golang 必会之 pprof 监控系列(5) —— cpu 占用率 统计原理
golang pprof 监控系列(5) —— cpu 占用率 统计原理
大家好,我是蓝胖子。
经过前面的几节对pprof的介绍,对pprof统计的原理算是掌握了七八十了,我们对memory,block,mutex,trace,goroutine,threadcreate这些维度的统计原理都进行了分析,但唯独还没有分析pprof 工具是如何统计cpu使用情况的,今天我们来分析下这部分。
http 接口暴露的方式
还记得 golang pprof监控系列(2) —— memory,block,mutex 使用 里我们启动了一个http服务来暴露各种性能指标信息。让我们再回到当时启动http服务看到的网页图。

当点击上图中profile链接时,便会下载一个关于cpu指标信息的二进制文件。这个二进制文件同样可以用go tool pprof 工具去分析,同样,关于go tool pprof的使用不是本文的重点,网上的资料也相当多,所以我略去了这部分。
紧接着,我们来快速看下如何用程序代码的方式生成cpu的profile文件。
程序代码生成profile
os.Remove("cpu.out")
f, _ := os.Create("cpu.out")
defer f.Close()
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
// .... do other things
代码比较简单,pprof.StartCPUProfile 则开始统计 cpu使用情况,pprof.StopCPUProfile则停止统计cpu使用情况,将程序使用cpu的情况写入cpu.out文件。cpu.out文件我们则可以用go tool pprof去分析了。
好的,在快速的看完如何在程序中暴露cpu性能指标后,我们来看看golang是如何统计各个函数cpu使用情况的。接下来,正戏开始。
cpu 统计原理分析
首先要明白,我们究竟要统计的是什么内容?我们需要知道cpu的使用情况,换言之就是cpu的工作时间花在了哪些函数上,最后是不是就是看函数在cpu上的工作时长。
那么函数的在cpu上工作时长应该如何去进行统计?
golang还是采用部分采样的方式,通过settimmer 系统调用设置了 发送SIGPROF 的定时器,当达到runtime.SetCPUProfileRate设置的周期间隔时,操作系统就会向进程发送SIGPROF 信号,默认情况下是100Mz(10毫秒)。
一旦设置了 发送SIGPROF信号的定时器,操作系统便会定期向进程发送SIGPROF信号。
设置定时器的代码便是在我们调用pprof.StartCPUProfile方法开启cpu信息采样的时候。代码如下,
// src/runtime/pprof/pprof.go:760
func StartCPUProfile(w io.Writer) error {
const hz = 100
cpu.Lock()
defer cpu.Unlock()
if cpu.done == nil {
cpu.done = make(chan bool)
}
// Double-check.
if cpu.profiling {
return fmt.Errorf("cpu profiling already in use")
}
cpu.profiling = true
runtime.SetCPUProfileRate(hz)
go profileWriter(w)
return nil
}
在倒数第三行的时候调用了设置采样的周期,并且紧接着profileWriter 就是用一个协程启动后去不断的读取cpu的采样数据写到文件里。而调用settimer的地方就是在runtime.SetCPUProfileRate里,runtime.SetCPUProfileRate最终会调用 setcpuprofilerate方法 ,setcpuprofilerate 又会去调用setProcessCPUProfiler方法设置settimer 定时器。
// src/runtime/signal_unix.go:269
func setProcessCPUProfiler(hz int32) {
.....
var it itimerval
it.it_interval.tv_sec = 0
it.it_interval.set_usec(1000000 / hz)
it.it_value = it.it_interval
setitimer(_ITIMER_PROF, &it, nil)
....
经过上述步骤后,cpu的采样就真正开始了,之后就是定时器被触发送SIGPROF信号,进程接收到这个信号后,会对当前函数的调用堆栈进行记录,由于默认的采样周期设置的是100Mz,所以,你可以理解为每10ms,golang就会统计下当前正在运行的是哪个函数,在采样的这段时间内,哪个函数被统计的次数越多,是不是就能说明这个函数在这段时间内占用cpu的工作时长就越多了。
由于golang借助了linux的信号机制去进行cpu执行函数的采样,这里有必要额外介绍下linux 进程与信号相关的知识。首先来看下线程处理信号的时机在什么时候。
线程处理信号的时机
线程对信号的处理时机一般 是在由内核态返回到用户态之前,也就是说,当线程由于系统调用或者中断进入内核态后, 当系统调用结束或者中断处理完成后,在返回到用户态之前,操作系统会检查这个线程是不是有未处理的信号,如果有的话,那么会先切回到用户态让 线程会首先处理信号,信号处理完毕后 又返回内核态,内核此时才会将调用栈设置为中断或者系统调用时 用户进程中断的地方 ,然后切换到用户态后就继续在用户进程之前中断的地方继续执行程序逻辑了。由于进程几乎每时每刻都在进行诸如系统调用的工作,可以认为,信号的处理是几乎实时的。 如下是线程内核态与用户态切换的过程,正式信号处理检查的地方。整个过程可以用下面的示意图表示。
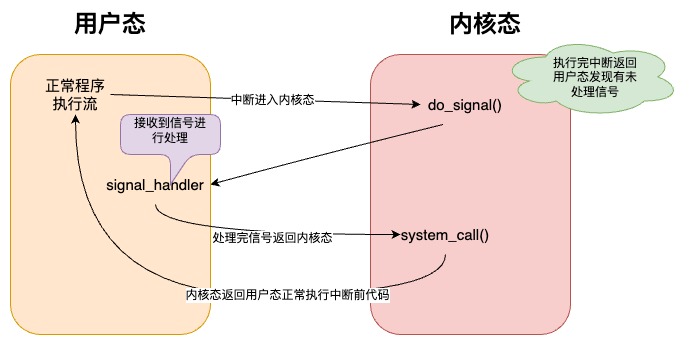
知道了信号是如何被线程处理的,还需要了解下,内核会如何发送信号给进程。
内核发送信号的方式
内核向进程发信号的方式是对进程中的一个线程发送信号,而通过settimmer 系统调用设置定时器 发送SIGPROF 信号的方式就是随机的对进程中的一个运行中线程去进行发送。而运行中线程接收到这个信号后,就调用自身的处理函数对这个信号去进行处理,对于SIGPROF 信号而言,则是将线程中断前的函数栈记录下来,用于后续分析函数占用cpu的工作时长。
由于只是随机的向一个运行中的线程发送SIGPROF 信号,这里涉及到了两个问题?
第一因为同一个进程中只有一个线程在进行采样,所以在随机选择运行线程发送SIGPROF信号时,要求选择线程时的公平性,不然可能会出现A,B两个线程,A线程接收到SIGPROF信号的次数远远大于B 线程接收SIGPROF信号的次数,这样对A线程进行采样的次数将会变多,影响了我们采样的结果。
而golang用settimmer 设置定时器发送SIGPROF 信号 的方式的确被证实在linux上存在线程选择公平性问题(但是mac os上没有这个问题) 关于这个问题的讨论在github上有记录,这是链接 这个问题已经在go1.18上得到了解决,解决方式我会在下面给出,我们先来看随机的向一个运行中的线程发送SIGPROF 信号 引发的第二个问题。
第二 因为是向一个运行中的线程去发送信号,所以我们只能统计到采样时间段内在cpu上运行的函数,而那些io阻塞的函数将不能被统计到,关于这点业内已经有开源库帮助解决,https://github.com/felixge/fgprof,不过由于这个库进行采样时会stop the world ,所以其作者强烈建议如果go协程数量比较多时,将go版本升级到1.19再使用。后续有机会再来探讨这个库的实现吧,我们先回到如何解决settimer函数在选择线程的公平性问题上。
采样数据的公平性
为了解决公平性问题,golang在settimer的系统调用的基础上增加了timer_create系统调用timer_create 可以单独的为每一个线程都创建定时器,这样每个运行线程都会采样到自己的函数堆栈了。所以在go1.18版本对pprof.StartCPUProfile内部创建定时器的代码进行了改造。刚才有提到pprof.StartCPUProfile 底层其实是调用setcpuprofilerate 这个方法去设置的定时器,所以我们来看看go1.18和go1.17版本在这个方法的实现上主要是哪里不同。
// go1.17 版本 src/runtime/proc.go:4563
func setcpuprofilerate(hz int32) {
if hz < 0 {
hz = 0
}
_g_ := getg()
_g_.m.locks++
setThreadCPUProfiler(0)
for !atomic.Cas(&prof.signalLock, 0, 1) {
osyield()
}
if prof.hz != hz {
// 设置进程维度的 SIGPROF 信号发送器
setProcessCPUProfiler(hz)
prof.hz = hz
}
atomic.Store(&prof.signalLock, 0)
lock(&sched.lock)
sched.profilehz = hz
unlock(&sched.lock)
if hz != 0 {
// 设置线程维度的SIGPROF 信号定时器
setThreadCPUProfiler(hz)
}
_g_.m.locks--
}
上述是go1.17版本的setcpuprofilerate 代码,如果你再去看 go1.18版本的代码,会发现他们在这个方法上是一模一样的,都是调用了setProcessCPUProfiler 和setThreadCPUProfiler,setProcessCPUProfiler 设置进程维度的发送SIGPROF信号定时器,setThreadCPUProfiler设置线程维度的发送SIGPROF信号的定时器,但其实setThreadCPUProfiler 在go1.17的实现上并不完整。
// go 1.17 src/runtime/signal_unix.go:314
func setThreadCPUProfiler(hz int32) {
getg().m.profilehz = hz
}
go1.17版本上仅仅是为协程里代表线程的m变量设置了一个profilehz(采样的频率),并没有真正实现线程维度的采样。
// go 1.18 src/runtime/os_linux.go:605
....
// setThreadCPUProfiler 方法内部 timer_create的代码段
var timerid int32
var sevp sigevent
sevp.notify = _SIGEV_THREAD_ID
sevp.signo = _SIGPROF
sevp.sigev_notify_thread_id = int32(mp.procid)
ret := timer_create(_CLOCK_THREAD_CPUTIME_ID, &sevp, &timerid)
if ret != 0 {
return
}
....
在go1.18版本上的setThreadCPUProfiler则真正实现了这部分逻辑,由于go1.18版本它同时调用了setProcessCPUProfiler以及setThreadCPUProfiler,这样在接收SIGPROF信号时就会出现重复计数的问题。
所以go1.18在处理SIGPROF信号的时候也做了去重处理,所以在golang信号处理的方法sighandler 内部有这样一段逻辑。
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
_g_ := getg()
c := &sigctxt{info, ctxt}
if sig == _SIGPROF {
mp := _g_.m
// Some platforms (Linux) have per-thread timers, which we use in
// combination with the process-wide timer. Avoid double-counting.
if validSIGPROF(mp, c) {
sigprof(c.sigpc(), c.sigsp(), c.siglr(), gp, mp)
}
return
}
.....
如果发现信号是_SIGPROF 那么会通过validSIGPROF 去检测此次的_SIGPROF信号是否应该被统计。validSIGPROF的检测逻辑这里就不展开了。
总结
cpu的统计原理与前面所讲的指标统计的原理稍微复杂点,涉及到了linux信号处理相关的内容,cpu统计的原理,简而言之,就是通过设置一个发送SIGPROF信号的定时器,然后用户程序通过接收操作系统定时发送的SIGPROF信号来对用户程序正在执行的堆栈函数进行统计。在采样时间内,同一个函数被统计的越多,说明该函数占用的cpu工作时长就越长。
golang 必会之 pprof 监控系列(5) —— cpu 占用率 统计原理的更多相关文章
- Shell编程检测监控mysql的CPU占用率
shell编程很强大! 网站访问量大的时候mysql的压力就比较大,当mysql的CPU利用率超过300%的时候就不能提供服务了,近乎卡死状态,这时候最好的方法就是重启mysql服务.由于这种事具有不 ...
- shell脚本检测监控mysql的CPU占用率
网站访问量大的时候mysql的压力就比较大,当mysql的CPU利用率超过300%的时候就不能提供服务了,近乎卡死状态,这时候最好的方法 就是重启mysql服务.由于这种事具有不可预见性,我们不知道什 ...
- asp.net mvc5+Echarts3.0+AspNet.SignalR2.0 实时监控cpu占用率推送
先看看效果: 感谢QQ群18668853的群主,无私的公开课,全是干货,当初学的时候,群主用的是jquery.flot做图表,我这里改成百度的Echarts3.0,这算是自己的修改吧,喜欢的可以去下载 ...
- zabbix监控进程的CPU和内存占用量,进程数量
由于需要对公司特定服务进行监控,于是,通过编写脚本获取各个进程占用系统资源的信息,从而使用zabbix采集到这些数据进行特定进程的基础监控. 我这主要需要监控的程序如下: nginx redis my ...
- linux监控平台搭建-cpu
linux监控平台搭建-cpu 目前服务器的主流CPU是intel或者AMD.到底主频是什么.多核.多线程.并发.并行.超频.一级缓存.二级缓存.三级缓存.i386.x86 cpu:含有算术逻辑.控制 ...
- Linux常用命令及详细说明 — 结合工作(侧重性能监控,包括CPU、内存、IO、网络、磁盘等)
(一)Linux监控的几个常用命令(对于服务器后端程序猿很重要,必须掌握): 命令 功能 命令 功能 iostat 统计CPU及网络.设备和分区IO的数据 vmstat 展示给定时间服务器的状态值(包 ...
- 【转】apache kafka监控系列-KafkaOffsetMonitor
apache kafka监控系列-KafkaOffsetMonitor 时间 2014-05-27 18:15:01 CSDN博客 原文 http://blog.csdn.net/lizhitao ...
- apache kafka监控系列-KafkaOffsetMonitor(转)
原文链接:apache kafka监控系列-KafkaOffsetMonitor 概览 最 近kafka server消息服务上线了,基于jmx指标参数也写到zabbix中了,但总觉得缺少点什么东西, ...
- C# 视频监控系列:学习地址汇总
原文地址:http://www.cnblogs.com/over140/archive/2009/04/07/1429308.html 前言 对于视频监控系统大家应该是不陌生的,实施的路况信息.地铁. ...
- 【转】C# 视频监控系列(13):H264播放器——控制播放和截图
本文原文地址:http://www.cnblogs.com/over140/archive/2009/03/30/1421531.html 阿里云栖社区也有相关的视频开发案例:https://yq.a ...
随机推荐
- docker 配置 anaconda + jupyter notebook 纪要
首先,pull官方的镜像,名字叫:continuumio/anaconda3 首先的首先,如果默认还是需要sudo运行docker命令,可以考虑把当前用户加入到docker组(usermod -aG ...
- 库已安装但找不到ttkbootstrap库
cmd里装,弹提示Requirement already satisfied pip install --target=F:\Python37\lib ttkbootstrap https://blo ...
- 学生管理系统CLI版
学生管理系统CLI版 学生类 package com.itheima_03; public class Student { String sid; String name; String age; S ...
- 1js 高级
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- MSSQL SQL SERVER 2008 使用RowNumber()分页查询并获取总行数 附达梦数据库
参数:pages:要查询的页码(要查询第几页):pageNum:要查询的行数(每页要查多少行):适用于使用多表查询,不以固定的实体类保存结果,如使用 List<Map<String, Ob ...
- 中国移动光猫(吉比特h2-3S)超级用户名与密码
超级用户名 CMCCAdmin 密码 aDm8H%MdA
- 转发 关于Windows安装解压版MySQL出现服务正在启动-服务无法启动的问题
部分转自 :https://blog.csdn.net/u013901768/article/details/80707307 我是从服务器上复制了mysql的整个目录,到本地,然后怎么也不好用,看了 ...
- LeedCode 85. 最大矩形(/)
原题解 题目 约束 题解 解法一 class Solution { public: int maximalRectangle(vector<vector<char>>& ...
- tensorflow出现Failed to get convolution algorithm, cuDNN failed to initialize
网上大多的教程是说tensorflow的版本过高,或者说cuda和cudnn的版本不对,需要降级,但这样会很麻烦!!! 以下值得推荐!!! 解决方法一:在代码前加上下面的代码 from tensorf ...
- MySQL增加多用户及数据库
登录MYSQL(有ROOT权限),这里以ROOT身份登录: @>mysql -u root -p @>密码 首先为用户创建一个数据库(yc): mysql>create databa ...