5.django-模型ORM
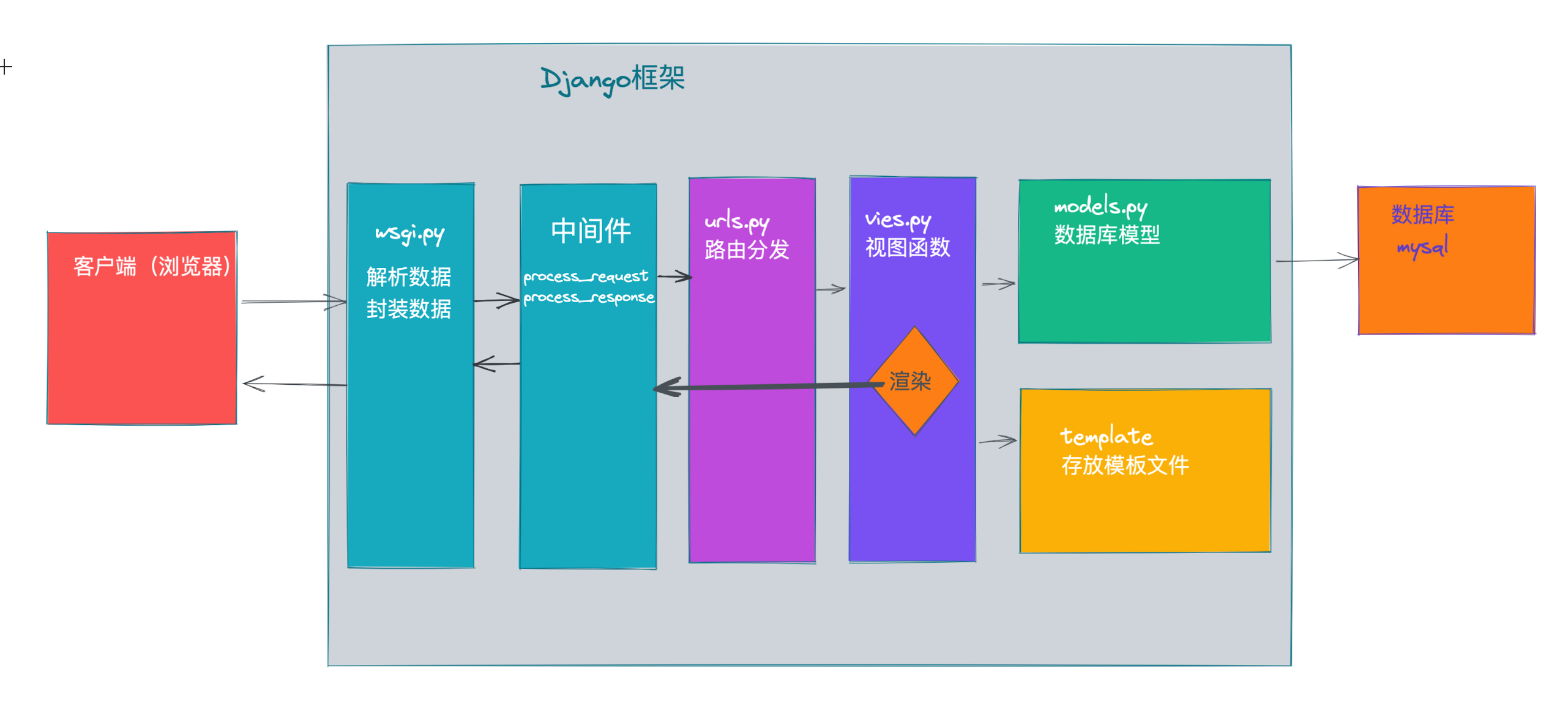
Django中内嵌了ORM框架,不需要直接编写SQL语句进行数据库的操作,通过定义模型类来完成对数据库中表的操作
O:Object,也就是类对象的意思 R:Relation,关系数据库中表的意思 M:Mapping:映射
模型类:映射的是sql语句中的table表 类对象:映射表中的某一行数据 类成员:映射表的字段
ORM的优点:
定义模型类,更加容易维护
不必编写复杂的SQL语句,开发效率高
兼容多种数据库,可以自由切换数据库
ORM的缺点:
ORM不是轻量级工具,需要花费较大的精力学习
性能相对原生的SQL差一些
ORM的使用主要以下四步
1. 配置数据库的连接
2. 在model.py中定义模型类
3. 生成数据库迁移文件并执行迁移文件
4. 通过模型类对象提供的方法操作数据库
1.配置数据库连接
1.1 配置单个mysql数据库
django中默认配置的数据库是sqlite,如果想切换为mysql,操作如下
- 安装pymysql模块
pip install pymysql
- 在工程项目的
__init__.py文件中添加如下语句
from pymysql import install_as_MySQLdb
install_as_MySQLdb() # 让pymysql以MySQLDB的运行模式和Django的ORM对接运行 - 修改setting.py中的配置如下
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 指定mysql引擎
'HOST': '127.0.0.1', # 数据库主机
'PORT': 3306, # 数据库端口
'USER': 'root', # 数据库用户名
'PASSWORD': '123', # 数据库用户密码
'NAME': 'student' # 数据库名字
}
} - 在mysql中创建对应的数据库
ORM 无法主动创建数据库,我们需要在连接的数据库中先创建数据库
create database student default charset=utf8mb4; # mysql8.0之前的版本
- 如果想打印orm转换过程中的sql,需要在settings.py中进行如下配置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
1.2 配置多个mysql数据库
jango支持连接多个mysql数据库
主要在配置文件中添加如下(在上面的基础上)
DATABASES = {
"default": {
'ENGINE': 'dj_db_conn_pool.backends.mysql',
'NAME': 'day05db', # 数据库名字
'USER': 'root',
'PASSWORD': 'root123',
'HOST': '127.0.0.1', # ip
'PORT': 3306,
'POOL_OPTIONS': {
'POOL_SIZE': 10, # 最小
'MAX_OVERFLOW': 10, # 在最小的基础上,还可以增加10个,即:最大20个。
'RECYCLE': 24 * 60 * 60, # 连接可以被重复用多久,超过会重新创建,-1表示永久。
'TIMEOUT': 30, # 池中没有连接最多等待的时间。
}
},
"bak": {
'ENGINE': 'dj_db_conn_pool.backends.mysql',
'NAME': 'day05bak', # 数据库名字
'USER': 'root',
'PASSWORD': 'root123',
'HOST': '127.0.0.1', # ip
'PORT': 3306,
'POOL_OPTIONS': {
'POOL_SIZE': 10, # 最小
'MAX_OVERFLOW': 10, # 在最小的基础上,还可以增加10个,即:最大20个。
'RECYCLE': 24 * 60 * 60, # 连接可以被重复用多久,超过会重新创建,-1表示永久。
'TIMEOUT': 30, # 池中没有连接最多等待的时间。
}
},
}
2.定义模型类
模型类的定义
模型类一般定义在子项目的models.py
模型类必须直接或者间接的继承django.db.midels.Model类
2.1 单张表的模型类创建
2.1.1 表名设置
模型类如果未指明表名db_table,Django默认以 小写app应用名_小写模型类名 为数据库表名。
可通过db_table 指明数据库表名。
2.1.2 关于主键
django会为表创建自动增长的主键列,每个模型只能有一个主键列。
如果使用选项设置某个字段的约束属性为主键列(primary_key)后,django不会再创建自动增长的主键列。
一般情况下我们不需要主动创建,默认创建的主键属性明为id,或者pk
class Student(models.Model):
# django会自动在创建数据表的时候生成id主键/还设置了一个调用别名 pk
id = models.AutoField(primary_key=True, null=False, verbose_name="主键") # 设置主键
2.1.3 属性命名规范
不能是python的保留关键字
不允许使用两个连续的下划线,这是由django的查询方式决定的,__是关键字
定义属性时需要指定字段类型,通过字段类型的参数自定选项,如下:
属性名 = models.字段类型(约束选项, verbose_name="注释")
2.1.4 字段类型
| 类型 | 说明 |
|---|---|
| AutoField | 自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性 |
| BooleanField | 布尔字段,值为True或False |
| NullBooleanField | 支持Null、True、False三种值 |
| CharField | 字符串,参数max_length表示最大字符个数,对应mysql中的varchar |
| TextField | 大文本字段,一般大段文本(超过4000个字符)才使用。 |
| IntegerField | 整数 |
| DecimalField | 十进制浮点数, 参数max_digits表示总位数, 参数decimal_places表示小数位数,常用于表示分数和价格 Decimal(max_digits=7, decimal_places=2) ==> 99999.99~ 0.00 |
| FloatField | 浮点数 |
| DateField | 日期 参数auto_now表示每次保存对象时,自动设置该字段为当前时间。 参数auto_now_add表示当对象第一次被创建时自动设置当前。 参数auto_now_add和auto_now是相互排斥的,一起使用会发生错误。 |
| TimeField | 时间,参数同DateField |
| DateTimeField | 日期时间,参数同DateField |
| FileField | 上传文件字段,django在文件字段中内置了文件上传保存类, django可以通过模型的字段存储自动保存上传文件, 但是, 在数据库中本质上保存的仅仅是文件在项目中的存储路径!! |
| ImageField | 继承于FileField,对上传的内容进行校验,确保是有效的图片 |
2.1.5 约束选项
| null | 如果为True,表示允许为空,默认值是False。相当于python的None |
|---|---|
| blank | 如果为True,则该字段允许为空白,默认值是False。 相当于python的空字符串,“” |
| db_column | 字段的名称,如果未指定,则使用属性的名称。 |
| db_index | 若值为True, 则在表中会为此字段创建索引,默认值是False。 相当于SQL语句中的key |
| default | 默认值,当不填写数据时,使用该选项的值作为数据的默认值。 |
| primary_key | 如果为True,则该字段会成为模型的主键,默认值是False,一般不用设置,系统默认设置。 |
| unique | 如果为True,则该字段在表中必须有唯一值,默认值是False。相当于SQL语句中的unique |
| max_length | 字段的最大长度 |
| verbose_name | 字段别名,以后展示在前端可以使用 |
2.2 关联表的模型类创建
关联模型类的关系有以下三种
一对一
一对多
多对多
2.2.1 一对一
两张表是一对一的关系,也就是一张表的一条数据只能对应另外一张表的一条数据
OneToOneField()
如:学生和学生详细信息
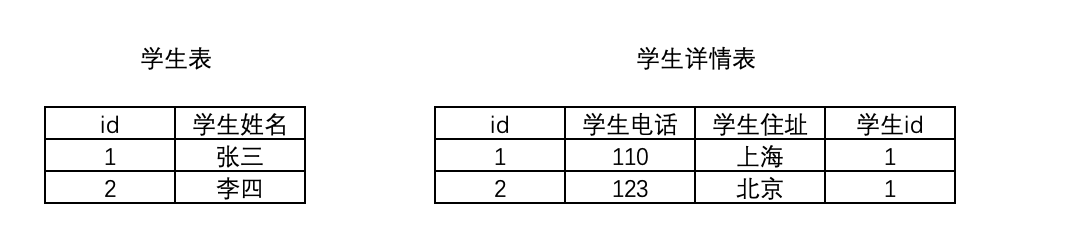
class Student(models.Model):
name = models.CharField(max_length=32, verbose_name='学生姓名') class StudentDetail(models.Model):
telephone = models.CharField(max_length=16, verbose_name='学生电话')
address = models.CharField(max_length=16, verbose_name="学生住址")
# 一对一
student = models.OneToOneField(to=Student, verbose_name='学生ID', on_delete=models.CASCADE)
2.2.2 一对多
两张表是一对多的关系,也就是一张表的一条数据对应另外一张表的多条数据
ForeignKey
如:学生表和班级表,一个班级可以有很多学生
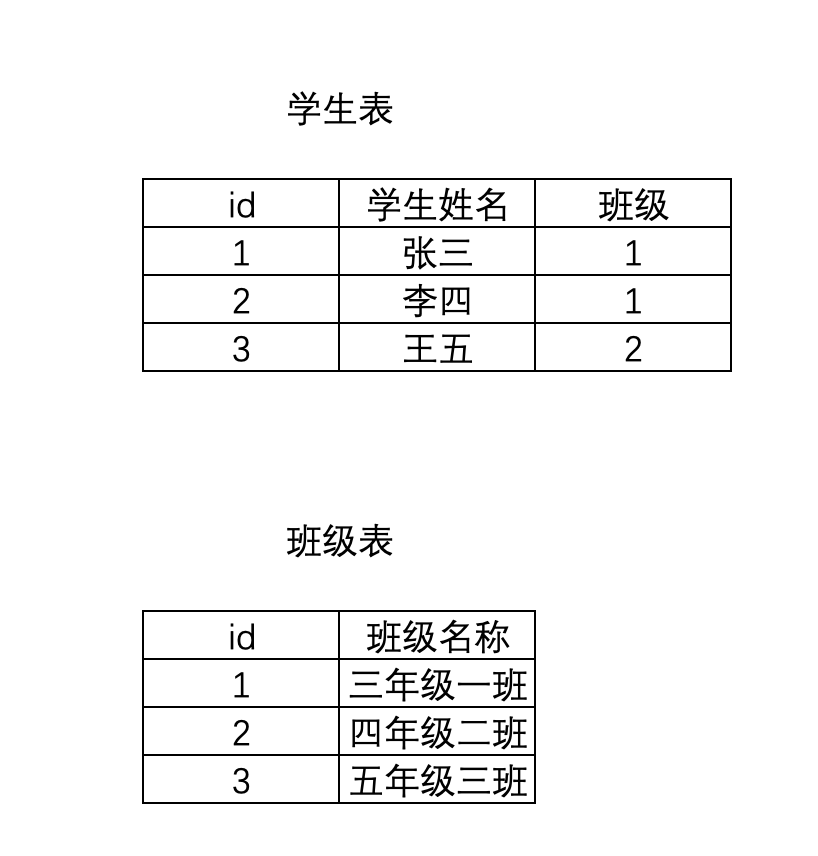
class Cls(models.Model):
title = models.CharField(max_length=32, verbose_name='班级名称') class Student(models.Model):
name = models.CharField(max_length=32, verbose_name='学生姓名')
# 一对多
cls = models.ForeignKey(to=Cls, verbose_name='班级名称', on_delete=models.CASCADE)
注意:在一对多中,必须指定on_delete删除模式,就比如删除了班级表中的数据,学生表中相关的数据该做何处理,常见的处理如下
- CASCADE, # 级联删除,即关联的表删除某一项数据,此表关联的数据都会被删除
- DO_NOTHING, # 删除关联数据,什么也不做
- SET_NULL, # 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
- SET_DEFAULT # 设置为默认值,仅在该字段设置了默认值时可用
SET(值), # 删除关联数据, 与之关联的值设置为指定值
2.2.3 多对多
多对多就是一张表的一行数据可以对应另一张表的多行数据,反之亦然
ManyToManyField
或者自定义第三个类
如学生表和选修课程表,这需要通过第三张表的引入,来关联二者的关系
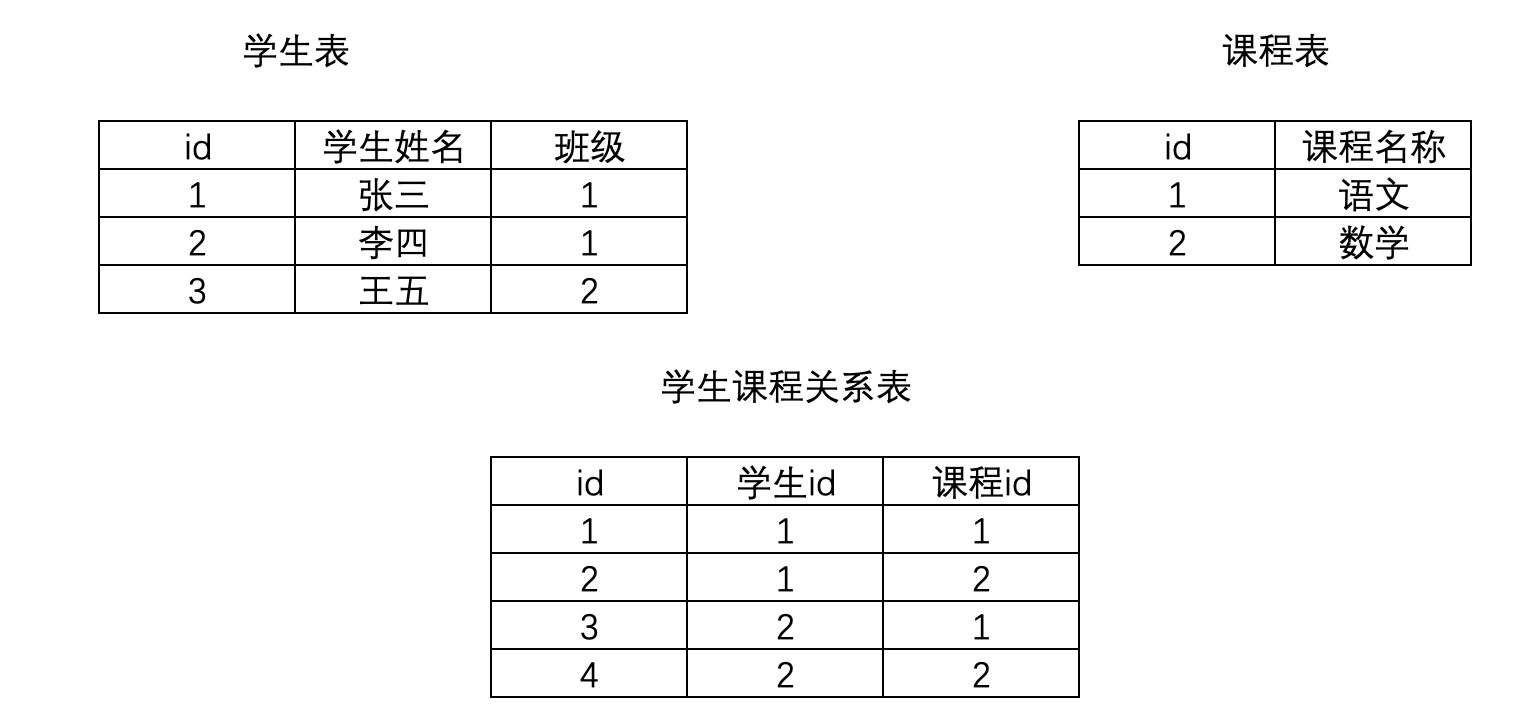
方式一(推荐)
class Course(models.Model):
title = models.CharField(max_length=32, verbose_name='课程名称') class Student(models.Model):
name = models.CharField(max_length=32, verbose_name='学生姓名')# 多对多
course = models.ManyToManyField(to=Course, verbose_name='课程')
方式二
class Course(models.Model):
title = models.CharField(max_length=32, verbose_name='课程名称') class Student(models.Model):
name = models.CharField(max_length=32, verbose_name='学生姓名')class Student_Course(models.Model):
student = models.ForeignKey(to=Student, on_delete=models.CASCADE)
course = models.ForeignKey(to=Course, on_delete=models.CASCADE)
3.数据迁移
在django中数据迁移分为两步
- 生成迁移文件
python manage.py makemigrations

- 同步到数据库
python manage.py migrate

4.操作数据库
4.1 单张表的数据库基本操作
4.1.1 添加记录
- save()方法
通过创建模型类对象,执行对象的save()方法保存到数据库中role = Role(title='销售顾问')
role.save() - create()方法
过模型类.objects.create()保存,返回生成的模型类对象
obj = Role.objects.create(title='总经理')
4.1.2 修改记录
- 使用save更新数据【不建议】
会将对象的所有值都更新一遍student = Student.objects.filter(name='刘德华').first()
student.age = 19
student.classmate = "303"
student.save() - update更新(推荐)
# update是全局更新,只要符合更新的条件,则全部更新,因此强烈建议加上条件!!!
student = Student.objects.filter(name="赵华",age=22).update(name="刘芙蓉",sex=True)
4.1.3 删除记录
模型类对象.delete
student = Student.objects.get(id=13)
student.delete()- 模型类.objects.filter().delete()
Student.objects.filter(id=14).delete()
4.1.4 基础查询
ORM中针对查询结果的限制,提供了一个查询集[QuerySet].这个QuerySet,是ORM中针对查询结果进行保存数据的一个类型,我们可以通过了解这个QuerySet进行使用,达到查询优化,或者限制查询结果数量的作用。
- all()
查询所有对象,返回一个queryset对象,所有对象的集合queryset = Role.objects.all()
# <QuerySet [<Role: Role object (1)>, <Role: Role object (2)>]> - filter()
筛选条件相匹配的对象,返回queryset对象。
queryset = Role.objects.filter(title='总经理')
# <QuerySet [<Role: Role object (1)>]> - get()
返回与所给筛选条件相匹配的对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。
try:
student = Student.objects.get(name="kunmzhao")
print(student)
print(student.description)
except Student.MultipleObjectsReturned:
print("查询得到多个结果!")
except Student.DoesNotExist:
print("查询结果不存在!") - first()/last()
分别为查询集的第一条记录和最后一条记录,返回一个对象
stu01 = Student.objects.first()
stu02 = Student.objects.last() - exclude()
筛选条件不匹配的对象,返回queryset对象。
# 查询张三以外的所有的学生
students = Student.objects.exclude(name="张三") - order_by()
对查询结果排序,返回一个queryset对象
# order_by("字段") # 按指定字段正序显示,相当于 asc 从小到大
# order_by("-字段") # 按字段倒序排列,相当于 desc 从大到小
# order_by("第一排序","第二排序",...) # 查询所有的男学生按年龄从高到低展示
# students = Student.objects.all().order_by("-age","-id")
students = Student.objects.filter(sex=1).order_by("-age", "-id") - count()
查询集中对象的个数
# 查询所有男生的个数
count = Student.objects.filter(sex=1).count()
print(count) - exists()
判断查询集中是否有数据,如果有则返回True,没有则返回False
# 查询Student表中是否存在学生
Student.objects.exists() - values()/values_list()
value()把结果集中的模型对象转换成字典,并可以设置转换的字段列表,达到减少内存损耗,提高性能values_list(): 把结果集中的模型对象转换成列表,并可以设置转换的字段列表(元祖),达到减少内存损耗,提高性能
# values 把查询结果中模型对象转换成字典
student_list = student_list.order_by("-age")
ret1 = student_list.values() # 默认把所有字段全部转换并返回
ret2 = student_list.values("id","name","age") # 可以通过参数设置要转换的字段并返回
ret3 = student_list.values_list() # 默认把所有字段全部转换并返回
ret4 = student_list.values_list("id","name","age") # 可以通过参数设置要转换的字段并返回 - distinct()
从返回结果中剔除重复纪录。返回queryset。
# 查询所有学生出现过的年龄
print(Student.objects.values("age").distinct())
4.1.5 模糊查询
基于双下划线查询
- contains
例:查询姓名包含'华'的学生。tudent.objects.filter(name__contains='华')
- startswith、endswith
查询姓名以'文'结尾的学生
Student.objects.filter(name__endswith='文')
- isnull
查询个性签名不为空的学生
student_list = Student.objects.filter(description__isnull=True)
- in
查询编号为1或3或5的学生
Student.objects.filter(id__in=[1, 3, 5])
gt 大于 (greater then)
gte 大于等于 (greater then equal)
lt 小于 (less then)
lte 小于等于 (less then equal)
比较查询
查询编号大于3的学生
Student.objects.filter(id__gt=3)
- 日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
查询2010年被添加到数据中的学生。Student.objects.filter(born_date__year=1980)
例:查询2016年6月20日后,2017年6月21号之前添加的学生信息
from django.utils import timezone as datetime
Student.objects.filter(created_time__gte=datetime.datetime(2016,6,20),created_time__lt=datetime.datetime(2017,6,21)).all()
4.1.6 进阶查询
4.1.6.1 F查询
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
语法如下:
"""F对象:2个字段的值比较"""
# 获取从添加数据以后被改动过数据的学生
from django.db.models import F
# SQL: select * from db_student where created_time=updated_time;
student_list = Student.objects.exclude(created_time=F("updated_time"))
print(student_list)
6.1.6.2 Q 查询
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询年龄大于20,并且编号小于30的学生
Student.objects.filter(age__gt=20,id__lt=30)
或
Student.filter(age__gt=20).filter(id__lt=30)
如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
Q(属性名__运算符=值)
Q(属性名__运算符=值) | Q(属性名__运算符=值)
例:查询年龄小于19或者大于20的学生,使用Q对象如下。
from django.db.models import Q
student_list = Student.objects.filter( Q(age__lt=19) | Q(age__gt=20) ).all()
6.1.6.3 聚合查询
使用aggregate()过滤器调用聚合函数。聚合函数包括:**Avg** 平均,**Count** 数量,**Max** 最大,**Min** 最小,**Sum** 求和,被定义在django.db.models中。
例:查询学生的平均年龄。
from django.db.models import Sum,Count,Avg,Max,Min
Student.objects.aggregate(Avg('age'))
注意:aggregate的返回值是一个字典类型,格式如下
{'属性名__聚合类小写':值}
使用count时一般不使用aggregate()过滤器。
例:查询学生总数。
Student.objects.count() # count函数的返回值是一个数字。
6.1.6.4 分组查询
QuerySet对象.annotate()
# annotate() 进行分组统计,按前面select 的字段进行 group by
# annotate() 返回值依然是 queryset对象,增加了分组统计后的键值对
模型对象.objects.values("id").annotate(course=Count('course__sid')).values('id','course')
# 查询指定模型, 按id分组 , 将course下的sid字段计数,返回结果是 name字段 和 course计数结果 # SQL原生语句中分组之后可以使用having过滤,在django中并没有提供having对应的方法,但是可以使用filter对分组结果进行过滤
# 所以filter在annotate之前,表示where,在annotate之后代表having
# 同理,values在annotate之前,代表分组的字段,在annotate之后代表数据查询结果返回的字段
6.1.6.5 原生查询
执行原生SQL语句,也可以直接跳过模型,才通用原生pymysql.
ret = Student.objects.raw("SELECT id,name,age FROM db_student") # student 可以是任意一个模型
# 这样执行获取的结果无法通过QuerySet进行操作读取,只能循环提取
print(ret,type(ret))
for item in ret:
print(item,type(item))
4.2 关联查询
基于双下划线查询(join查询)
ret = Student.objects.filter(name="张三").values("age")
# (1) 查询年龄大于22的学生的姓名以及所在名称班级
# 方式1 : Student作为基表
ret = Student.objects.filter(age__gt=22).values("name","clas__name")
# 方式2 :Clas表作为基表
ret = Clas.objects.filter(student_list__age__gt=22).values("student_list__name","name")
# (2) 查询计算机科学与技术2班有哪些学生
ret = Clas.objects.filter(name="计算机科学与技术2班").values("student_list__name")
# (3) 查询张三所报课程的名称
ret = Student.objects.filter(name="张三").values("courses__title")
print(ret) # <QuerySet [{'courses__title': '近代史'}, {'courses__title': '篮球'}]>
# (4) 查询选修了近代史这门课程学生的姓名和年龄
ret = Course.objects.filter(title="近代史").values("students__name","students__age")
# (5) 查询李四的手机号
ret = Student.objects.filter(name='李四').values("stu_detail__tel")
# (6) 查询手机号是110的学生的姓名和所在班级名称
# 方式1
ret = StudentDetail.objects.filter(tel="110").values("stu__name","stu__clas__name")
print(ret) # <QuerySet [{'stu__name': '张三', 'stu__clas__name': '计算机科学与技术2班'}]>
# 方式2:
ret = Student.objects.filter(stu_detail__tel="110").values("name","clas__name")
print(ret) # <QuerySet [{'name': '张三', 'clas__name': '计算机科学与技术2班'}]>
4.3 关联添加
- 一对多与一对一
stu = Student.objects.create(name="王五", clas_id=9, stu_detail_id=6)
- 多对多
# 添加多对多方式1
c1 = Course.objects.get(title="思修")
c2 = Course.objects.get(title="逻辑学")
stu.courses.add(c1,c2) # 添加多对多方式2
stu = Student.objects.get(name="张三")
stu.courses.add(5,7) # 添加多对多方式3
stu = Student.objects.get(name="李四")
stu.courses.add(*[6,7])
4.4 关联删除
# 删除多对多记录
stu = Student.objects.get(name="李四")
stu.courses.remove(7) # 清空多对多记录:clear方法
stu = Student.objects.get(name="rain")
stu.courses.clear() #重置多对多记录:set方法
stu = Student.objects.get(name="李四")
stu.courses.set([5,8])
5.django-模型ORM的更多相关文章
- Django 模型ORM
from django.db import models # Create your models here. class Book(models.Model): nid = models.AutoF ...
- 057.Python前端Django模型ORM多表查询
一 基于对象的查询 1.1 一对多查询 设计路由 from django.contrib import admin from django.urls import path from app01 im ...
- 055.Python前端Django模型ORM
由于前面在centos实验的过程中,pymql一直有属性错误,很难排查出问题,重新做了一个ubuntu的桌面系统同时使用pycharm开发工具作为学习开发工具,具体原因是因为在项目命名出现问题,和自己 ...
- 056.Python前端Django模型ORM多表基本操作
一 准备工作 1.1 新建一个项目 root@darren-virtual-machine:~# cd /root/PycharmProjects/ root@darren-virtual-machi ...
- python的Web框架,Django的ORM,模型基础,MySQL连接配置及增删改查
Django中的ORM简介 ORM概念:对象关系映射(Object Relational Mapping,简称ORM): 用面向对象的方式描述数据库,去操作数据库,甚至可以达到不用编写SQL语句就能够 ...
- 如何在Django模型中管理并发性 orm select_for_update
如何在Django模型中管理并发性 为单用户服务的桌面系统的日子已经过去了 - 网络应用程序现在正在为数百万用户提供服务,许多用户出现了广泛的新问题 - 并发问题. 在本文中,我将介绍在Django模 ...
- Django 06 Django模型基础1(ORM简介、数据库连接配置、模型的创建与映射、数据的增删改查)
Django 06 Django模型基础1(ORM简介.数据库连接配置.模型的创建与映射.数据的增删改查) 一.ORM系统 #django模型映射关系 #模型类-----数据表 #类属性-----表字 ...
- Django模型系统——ORM
一.概论 1.ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描 ...
- Django模型层之ORM
Django模型层之ORM操作 一 ORM简介 我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(如增.删.改.查),而一旦谈到数据的管理操作,就需要用到数据库管理软 ...
- django 模型层(orm)05
目录 配置测试脚本 django ORM基本操作 增删改查 Django 终端打印SQL语句 13条基本查询操作 双下滑线查询 表查询 建表 一对多字段数据的增删改查 多对多字段数据的增删改查 基于对 ...
随机推荐
- 专注效率提升「GitHub 热点速览 v.22.36」
本周最大的 GitHub 事件无疑是国内多家自媒体报道过的,GitHub 官方或将下架 GitHub Trending 页面.作为 GitHub Trending 长期用户,本周也是找到了实用且提升效 ...
- mysql8.0及以上修改Root密码
ALTER user 'root'@'localhost' IDENTIFIED BY 'Cliu123#' //1.不需要flush privileges来刷新权限. //2.密码要包含大写字母,小 ...
- LibTorch 多项分布
最近在学习过程中需要对服从某种分布的离散型随机变量进行抽样,在LibTroch中查到了torch::multinomial(多项分布),该方法的接口如下: at::Tensor multinomial ...
- 2021年3月-第01阶段-Linux基础-Linux系统的启动流程
Linux系统的启动流程 理解Linux操作系统启动流程,能有助于后期在企业中更好的维护Linux服务器,能快速定位系统问题,进而解决问题. 上图为Linux操作系统启动流程 1.加载BIOS 计算机 ...
- 线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
本文已参与「新人创作礼」活动,一起开启掘金创作之路. 线性模型简介 所谓线性模型就是通过数据的线性组合来拟合一个数据,比如对于一个数据 \(X\) \[X = (x_1, x_2, x_3, ..., ...
- PAT (Basic Level) Practice 1032 挖掘机技术哪家强 分数 20
为了用事实说明挖掘机技术到底哪家强,PAT 组织了一场挖掘机技能大赛.现请你根据比赛结果统计出技术最强的那个学校. 输入格式: 输入在第 1 行给出不超过 105 的正整数 N,即参赛人数.随后 N ...
- 微信小程序之发起请求
wx.request({ url: api.api + '/weChat/api/user/myAunt', // 仅为示例,并非真实的接口地址 data: {}, method: 'GET', he ...
- 洛谷P4630 [APIO2018] Duathlon 铁人两项 (圆方树)
圆方树大致理解:将每个点双看做一个新建的点(方点),该点双内的所有点(圆点)都向新建的点连边,最后形成一棵树,可以给点赋予点权,用以解决相关路径问题. 在本题中,方点点权赋值为该点双的大小,因为两个点 ...
- 在开发中关于javaweb中的路径问题小结
转自http://blog.csdn.net/yinyuehepijiu/article/details/9136117 在javaweb项目中添加配置文件,满足连接数据库配置参数以及其他自定义参数存 ...
- 编程架构演化史:远古时代,从打孔卡(Punched Card)开始
回想读书时记录到书本里的打孔纸带编程,到初学编程接触到的C语言高级编程,再到C++.Java面向对象语言产生:从面向过程系统设计 到面向对象系统设计:从三层结构到MVC.MVP.MVVM:从主机到虚拟 ...