flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink
什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。

1. 环境准备
mysql
Hive
flink 1.13.5 on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
2. 下载下列依赖包
下面两个地址下载flink的依赖包,放在lib目录下面。
如果你的Flink是其它版本,可以来这里下载。
说明:我hive版本是2.1.1,为啥这里我选择版本号是2.2.0呢,这是官方文档给出的版本对应关系:
| Metastore version | Maven dependency | SQL Client JAR |
|---|---|---|
| 1.0.0 - 1.2.2 | flink-sql-connector-hive-1.2.2 |
Download |
| 2.0.0 - 2.2.0 | flink-sql-connector-hive-2.2.0 |
Download |
| 2.3.0 - 2.3.6 | flink-sql-connector-hive-2.3.6 |
Download |
| 3.0.0 - 3.1.2 | flink-sql-connector-hive-3.1.2 |
Download |
官方文档地址在这里,可以自行查看。
3. 启动flink-sql client
- 先在yarn上面启动一个application,进入flink13.5目录,执行:
bin/yarn-session.sh -d -s 2 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-hive
- 进入flink sql命令行
bin/sql-client.sh embedded -s flink-cdc-hive

4. 操作Hive
1) 首选创建一个catalog
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
这里需要注意:hive-conf-dir是你的hive配置文件地址,里面需要有hive-site.xml这个主要的配置文件,你可以从hive节点复制那几个配置文件到本台机器上面。
2) 查询
此时我们应该做一些常规DDL操作,验证配置是否有问题:
use catalog hive_catalog;
show databases;
随便查询一张表
use test
show tables;
select * from people;
可能会报错:

把hadoop-mapreduce-client-core-3.0.0.jar放到flink的Lib目录下,这是我的,实际要根据你的hadoop版本对应选择。
注意:很关键,把这个jar包放到Lib下面后,需要重启application,然后重新用yarn-session启动一个application,因为我发现好像有缓存,把这个application kill 掉,重启才行:
然后,数据可以查询了,查询结果:
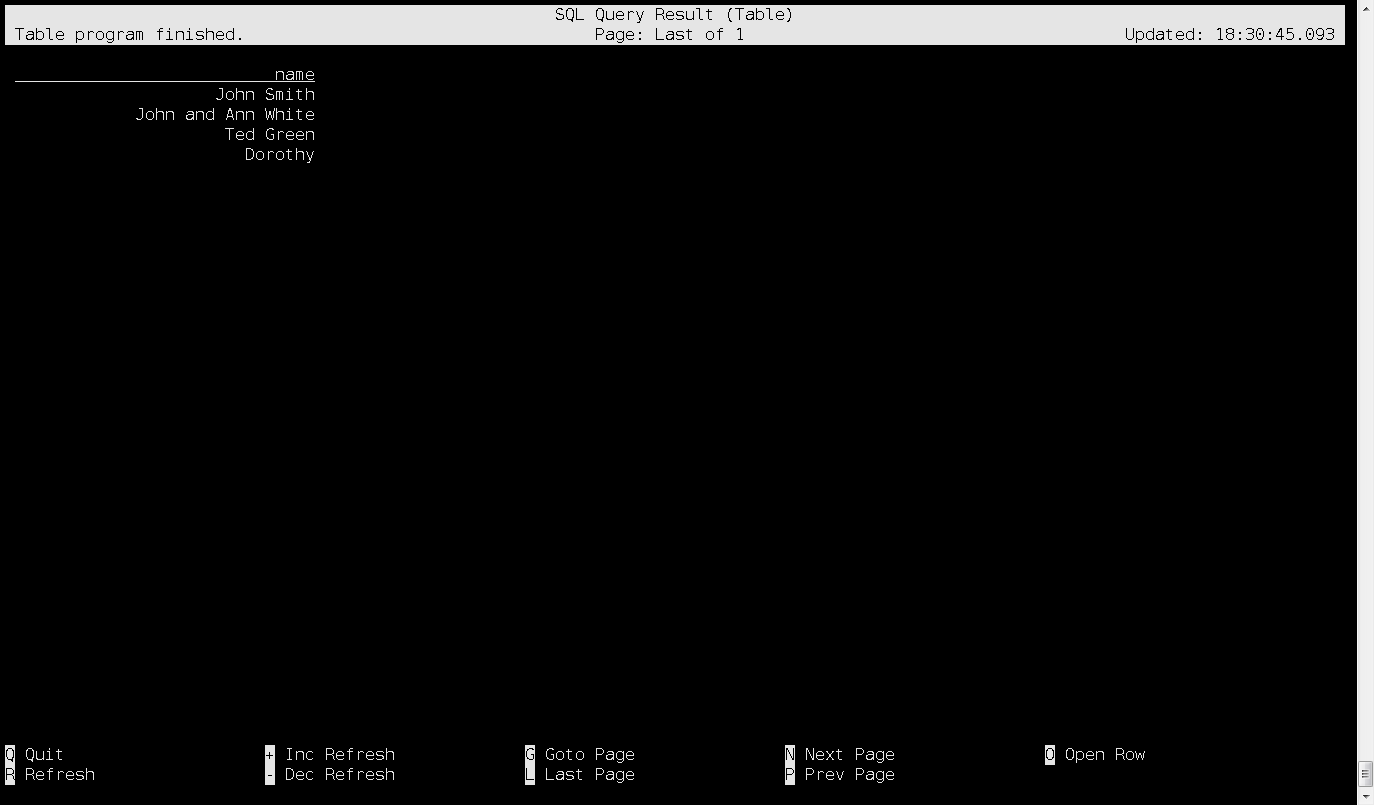
5. mysql数据同步到hive
mysql数据无法直接在flink sql导入hive,需要分成两步:
- mysql数据同步kafka;
- kafka数据同步hive;
至于mysql数据增量同步到kafka,前面有文章分析,这里不在概述;重点介绍kafka数据同步到hive。
1) 建表跟kafka关联绑定:
前面mysql同步到kafka,在flink sql里面建表,connector='upsert-kafka',这里有区别:
CREATE TABLE product_view_mysql_kafka_parser(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) WITH (
'connector' = 'kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = 'kafka-001:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
2) 建一张hive表
创建hive需要指定SET table.sql-dialect=hive;,否则flink sql 命令行无法识别这个建表语法。为什么需要这样,可以看看这个文档Hive 方言。
-- 创建一个catalag用户hive操作
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
use catalog hive_catalog;
-- 可以看到我们的hive里面有哪些数据库
show databases;
use test;
show tables;
上面我们可以现在看看hive里面有哪些数据库,有哪些表;接下来创建一张hive表:
CREATE TABLE product_view_kafka_hive_cdc (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) STORED AS parquet TBLPROPERTIES (
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0S',
'sink.partition-commit.policy.kind'='metastore,success-file',
'auto-compaction'='true',
'compaction.file-size'='128MB'
);
然后做数据同步:
insert into hive_catalog.test.product_view_kafka_hive_cdc
select *
from
default_catalog.default_database.product_view_mysql_kafka_parser;
注意:这里指定表名,我用的是catalog.database.table,这种格式,因为这是两个不同的库,需要明确指定catalog - database - table。
网上还有其它方案,关于mysql实时增量同步到hive:

网上看到一篇写的实时数仓架构方案,觉得还可以:
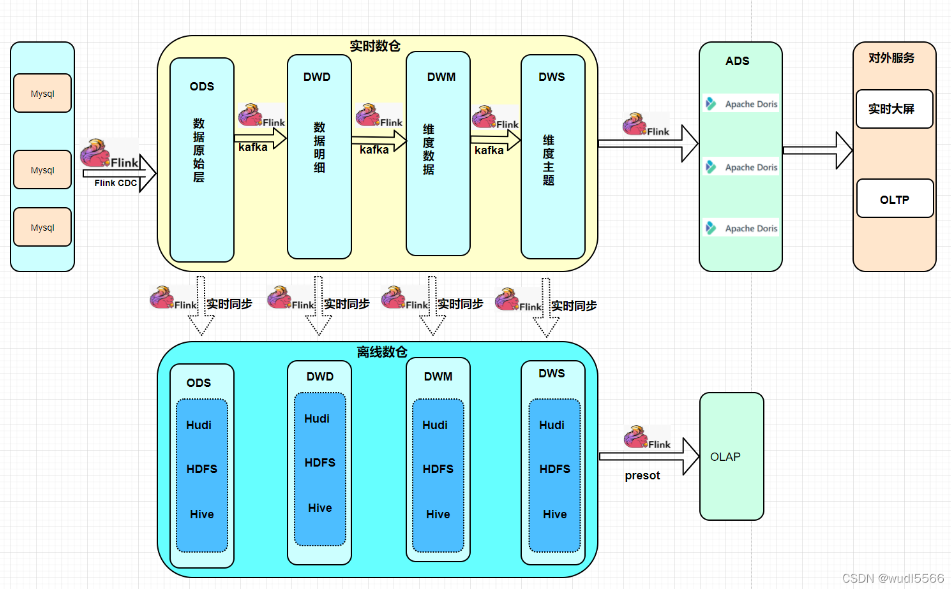
参考资料
flink-cdc同步mysql数据到hive的更多相关文章
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- 使用sqoop把mysql数据导入hive
使用sqoop把mysql数据导入hive export HADOOP_COMMON_HOME=/hadoop export HADOOP_MAPRED_HOME=/hadoop cp /hive ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- wind本地MySQL数据到hive的指定路径
一:使用:kettle:wind本地MySQL数据到hive的指定路径二:问题:没有root写权限网上说的什么少jar包,我这里不存在这种情况,因为我自己是导入jar包的:mysql-connecto ...
- wind本地MySQL数据到hive的指定路径,Could not create file
一:使用:kettle:wind本地MySQL数据到hive的指定路径二:问题:没有root写权限网上说的什么少jar包,我这里不存在这种情况,因为我自己是导入jar包的:mysql-connecto ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- 快速同步mysql数据到redis中
MYSQL快速同步数据到Redis 举例场景:存储游戏玩家的任务数据,游戏服务器启动时将mysql中玩家的数据同步到redis中. 从MySQL中将数据导入到Redis的Hash结构中.当然,最直接的 ...
随机推荐
- windows平台编译CEF支持H264(MP3、MP4)超详细
编译目标(如何确定目标定版本请查看:BranchesAndBuilding) CEF Branch:4664 CEF Commit:fe551e4 Chromium Version:96.0.4664 ...
- Rabbimtq消息传递对象
对象序列化即可.
- 字节跳动数据平台技术揭秘:基于 ClickHouse 的复杂查询实现与优化
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 ClickHouse 作为目前业内主流的列式存储数据库(DBMS)之一,拥有着同类型 DBMS 难以企及 ...
- 10.5 详解Android Studio项目结构
Android项目的结构很复杂,并不像HTML项目,最简单的直接一个HTML文件就行了,相信学完上一节的同学就明白,哪怕是一个HelloWorld这样一个项目的文件可能都有几十个,所以我们需要搞清楚, ...
- NC15975 小C的记事本
NC15975 小C的记事本 题目 题目描述 小C最近学会了java小程序的开发,他很开心,于是想做一个简单的记事本程序练练手. 他希望他的记事本包含以下功能: 1.append(str),向记事本插 ...
- final关键字概念与四种用法和final关键字用于修饰类和成员方法
fifinal关键字 概述 学习了继承后,我们知道,子类可以在父类的基础上改写父类内容,比如,方法重写.那么我们能不能随意的继承 API中提供的类,改写其内容呢?显然这是不合适的.为了避免这种随意改写 ...
- react配置postcss-pxtorem适配
适配移动端操作如下: 安装 postcss-pxtorem .amfe-flexible npm i postcss-pxtorem npm i amfe-flexible amfe-flexible ...
- MySQL语句与正则表达式
正则表达式的作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较.MySQL用WHERE子句对正则表达式提供了初步的支持,允许你指定正则表达式,过滤SELECT检索出的数据. 1.元字符说明 ...
- 160_技巧_Power BI 新函数-计算工作日天数
160_技巧_Power BI 新函数-计算工作日天数 一.背景 Power BI 2022 年 7 月 14 日更新了最新版本的,版本号为:2.107.683.0 . 更多更新内容可以查看官方博客: ...
- 004 SpringSecurity验证规则
SpringSecurity验证规则 SpringSecurity框架登录后,==在userDetails对象中,一定会有一个权限列表 == 登录用户对象的值可能是: {"authoriti ...