启用了一个goroutine,当时间达到
refreshInterval时会重置限速器
func NewLimiter(maxItems int, refreshInterval time.Duration) *Limiter {
l := &Limiter{
maxItems: maxItems,
stopCh: make(chan struct{}),
}
l.v.Store(newLimiter(maxItems)) //1
l.wg.Add(1)
go func() {
defer l.wg.Done()
t := time.NewTicker(refreshInterval)
defer t.Stop()
for {
select {
case <-t.C:
l.v.Store(newLimiter(maxItems))//2
case <-l.stopCh:
return
}
}
}()
return l
}
限速器只有一个核心函数Add,当vmstorage接收到一个指标之后,会(通过getLabelsHash计算该指标的唯一标识(h),然后调用下面的Add函数来判断该唯一标识是否存在于缓存中。
如果当前存储的元素个数大于等于允许的最大元素,则通过过滤器判断缓存中是否已经存在该元素;否则将该元素直接加入过滤器中,后续允许将该元素加入到缓存中。
func (l *Limiter) Add(h uint64) bool {
lm := l.v.Load().(*limiter)
return lm.Add(h)
}
func (l *limiter) Add(h uint64) bool {
currentItems := atomic.LoadUint64(&l.currentItems)
if currentItems >= uint64(l.f.maxItems) {
return l.f.Has(h)
}
if l.f.Add(h) {
atomic.AddUint64(&l.currentItems, 1)
}
return true
}
上面的过滤器采用的是布隆过滤器,核心函数为Has和Add,分别用于判断某个元素是否存在于过滤器中,以及将元素添加到布隆过滤器中。
过滤器的初始化函数如下,bitsPerItem是个常量,值为16。bitsCount统计了过滤器中的总bit数,每个bit表示某个值的存在性。bits以64bit为单位的(后续称之为slot,目的是为了在bitsCount中快速检索目标bit)。计算bits时加上63的原因是为了四舍五入向上取值,比如当maxItems=1时至少需要1个unit64的slot。
func newFilter(maxItems int) *filter {
bitsCount := maxItems * bitsPerItem
bits := make([]uint64, (bitsCount+63)/64)
return &filter{
maxItems: maxItems,
bits: bits,
}
}
为什么
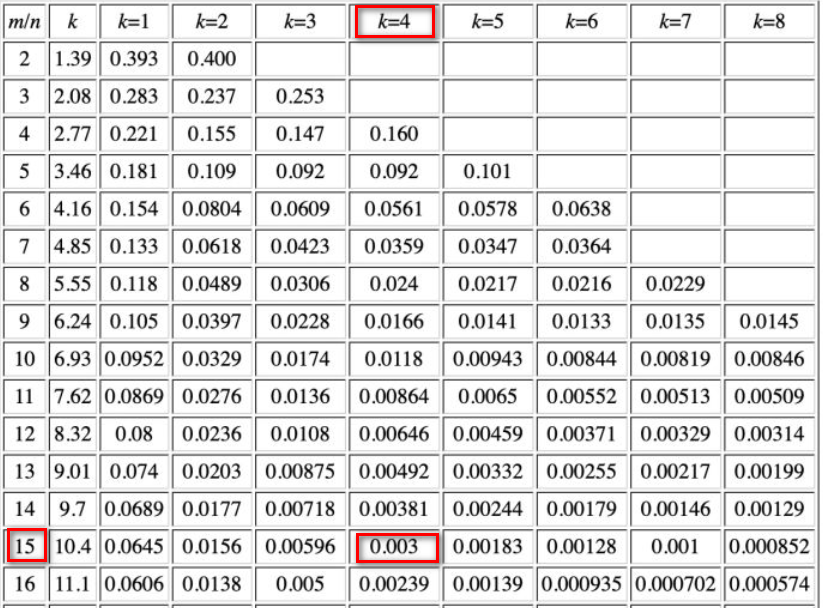
bitsPerItem为16?这篇文章给出了如何计算布隆过滤器的大小。在本代码中,k为4(hashesCount),期望的漏失率为0.003(可以从官方的filter_test.go中看出),则要求总存储和总元素的比例为15,为了方便检索slot(64bit,为16的倍数),将之设置为16。if p > 0.003 {
t.Fatalf("too big false hits share for maxItems=%d: %.5f, falseHits: %d", maxItems, p, falseHits)
}
下面是过滤器的Add操作,目的是在过滤器中添加某个元素。Add函数中没有使用多个哈希函数来计算元素的哈希值,转而改变同一个元素的值,然后对相应的值应用相同的哈希函数,元素改变的次数受hashesCount的限制。
- 获取过滤器的完整存储,并转换为以bit单位
- 将元素
h转换为byte数组,便于xxhash.Sum64计算 - 后续将执行hashesCount次哈希,降低漏失率
- 计算元素h的哈希
- 递增元素
h,为下一次哈希做准备 - 取余法获取元素的bit范围
- 获取元素所在的slot(即uint64大小的bit范围)
- 获取元素所在的slot中的bit位,该位为1表示该元素存在,为0表示该元素不存在
- 获取元素所在bit位的掩码
- 加载元素所在的slot的数值
- 如果
w & mask结果为0,说明该元素不存在, - 将元素所在的slot(
w)中的元素所在的bit位(mask)置为1,表示添加了该元素 - 由于
Add函数可以并发访问,因此bits[i]有可能被其他操作修改,因此需要通过重新加载(14)并通过循环来在bits[i]中设置该元素的存在性
func (f *filter) Add(h uint64) bool {
bits := f.bits
maxBits := uint64(len(bits)) * 64 //1
bp := (*[8]byte)(unsafe.Pointer(&h))//2
b := bp[:]
isNew := false
for i := 0; i < hashesCount; i++ {//3
hi := xxhash.Sum64(b)//4
h++ //5
idx := hi % maxBits //6
i := idx / 64 //7
j := idx % 64 //8
mask := uint64(1) << j //9
w := atomic.LoadUint64(&bits[i])//10
for (w & mask) == 0 {//11
wNew := w | mask //12
if atomic.CompareAndSwapUint64(&bits[i], w, wNew) {//13
isNew = true//14
break
}
w = atomic.LoadUint64(&bits[i])//14
}
}
return isNew
}
看懂了Add函数,Has就相当简单了,它只是Add函数的缩减版,无需设置bits[i]:
func (f *filter) Has(h uint64) bool {
bits := f.bits
maxBits := uint64(len(bits)) * 64
bp := (*[8]byte)(unsafe.Pointer(&h))
b := bp[:]
for i := 0; i < hashesCount; i++ {
hi := xxhash.Sum64(b)
h++
idx := hi % maxBits
i := idx / 64
j := idx % 64
mask := uint64(1) << j
w := atomic.LoadUint64(&bits[i])
if (w & mask) == 0 {
return false
}
}
return true
}
总结
由于victoriaMetrics的过滤器采用的是布隆过滤器,因此它的限速并不精准,在源码条件下, 大约有3%的偏差。但同样地,由于采用了布隆过滤器,降低了所需的内存以及相关计算资源。此外victoriaMetrics的过滤器实现了并发访问。
在大流量场景中,如果需要对请求进行相对精准的过滤,可以考虑使用布隆过滤器,降低所需要的资源,但前提是过滤的结果能够忍受一定程度的漏失率。
victoriaMetrics库之布隆过滤器的更多相关文章
- 【布隆过滤器】基于Hutool库实现的布隆过滤器Demo
布隆过滤器出现的背景: 如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定.链表.树.散列表(又叫哈希表,Hash table)等等数据结构都是这种思路,存储 ...
- 布隆过滤器的概述及Python实现
布隆过滤器 布隆过滤器是一种概率空间高效的数据结构.它与hashmap非常相似,用于检索一个元素是否在一个集合中.它在检索元素是否存在时,能很好地取舍空间使用率与误报比例.正是由于这个特性,它被称作概 ...
- Redis05——Redis高级运用(管道连接,发布订阅,布隆过滤器)
Redis高级运用 一.管道连接redis(一次发送多个命令,节省往返时间) 1.安装nc yum install nc -y 2.通过nc连接redis nc localhost 6379 3.通过 ...
- Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器
Redis: 缓存过期.缓存雪崩.缓存穿透.缓存击穿(热点).缓存并发(热点).多级缓存.布隆过滤器 2019年08月18日 16:34:24 hanchao5272 阅读数 1026更多 分类专栏: ...
- Redis详解(十三)------ Redis布隆过滤器
本篇博客我们主要介绍如何用Redis实现布隆过滤器,但是在介绍布隆过滤器之前,我们首先介绍一下,为啥要使用布隆过滤器. 1.布隆过滤器使用场景 比如有如下几个需求: ①.原本有10亿个号码,现在又来了 ...
- Scrapy分布式爬虫,分布式队列和布隆过滤器,一分钟搞定?
使用Scrapy开发一个分布式爬虫?你知道最快的方法是什么吗?一分钟真的能 开发好或者修改出 一个分布式爬虫吗? 话不多说,先让我们看看怎么实践,再详细聊聊细节~ 快速上手 Step 0: 首先安装 ...
- Redis解读(4):Redis中HyperLongLog、布隆过滤器、限流、Geo、及Scan等进阶应用
Redis中的HyperLogLog 一般我们评估一个网站的访问量,有几个主要的参数: pv,Page View,网页的浏览量 uv,User View,访问的用户 一般来说,pv 或者 uv 的统计 ...
- 从位图到布隆过滤器,C#实现
前言 本文将以 C# 语言来实现一个简单的布隆过滤器,为简化说明,设计得很简单,仅供学习使用. 感谢@时总百忙之中的指导. 布隆过滤器简介 布隆过滤器(Bloom filter)是一种特殊的 Hash ...
- Redis布隆过滤器和布谷鸟过滤器
一.过滤器使用场景:比如有如下几个需求:1.原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中? 解决办法一:将10亿个号码存入数据库中,进行数据库查询,准 ...
随机推荐
- 写给开发人员的实用密码学(七)—— 非对称密钥加密算法 RSA/ECC
本文部分内容翻译自 Practical-Cryptography-for-Developers-Book,笔者补充了密码学历史以及 openssl 命令示例,并重写了 RSA/ECC 算法原理.代码示 ...
- sqlserver 中,如何将getdate()时间的时分秒固定为00:00:00或者忽略不要
在使用getdate()时,时间会实时刷新,那么我们就要再查询的时候就需要精确到毫秒后三位,非常难受,那么为了解决这个问题我们可以通过以下几种方法进行固定或者去掉毫秒 1.将毫秒固定为00:00:00 ...
- DDOS防御实验----反射器的安全配置
0x01 环境 共包含三台主机 一台centos7.3 为attact主机,装有python +Scapy 一台centos7.3,server,装有bind9 ntp memcached,作为DDO ...
- MySQL&SQL server&Oracle&Access&PostgreSQL数据库sql注入详解
判断数据库的类型 当我们通过一些测试,发现存在SQL注入之后,首先要做的就是判断数据库的类型. 常用的数据库有MySQL.Access.SQLServer.Oracle.PostgreSQL.虽然绝大 ...
- react单向数据流怎么理解?
React是单向数据流,数据主要从父节点传递到子节点(通过props).如果顶层(父级)的某个props改变了,React会重渲染所有的子节点.
- Integer与int的区别?
int是java提供的8种原始数据类型之一.Java为每个原始类型提供了封装类,Integer是java为int提供的封装类.int的默认值为0,而Integer的默认值为null,即Integer可 ...
- 四种类型的数据节点 Znode?
1.PERSISTENT-持久节点 除非手动删除,否则节点一直存在于 Zookeeper 上 2.EPHEMERAL-临时节点 临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与 zoo ...
- prometheus-存储
采集到的样本以时间序列的方式保存在内存(TSDB 时序数据库)中,并定时保存到硬盘中 prometheus一般会保留15天 prometheus按照block块的方式来存储数据,每2小时为一个时间单位 ...
- 什么是基于 Java 的 Spring 注解配置? 给一些注解的例子?
基于 Java 的配置,允许你在少量的 Java 注解的帮助下,进行你的大部分 Spring 配置而非通过 XML 文件. 以@Configuration 注解为例,它用来标记类可以当做一个 bean ...
- spi详解
来源:https://www.sohu.com/a/211324861_468626 1. SPI简介 SPI,是英语Serial Peripheral interface的缩写,顾名思义就是串行外围 ...