青源Talk第8期|苗旺:因果推断,观察性研究和2021年诺贝尔经济学奖
biobank 英国的基金数据
因果推断和不同的研究互相论证,而非一个研究得到的接了就行。
数据融合,data fusion,同一个因果问题不同数据不同结论,以及历史上的数据,来共同得到更稳健、更高效的推断。敏感性分析(评价假定的方法)。多方验证。统计中的meta analysis荟萃分析。讨论这个做法背后的模型、假定是如何解释这个结果。
敏感性分析(评价假定的方法)。
1.实现你的方法,论证你的方法;
2.论证你的模型、假定,以及解释你的结果。三者缺一不可。单单的方法是不行的。
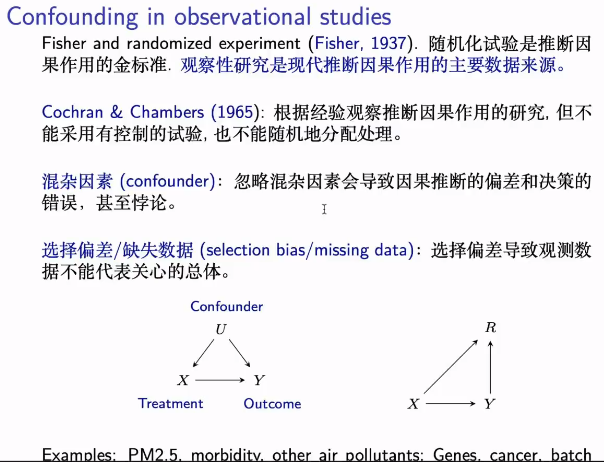
大规模数据处理面对比较高维的数据时,skrining 作为标准预处理的一个步骤。与其配套的是敏感性分析,敏感性分析就是看你的假定,如果说错了,错到什么程度会影响结论,会得到不一样的结论;二者是配套的,也即你有一个抢的假定,同时也要有一个,评价假定的方法--敏感性分析。
相关的主要目的是为了做预测,只要预测好就行。因果关系母的不一样,因果关系要特别在意解释型;要直到到底哪些因素导致了明天的股票上涨。相关的主要目的是为了做预测,只要预测好就行。因果关系母的不一样,因果关系要特别在意解释型;要直到到底哪些因素导致了明天的股票上涨。
时空数据相关的发展到了什么程度?最近的一些进展?也即时序数据上有一套不太一样的因果推断方法,如果把这样的方法放到时空数据里面,是否也有一套比较特定的好方法来解决它?时空数据、相关性数据的因果推断。
confounding,selective bias为第一梯队要研究的,inference,midiation,ide,以及异质化为第二梯队要研究的。真正的拿因果关系的因素去预测,不一定比用相关关系的预测效果更好。
二者的目标不太一致;ML:主要关注的是预测、分类等类似的问题;而因果推断天生的就是关注模型的解释性,参数的识别性,定义,因果参数,因果的意义是什么;二者目标不太一致。对于预测来讲,你拿真正的因果关系去预测,不一定比拿相关关系去预测更好。反之,相关关系不能代表因果关系。当然现在大家正在把可解释性和可预测性,预测能力结合在一起;这可能是因果推断和深度学习能够深入融合的地方,而不仅仅是换汤不换药的模式。如何把预测、可解释性、参数的推断把目标给融合到一起,可能是一个方向。需要找到一条线,使得预测的目标和因果推理的目标能够对齐。之前做预测可能相对来讲大家再用一个比较简单的数据集(e.g. i.i.d,随机分割等这样的交叉验证的数据集来做,),正是由于此导致今天很多的方法,在不符合这个假定条件下的真实的场景下边就会出现各种问题 。因果推理和ML里面都有很多的假定。假如把这个假定换一下,换的更实用些、更realistic,可能就需要用一些更本质的统计的逻辑或结构可能才能够做到这种事情;这种情况下可能更需要去借鉴一些更严格的统计的手段和方法来解决这样的问题。让ML或预测更加的stable。
除了读书教书方面,学术研究有几个方面让其收益很大;1.写作交流表达能力一定要重视起来,记录单词,积累句子等。2.拓宽自己的视野;不一定只是盯着前沿的东西,一定要对自己所在的领域有一个全局的认识。3.扩展一些兴趣,应用方面的以及交叉领域相关领域的一些事情,来拓宽自己的视野;不同的问题、方法交汇融合。4.加强阅读,多读多写。











青源Talk第8期|苗旺:因果推断,观察性研究和2021年诺贝尔经济学奖的更多相关文章
- 【因果推断经典论文】Direct and Indirect Effects - Judea Pearl
Direct and Indirect Effects Author: Judea Pearl UAI 2001 加州大学洛杉矶分校 论文链接:https://dl.acm.org/doi/pdf/1 ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- 一位IT牛人的十年经验之谈
1.分享第一条经验:“学历代表过去.能力代表现在.学习力代表未来.” 其实这是一个来自国外教育领域的一个研究结果.相信工作过几年.十几年的朋友对这个道理有些体会吧.但我相信这一点也很重要:“重要的道理 ...
- 2017TSC世界大脑与科技峰会,多角度深入探讨关于大脑意识
TSC·世界大脑与科技峰会是全世界范围内的集会,多角度深入探讨关于大脑意识体验来源这一根本话题,我们是谁,现实的本质是什么,我们所处宇宙空间的本质为何.该峰会由亚利桑那大学意识研究中心主办. 会议时间 ...
- 一位IT男的7年工作经验总结
一位IT男的7年工作经验总结 1.分享第一条经验:"学历代表过去.能力代表现在.学习力代表未来." 其实这是一个来自国外教育领域的一个研究结果.相信工作过几年.十几年的朋友对这个道 ...
- 习题集1b: 额外练习 (可选)
1.练习:4.样本特点 用来描述样本的数字叫做? □ 参数 (√)□ 统计量 □ 变量 □ 常数 2.练习:5.大一学生体重情况 Freidman 博士在一所大学任教,她记录了所在大学每位大一新生 ...
- 习题集1a:研究方法入门
1.课程实践编号 课程实践编号 随着对习题集“PS 1a:研究方法入门”和其他习题集的了解,你可能会发现进度栏中的习题编号并非一直是连续的. 对于存在两个习题集的课程,如果一个习题集看上去“缺失”习题 ...
- Framingham风险评估
Framingham风险评分: Framingham 心脏研究和其他流行病学队列研究改变了20世纪后半部分对疾病的关注点,即从治疗已经存在的心血管疾病到预防处于疾病危险的状态.该策略的关键因素是识别那 ...
- AI Gossip
本文作者:七牛云人工智能实验室-林亦宁原文地址:https://zhuanlan.zhihu.com/p/26168331 什么是智能 回到几万年前的东非大草原,谁能意识到,那个到处被欺负的,被表哥从 ...
随机推荐
- Linux yum搭建私有仓库
搭建yum仓库需要两种资源: rpm包 rpm包的元数据(repodata) 搭建好仓库后需要使用三种网络协议共享出来 http或https ftp 范例: 使用http协议搭建私有仓库 (本示例使用 ...
- Node.js精进(6)——文件
文件系统是一种用于向用户提供底层数据访问的机制,同时也是一套实现了数据的存储.分级组织.访问和获取等操作的抽象数据类型. Node.js 中的fs模块就是对文件系统的封装,整合了一套标准 POSIX ...
- Win10默认以管理员身份运行cmd命令提示符
如图所示操作
- NC17059 队列Q
NC17059 队列Q 题目 题目描述 ZZT 创造了一个队列 Q.这个队列包含了 N 个元素,队列中的第 i 个元素用 \(Q_i\) 表示.Q1 表示队头元素,\(Q_N\) 表示队尾元素.队列中 ...
- Python 用configparser读写ini文件
一.configparser 简介Python用于读写ini文件的一个官方标准库.具体详见官网链接 二.configparser 部分方法介绍 方法 描述 read(filenames) filesn ...
- dynamic + shardingsphere(4.1.1) 实现动态分库分表
1. 主要依赖: <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-da ...
- day03_2_流程控制
# 流程控制 学习目标: ~~~txt1. idea安装与使用2. 流程控制if...else结构3. 流程控制switch结构4. 流程控制循环结构5. 流程控制关键字~~~ # 一.流程控制概述 ...
- Go语言基础五:引用类型-切片和映射
切片 Go的数组长度不可以改变,在某些特定的场景中就不太适用了.对于这种情况Go语言提供了一种由数组建立的.更加灵活方便且功能强大的包装(Wapper),也就是切片.与数组相比切片的长度不是固定的,可 ...
- js屏蔽浏览器默认事件
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- Apache DolphinScheduler新一代分布式工作流任务调度平台实战-中
@ 目录 架构设计 总体架构 启动流程图 架构设计思想简述 负载均衡 缓存 实战使用 参数 参数优先级 内置参数 基础内置参数 衍生内置参数 本地参数和全局参数 工作流传参 数据源管理 支持数据源 创 ...