【Redis技术探索】「数据迁移实战」手把手教你如何实现在线+离线模式进行迁移Redis数据实战指南(在线同步数据)
从实战出发使用RedisShake进行Redis数据在线+离线模式迁移指南
RedisShake基本介绍
RedisShake是基于redis-port基础上进行改进的是一款开源的Redis迁移工具,支持Cluster集群的在线迁移与离线迁移(备份文件导入)。数据可平滑迁移,当部署在其他云厂商Redis服务上的Cluster集群数据,由于SYNC、PSYNC命令被云厂商禁用,无法在线迁移时,可以选择离线迁移。
RedisShake使用背景
RedisShake是一个用于在两个Redis实例之间同步数据的工具,满足非常灵活的同步与迁移需求。Redis实例之间的关系其中可能存在(standalone->standalone),(standalone->Cluster),(Cluster->Cluster)等。目前,比较常用的一个数据迁移工具是Redis-Shake ,这是阿里云Redis和MongoDB团队开发的一个用于 Redis 数据同步的工具。
RedisShake功能说明
RedisShake主要是支持Redis的RDB文件的解析、恢复、备份、同步四个功能:
- 恢复(restore):将 RDB 文件恢复到目标Redis数据库。
- 备份(dump):将源 Redis 的全量数据通过RDB文件备份起来。
- 解析(decode):读取 RDB 文件,并以 JSON 格式解析存储。
- 同步(sync):支持源redis和目的redis的数据同步,支持全量和增量数据的迁移,支持从云下到阿里云云上的同步,也支持云下到云下不同环境的同步,支持单节点、主从版、集群版之间的互相同步。
- 同步(rump):支持源 Redis 和目的 Redis 的数据同步,仅支持全量迁移。采用scan和restore命令进行迁移,支持不同云厂商不同redis版本的迁移。
注意:如果源端是集群版,可以启动一个RedisShake,从不同的db结点进行拉取,同时源端不能开启move slot功能;对于目的端,如果是集群版,写入可以是1个或者多个db结点。
Redis-Shake特性概览
- 高性能:全量同步阶段并发执行,增量同步阶段异步执行,能够达到毫秒级别延迟(取决于网络延迟)。同时,我们还对大key同步进行分批拉取,优化同步性能。
- 在 Redis 5.0、Redis 6.0 和 Redis 7.0 上测试
- 支持使用lua自定义过滤规则
- 支持大实例迁移
- 支持restore模式和sync模式
- 支持阿里云 Redis 和 ElastiCache
- 监控体系:用户可以通过我们提供的restful拉取metric来对redis-shake进行实时监控:curl 127.0.0.1:9320/metric。
- 数据校验:如何校验同步的正确性?可以采用我们开源的redis-full-check。
- 支持版本:支持2.8-5.0版本的同步,此外还支持codis,支持云下到云上,云上到云上,云上到云下(阿里云目前支持主从版),其他云到阿里云等链路,帮助用户灵活构建混合云场景。
- 断点续传。支持断开后按offset恢复,降低因主备切换、网络抖动造成链路断开重新同步拉取全量的性能影响。
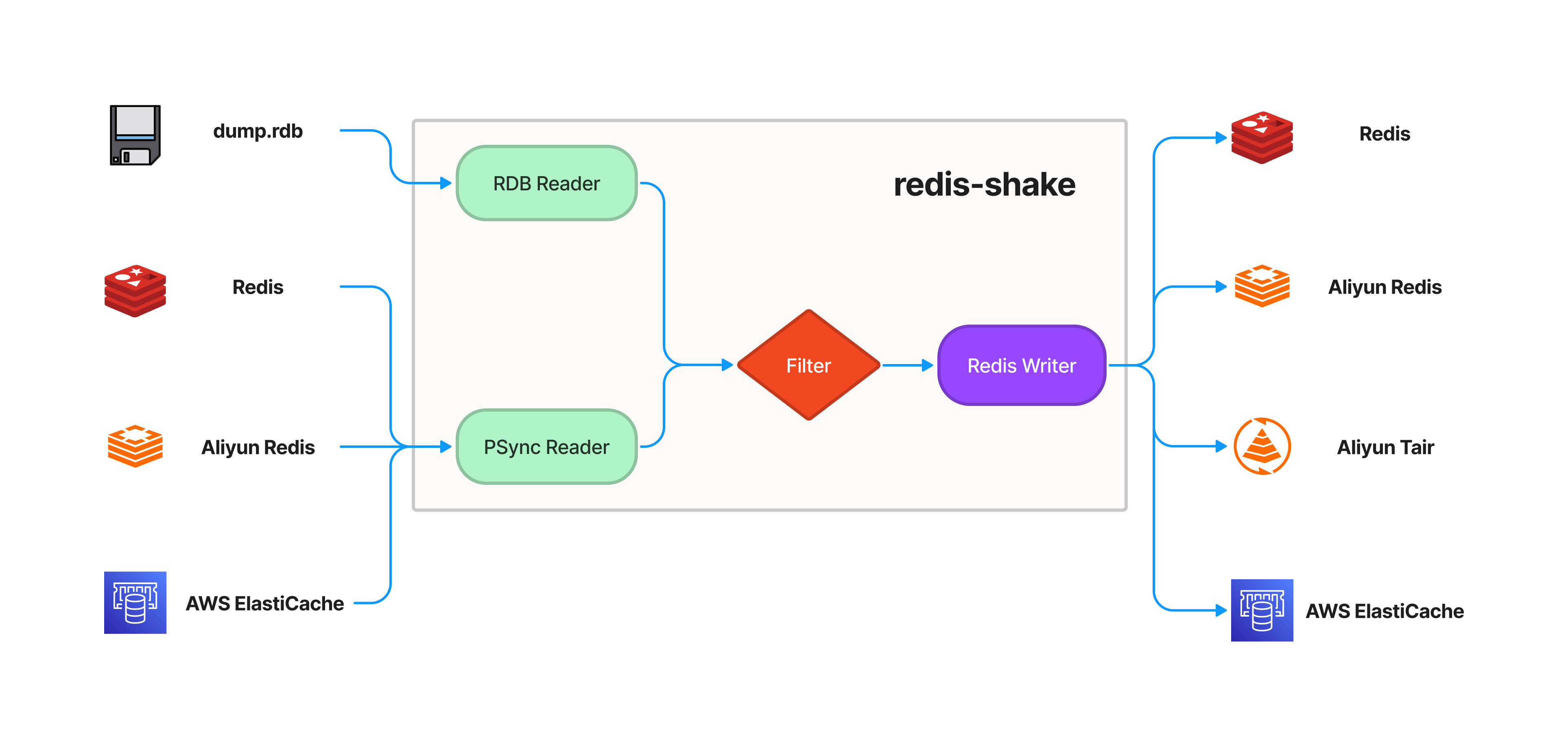
RedisShake执行过程
启动Redis-shake进程,这个进程模拟了一个 Redis 实例,Redis-shake的基本原理就是模拟一个Slave从节点加入源Redis集群,然后进行增量的拉取(通过psync命令)。
Redis-shake进程和数据迁出的源实例进行数据的全量拉取同步,并回放,这个过程和 Redis 主从实例的全量同步是类似的。如下图所示。
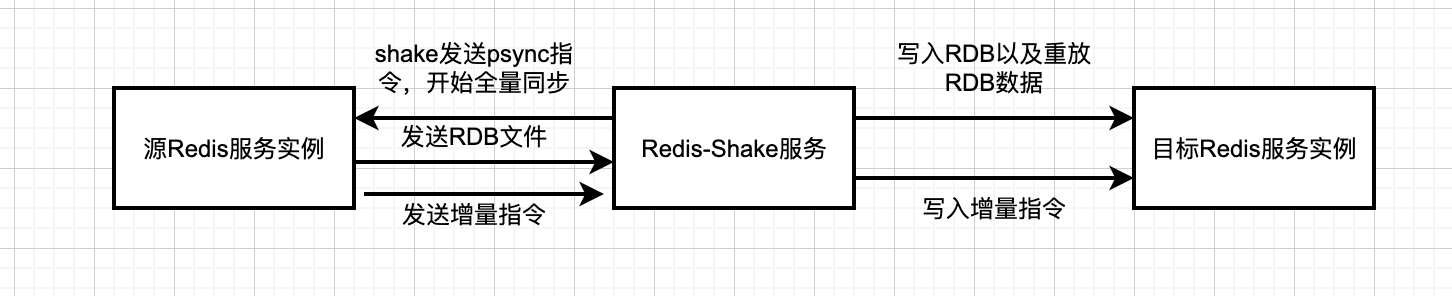
详细分析上述同步原理
源Redis服务实例相当于主库,Redis-shake相当于从库,它会发送psync指令给源Redis服务实例。
源Redis实例先把RDB文件传输给 Redis-shake ,Redis-shake 会把RDB文件发送给目的实例。
源实例会再把增量命令发送给 Redis-shake ,Redis-shake负责把这些增量命令再同步给目的实例。
如果源端是集群模式,只需要启动一个redis-shake进行拉取,同时不能开启源端的move slot操作。如果目的端是集群模式,可以写入到一个结点,然后再进行slot的迁移,当然也可以多对多写入。
目前,redis-shake到目的端采用单链路实现,对于正常情况下,这不会成为瓶颈,但对于极端情况,qps比较大的时候,此部分性能可能成为瓶颈,后续我们可能会计划对此进行优化。另外,redis-shake到目的端的数据同步采用异步的方式,读写分离在2个线程操作,降低因为网络时延带来的同步性能下降。
Redis-Shake安装使用
主要有两种方式:下载Release版本的可执行二进制包、下载源码文件进行编译操作这两种方式。
下载Release版本的可执行二进制包
点击下载就可以进行直接使用Redis-Shake服务。
下载源码文件进行编译操作
除了直接下载可执行包之外,还可以下载源码之后,可以进行运行build.sh文件执行进行编译源码,生成可执行包。可以根据上面的下载中source code进行下载。
或者可以针对于Git进行clone源码仓库,如下所示。
git clone https://github.com/alibaba/RedisShake
cd RedisShake
sh build.sh
运行Redis-Shake服务
首先如果需要进行同步和重放,则需要进行编辑sync.toml文件以及编辑restore.toml.
- redis-shake 支持三种数据迁移模式:sync、restore 和 scan:
- 快速开始:数据迁移(使用 sync 模式)
- 快速开始:从dump.rdb恢复数据(使用 restore 模式)
- 快速开始:数据迁移(使用 scan 模式)
- 使用 filters 做数据清洗
- 运行日志
- 运行监控
启动同步sync运行机制
我们打开或者编辑sync.toml
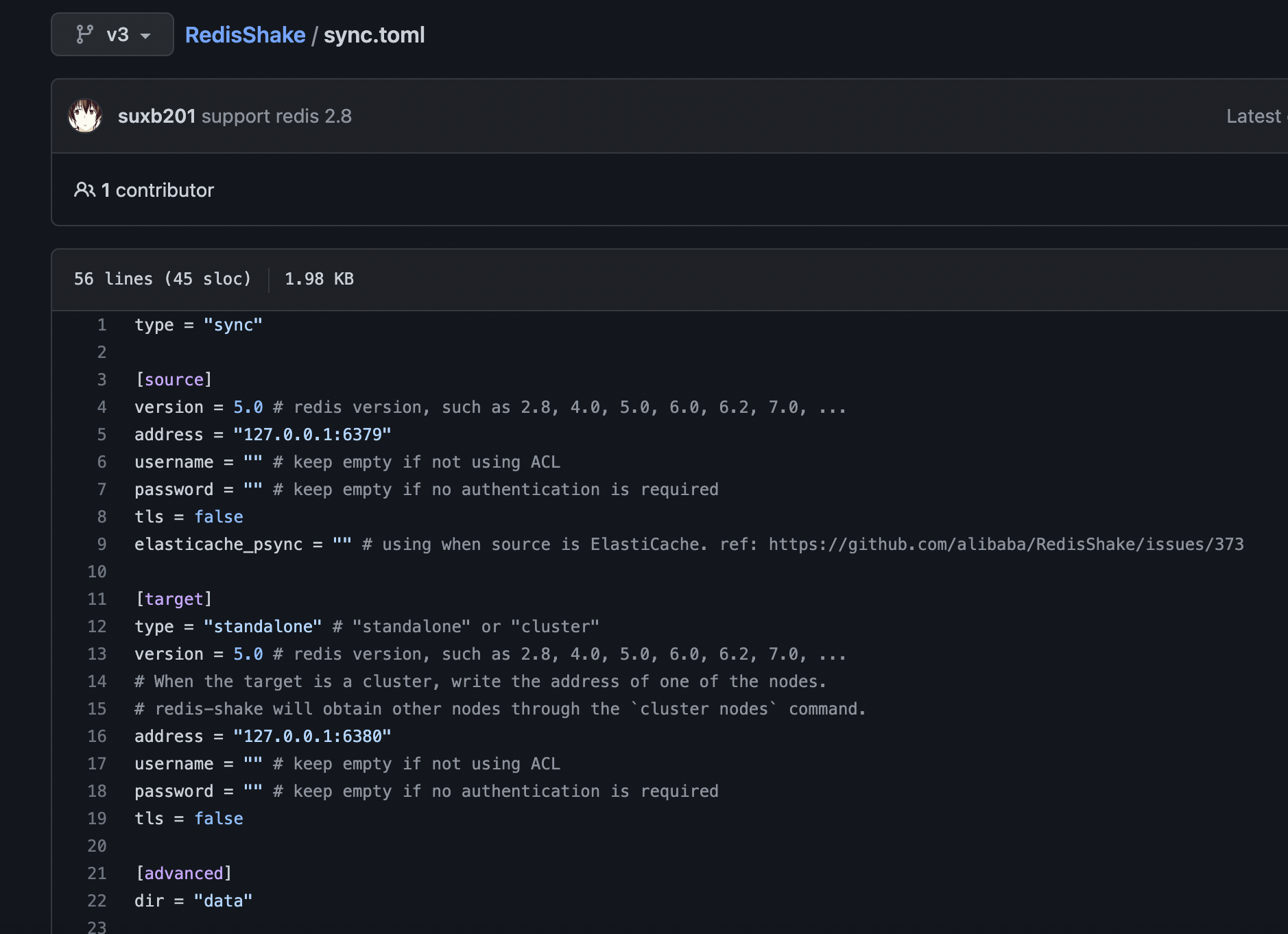
sync.toml文件内容
当我们编辑sync.toml文件之后,可以进行配置我们实际情况下的source源redis实例以及target目标redis实例。之后可以配置对应的cpu和相关性能的配置。下面针对于配置进行相关的配置介绍
type = "sync" # 同步机制实现
[source] # 源Redis服务实例
version = 5.0 # 填写Redis源服务版本, 例如:2.8, 4.0, 5.0, 6.0, 6.2, 7.0, ...。
address = "127.0.0.1:6379" # 源Redis服务实例 地址+端口
username = "" # 如果Redis没有配置ACL,则可以不填写,否则需要填写用户名
password = "" # 如果Redis没有配置ACL,则可以不填写,否则需要填写密码
tls = false # 是否开启tls安全机制
elasticache_psync = "" # 是否支持AWS的elasticache
[target]
type = "standalone" # 选择Redis的类型:"standalone:单机模式" or "cluster:集群模式"
version = 5.0 # 填写Redis源服务版本, 例如:2.8, 4.0, 5.0, 6.0, 6.2, 7.0, ...。
# 如果目标Redis服务实例属于cluster集群模式, 那么可以写入其中一个节点的地址和端口.
# redis-shake 会通过`cluster nodes` 命令获取其他的节点地址和端口
address = "127.0.0.1:6380" # 填写的对应的ip加端口
username = "" # 如果Redis没有配置ACL,则可以不填写,否则需要填写用户名
password = "" # 如果Redis没有配置ACL,则可以不填写,否则需要填写密码
tls = false # 是否开启tls安全机制
[advanced]
dir = "data" # 数据同步的存储目录
# 设置使用的最大CPU核心数, 如果设置了0 代表着 使用 runtime.NumCPU() 实际的cpu cores数量
ncpu = 4
# 开启pprof性能检测的port, 0代表着禁用
pprof_port = 0
# 开启metric port端口, 0代表着禁用
metrics_port = 0
# log的相关设置
log_file = "redis-shake.log" # 设置对应的日志文件名称
log_level = "info" # debug, info or warn # 设置对应的日志级别
log_interval = 5 # in seconds # 日志打印频次
# redis-shake gets key and value from rdb file, and uses RESTORE command to
# create the key in target redis. Redis RESTORE will return a "Target key name
# is busy" error when key already exists. You can use this configuration item
# to change the default behavior of restore:
# panic: redis-shake will stop when meet "Target key name is busy" error.
# rewrite: redis-shake will replace the key with new value.
# ignore: redis-shake will skip restore the key when meet "Target key name is busy" error.
rdb_restore_command_behavior = "rewrite" # restore的操作类型:panic, rewrite or skip
# pipeline的大小数量阈值
pipeline_count_limit = 1024
# Client query buffers accumulate new commands. They are limited to a fixed
# amount by default. This amount is normally 1gb.
target_redis_client_max_querybuf_len = 1024_000_000
# In the Redis protocol, bulk requests, that are, elements representing single
# strings, are normally limited to 512 mb.
target_redis_proto_max_bulk_len = 512_000_000
Redis单机实例同步到Redis单机实例
修改sync.toml,改为如下配置。
[source]
address = "ip:6379"
password = ""
[target]
type = "standalone"
address = "ip:6379"
password = "r-bbbbb:xxxxx"
启动 redis-shake:
./redis-shake sync.toml
Redis单机实例同步到Redis集群实例
修改 sync.toml,改为如下配置:
[source]
address = "r-aaaaa.redis.zhangbei.rds.aliyuncs.com:6379"
password = "r-aaaaa:xxxxx"
[target]
type = "cluster"
address = "192.168.0.1:6379" # 这里写集群中的任意一个节点的地址即可
password = "r-ccccc:xxxxx"
启动 redis-shake:
./redis-shake sync.toml
Redis集群实例同步到Redis集群实例
方法1:手动起多个 redis-shake
集群C有四个节点:
- 192.168.0.1:6379
- 192.168.0.2:6379
- 192.168.0.3:6379
- 192.168.0.4:6379
把4个节点当成4个单机实例,参照单机到集群 部署 4 个 redis-shake 进行数据同步。不要在同一个目录启动多个 redis-shake,因为 redis-shake 会在本地存储临时文件,多个 redis-shake 之间的临时文件会干扰,正确做法是建立多个目录。
方法2:借助 cluster_helper.py 启动
脚本cluster_helper.py可以方便启动多个redis-shake从集群迁移数据,效果等同于方法1。
注意
源端有多少个分片,cluster_helper.py 就会起多少个 redis-shake 进程,所以如果源端分片数较多的时候,需要评估当前机器是否可以承担这么多进程。
cluster_helper.py 异常退出的时候,可能没有正常退出 redis-shake 进程,需要 ps aux | grep redis-shake 检查。
每个 redis-shake 进程的执行日志记录在 RedisShake/cluster_helper/data/xxxxx 中,反馈问题请提供相关日志。
依赖
Python 需要 python3.6 及以上版本,安装 Python依赖:
cd RedisShake/cluster_helper
pip3 install -r requirements.txt
配置
修改 sync.toml:
type = "sync"
[source]
address = "192.168.0.1:6379" # 集群 C 中任意一个节点地址
password = "r-ccccc:xxxxx"
[target]
type = "cluster"
address = "192.168.1.1:6380" # 集群 D 中任意一个节点地址
password = "r-ddddd:xxxxx"
运行
cd RedisShake/cluster_helper
python3 cluster_helper.py ../redis-shake ../sync.toml
- 参数 1 是 redis-shake 可执行程序的路径
- 参数 2 是配置文件路径
查看redis-shake的日志信息
[root@redis ~]# redis-shake ./redis-shake.toml
2022-08-26 11:20:28 INF GOOS: linux, GOARCH: amd64
2022-08-26 11:20:28 INF Ncpu: 3, GOMAXPROCS: 3
2022-08-26 11:20:28 INF pid: 21504
2022-08-26 11:20:28 INF pprof_port: 0
2022-08-26 11:20:28 INF No lua file specified, will not filter any cmd.
2022-08-26 11:20:28 INF no password. address=[127.0.0.1:6380]
2022-08-26 11:20:28 INF redisWriter connected to redis successful. address=[127.0.0.1:6380]
2022-08-26 11:20:28 INF no password. address=[127.0.0.1:6379]
2022-08-26 11:20:28 INF psyncReader connected to redis successful. address=[127.0.0.1:6379]
2022-08-26 11:20:28 WRN remove file. filename=[4200.aof]
2022-08-26 11:20:28 WRN remove file. filename=[dump.rdb]
2022-08-26 11:20:28 INF start save RDB. address=[127.0.0.1:6379]
2022-08-26 11:20:28 INF send [replconf listening-port 10007]
2022-08-26 11:20:28 INF send [PSYNC ? -1]
2022-08-26 11:20:28 INF receive [FULLRESYNC 1db7c7618b6d0af25ffafb1645d4fba573624d02 0]
2022-08-26 11:20:28 INF source db is doing bgsave. address=[127.0.0.1:6379]
2022-08-26 11:20:28 INF source db bgsave finished. timeUsed=[0.09]s, address=[127.0.0.1:6379]
2022-08-26 11:20:28 INF received rdb length. length=[194]
2022-08-26 11:20:28 INF create dump.rdb file. filename_path=[dump.rdb]
2022-08-26 11:20:28 INF save RDB finished. address=[127.0.0.1:6379], total_bytes=[194]
2022-08-26 11:20:28 INF start send RDB. address=[127.0.0.1:6379]
2022-08-26 11:20:28 INF RDB version: 8
2022-08-26 11:20:28 INF RDB AUX fields. key=[redis-ver], value=[4.0.14]
2022-08-26 11:20:28 INF RDB AUX fields. key=[redis-bits], value=[64]
2022-08-26 11:20:28 INF RDB AUX fields. key=[ctime], value=[1661484028]
2022-08-26 11:20:28 INF RDB AUX fields. key=[used-mem], value=[1897096]
2022-08-26 11:20:28 INF RDB repl-stream-db: 0
2022-08-26 11:20:28 INF RDB AUX fields. key=[repl-id], value=[1db7c7618b6d0af25ffafb1645d4fba573624d02]
2022-08-26 11:20:28 INF RDB AUX fields. key=[repl-offset], value=[0]
2022-08-26 11:20:28 INF RDB AUX fields. key=[aof-preamble], value=[0]
2022-08-26 11:20:28 INF RDB resize db. db_size=[1], expire_size=[0]
2022-08-26 11:20:28 INF send RDB finished. address=[127.0.0.1:6379], repl-stream-db=[0]
2022-08-26 11:20:28 INF start save AOF. address=[127.0.0.1:6379]
2022-08-26 11:20:28 INF AOFWriter open file. filename=[0.aof]
2022-08-26 11:20:29 INF AOFReader open file. aof_filename=[0.aof]
2022-08-26 11:20:33 INF syncing aof. allowOps=[0.20], disallowOps=[0.00], entryId=[0], unansweredBytesCount=[0]bytes, diff=[0], aofReceivedOffset=[0], aofAppliedOffset=[0]
2022-08-26 11:20:38 INF syncing aof. allowOps=[0.20], disallowOps=[0.00], entryId=[1], unansweredBytesCount=[0]bytes, diff=[0], aofReceivedOffset=[14], aofAppliedOffset=[14]
2022-08-26 11:20:43 INF syncing aof. allowOps=[0.00], disallowOps=[0.00], entryId=[1], unansweredBytesCount=[0]bytes, diff=[0], aofReceivedOffset=[14], aofAppliedOffset=[14]
2022-08-26 11:20:48 INF syncing aof. allowOps=[0.20], disallowOps=[0.00], entryId=[2], unansweredBytesCount=[0]bytes, diff=[0], aofReceivedOffset=[28], aofAppliedOffset=[28]
【Redis技术探索】「数据迁移实战」手把手教你如何实现在线+离线模式进行迁移Redis数据实战指南(在线同步数据)的更多相关文章
- 新书上线:《Spring Boot+Spring Cloud+Vue+Element项目实战:手把手教你开发权限管理系统》,欢迎大家买回去垫椅子垫桌脚
新书上线 大家好,笔者的新书<Spring Boot+Spring Cloud+Vue+Element项目实战:手把手教你开发权限管理系统>已上线,此书内容充实.材质优良,乃家中必备垫桌脚 ...
- Flutter实战:手把手教你写Flutter Plugin
前言 如果你对移动端有所关注,那么你一定会听说过Flutter.得益于Google,Flutter一经推出便得受到了广泛关注.很多开发者跃跃欲试,国内部分大厂,诸如美团.闲鱼等团队已经开始了Flutt ...
- 「Netty实战 02」手把手教你实现自己的第一个 Netty 应用!新手也能搞懂!
大家好,我是 「后端技术进阶」 作者,一个热爱技术的少年. 很多小伙伴搞不清楚为啥要学习 Netty ,今天这篇文章开始之前,简单说一下自己的看法: @ 目录 服务端 创建服务端 自定义服务端 Cha ...
- 【SpringCloud技术专题】「Gateway网关系列」(3)微服务网关服务的Gateway全流程开发实践指南(2.2.X)
开发指南须知 本次实践主要在版本:2.2.0.BUILD-SNAPSHOT上进行构建,这个项目提供了构建在Spring生态系统之上API网关. Spring Cloud Gateway的介绍 Spri ...
- CNN实战篇-手把手教你利用开源数据进行图像识别(基于keras搭建)
我一直强调做深度学习,最好是结合实际的数据上手,参照理论,对知识的掌握才会更加全面.先了解原理,然后找一匹数据来验证,这样会不断加深对理论的理解. 欢迎留言与交流! 数据来源: cifar10 (其 ...
- 手把手教你AspNetCore WebApi:缓存(MemoryCache和Redis)
前言 这几天小明又有烦恼了,系统上线一段时间后,系统性能出现了问题,马老板很生气,叫小明一定要解决这个问题.性能问题一般用什么来解决呢?小明第一时间想到了缓存. 什么是缓存 缓存是实际工作中非常常用的 ...
- 手把手教你用python打造网易公开课视频下载软件3-对抓取的数据进行处理
上篇讲到抓取的数据保存到rawhtml变量中,然后通过编码最终保存到html变量当中,那么html变量还会有什么问题吗?当然会有了,例如可能html变量中的保存的抓取的页面源代码可能有些标签没有关闭标 ...
- 【目标检测实战】目标检测实战之一--手把手教你LMDB格式数据集制作!
文章目录 1 目标检测简介 2 lmdb数据制作 2.1 VOC数据制作 2.2 lmdb文件生成 lmdb格式的数据是在使用caffe进行目标检测或分类时,使用的一种数据格式.这里我主要以目标检测为 ...
- Caffe系列2——Windows10制作LMDB数据详细过程(手把手教你制作LMDB)
Windows10制作LMDB详细教程 原创不易,转载请注明出处:https://www.cnblogs.com/xiaoboge/p/10678658.html 摘要: 当我们在使用Caffe做深度 ...
- [swift实战入门]手把手教你编写2048(一)
苹果设备越来越普及,拿着个手机就想捣鼓点啥,于是乎就有了这个系列,会一步一步教大家学习swift编程,学会自己做一个自己的app,github地址:https://github.com/scarlet ...
随机推荐
- 插入排序算法(Java代码实现)
其它经典排序算法:https://blog.csdn.net/weixin_43304253/article/details/121209905 插入排序算法: 思路:将数据分为已经排序好的数据和未排 ...
- 2、第二种传输数据的形式:使用ajax传输数据,将前台的数据传输到后端
第一种使用form表单中的action形式传输数据:https://blog.csdn.net/weixin_43304253/article/details/120335282 前端页面 <% ...
- python和C语言从路径中获取文件名
1.Python import os file_name = os.path.basename(filepath)#带后缀的文件名(不含路径) file_name_NoExtension = os.p ...
- git 多个commit 如何合并
git 多个commit 如何合并 本篇主要介绍一下 git 中多个commit 如何合并, 因为commit 太多 会导致提交记录混乱, 所以有时候会把多个commit 合并成一个 保持提交记录干净 ...
- DNS 解析 prefeath
本文将详细介绍DNS预解析prefetch的主要内容 概述 DNS(Domain Name System, 域名系统),是域名和IP地址相互映射的一个分布式数据库.DNS 查询就是将域名转换成 IP ...
- Redis管理及监控工具推荐
推荐一款Redis管理软件.[官网 http://www.redisant.cn/] 功能描述: 1. 键和字段CRUD和glob. 2. 适用于字符串.列表.散列.集合.有序集合. 通过漂亮的用户界 ...
- Mp3文件标签信息读取和写入(Kotlin)
原文:Mp3文件标签信息读取和写入(Kotlin) - Stars-One的杂货小窝 最近准备抽空完善了自己的星之小说下载器(JavaFx应用 ),发现下载下来的mp3文件没有对应的标签 也是了解可以 ...
- 嵌入式-C语言基础:malloc动态开辟内存空间
#include<stdio.h> #include<stdlib.h> int main() { // char *p;//定义一个野指针:没有让它指向一个变量的地址 // ...
- zk,kafka,redis哨兵,mysql容器化
1. zookeeper,kafka容器化 1.1 zookeeper+kafka单机docker模式 docker pull bitnami/zookeeper:3.6.3-debian-11-r4 ...
- [排序算法] 归并排序 (C++)
归并排序解释 归并排序 Merge Sort 是典型的分治法的应用,其算法步骤完全遵循分治模式. 分治法思想 分治法 思想: 将原问题分解为几个规模较小但又保持原问题性质的子问题,递归求解这些子问题, ...