DFA算法之内容敏感词过滤
DFA 算法是通过提前构造出一个 树状查找结构,之后根据输入在该树状结构中就可以进行非常高效的查找。
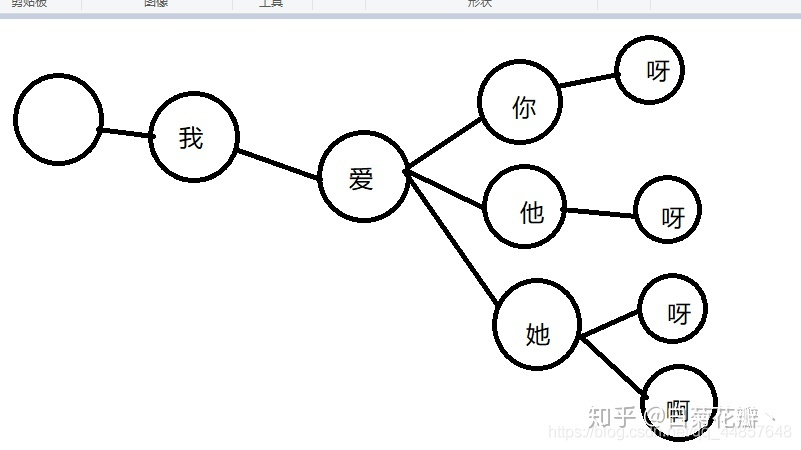
设我们有一个敏感词库,词酷中的词汇为:
我爱你
我爱他
我爱她
我爱你呀
我爱他呀
我爱她呀
我爱她啊
那么就可以构造出这样的树状结构:
设玩家输入的字符串为:白菊我爱你呀哈哈哈
我们遍历玩家输入的字符串 str,并设指针 i 指向树状结构的根节点,即最左边的空白节点:
str[0] = ‘白’ 时,此时 tree[i] 没有指向值为 ‘白’ 的节点,所以不满足匹配条件,继续往下遍历
str[1] = ‘菊’,同样不满足匹配条件,继续遍历
str[2] = ‘我’,此时 tree[i] 有一条路径连接着 ‘我’ 这个节点,满足匹配条件,i 指向 ‘我’ 这个节点,然后继续遍历
str[3] = ‘爱’,此时 tree[i] 有一条路径连着 ‘爱’ 这个节点,满足匹配条件,i 指向 ‘爱’,继续遍历
str[4] = ‘你’,同样有路径,i 指向 ‘你’,继续遍历
str[5] = ‘呀’,同样有路径,i 指向 ‘呀’
此时,我们的指针 i 已经指向了树状结构的末尾,即此时已经完成了一次敏感词判断。我们可以用变量来记录下这次敏感词匹配开始时玩家输入字符串的下标,和匹配结束时的下标,然后再遍历一次将字符替换为 * 即可。
结束一次匹配后,我们把指针 i 重新指向树状结构的根节点处。
此时我们玩家输入的字符串还没有遍历到头,所以继续遍历:
str[6] = ‘哈’,不满足匹配条件,继续遍历
str[7] = ‘哈’ …
str[8] = ‘哈’ …
可以看出我们遍历了一次玩家输入的字符串,就找到了其中的敏感词汇。
设玩家输入的字符串为:白菊我爱你呀哈哈哈
我们遍历玩家输入的字符串 str,并设指针 i 指向树状结构的根节点,即最左边的空白节点:
str[0] = ‘白’ 时,此时 tree[i] 没有指向值为 ‘白’ 的节点,所以不满足匹配条件,继续往下遍历
str[1] = ‘菊’,同样不满足匹配条件,继续遍历
str[2] = ‘我’,此时 tree[i] 有一条路径连接着 ‘我’ 这个节点,满足匹配条件,i 指向 ‘我’ 这个节点,然后继续遍历
str[3] = ‘爱’,此时 tree[i] 有一条路径连着 ‘爱’ 这个节点,满足匹配条件,i 指向 ‘爱’,继续遍历
str[4] = ‘你’,同样有路径,i 指向 ‘你’,继续遍历
str[5] = ‘呀’,同样有路径,i 指向 ‘呀’
此时,我们的指针 i 已经指向了树状结构的末尾,即此时已经完成了一次敏感词判断。我们可以用变量来记录下这次敏感词匹配开始时玩家输入字符串的下标,和匹配结束时的下标,然后再遍历一次将字符替换为 * 即可。
结束一次匹配后,我们把指针 i 重新指向树状结构的根节点处。
此时我们玩家输入的字符串还没有遍历到头,所以继续遍历:
str[6] = ‘哈’,不满足匹配条件,继续遍历
str[7] = ‘哈’ …
str[8] = ‘哈’ …
可以看出我们遍历了一次玩家输入的字符串,就找到了其中的敏感词汇。
DFA算法python实现:
1 class DFA:
2 """DFA 算法
3 敏感字中“*”代表任意一个字符
4 """
5
6 def __init__(self, sensitive_words: list, skip_words: list): # 对于敏感词sensitive_words及无意义的词skip_words可以通过数据库、文件或者其他存储介质进行保存
7 self.state_event_dict = self._generate_state_event(sensitive_words)
8 self.skip_words = skip_words
9
10 def __repr__(self):
11 return '{}'.format(self.state_event_dict)
12
13 @staticmethod
14 def _generate_state_event(sensitive_words) -> dict:
15 state_event_dict = {}
16 for word in sensitive_words:
17 tmp_dict = state_event_dict
18 length = len(word)
19 for index, char in enumerate(word):
20 if char not in tmp_dict:
21 next_dict = {'is_end': False}
22 tmp_dict[char] = next_dict
23 tmp_dict = next_dict
24 else:
25 next_dict = tmp_dict[char]
26 tmp_dict = next_dict
27 if index == length - 1:
28 tmp_dict['is_end'] = True
29 return state_event_dict
30
31 def match(self, content: str):
32 match_list = []
33 state_list = []
34 temp_match_list = []
35
36 for char_pos, char in enumerate(content):
37 if char in self.skip_words:
38 continue
39 if char in self.state_event_dict:
40 state_list.append(self.state_event_dict)
41 temp_match_list.append({
42 "start": char_pos,
43 "match": ""
44 })
45 for index, state in enumerate(state_list):
46 is_match = False
47 state_char = None
48 if '*' in state: # 对于一些敏感词,比如大傻X,可能是大傻B,大傻×,大傻...,采用通配符*,一个*代表一个字符
49 state_list[index] = state['*']
50 state_char = state['*']
51 is_match = True
52 if char in state:
53 state_list[index] = state[char]
54 state_char = state[char]
55 is_match = True
56 if is_match:
57 if state_char["is_end"]:
58 stop = char_pos + 1
59 temp_match_list[index]['match'] = content[
60 temp_match_list[index]['start']:stop]
61 match_list.append(copy.deepcopy(temp_match_list[index]))
62 if len(state_char.keys()) == 1:
63 state_list.pop(index)
64 temp_match_list.pop(index)
65 else:
66 state_list.pop(index)
67 temp_match_list.pop(index)
68 for index, match_words in enumerate(match_list):
69 print(match_words['start'])
70 return match_list
_generate_state_event方法生成敏感词的树状结构,(以字典保存),对于上面的例子,生成的树状结构保存如下:
if __name__ == '__main__':
dfa = DFA(['我爱你', '我爱他', '我爱她', '我爱你呀', '我爱他呀', '我爱她呀', '我爱她啊'], skip_words=[]) # 暂时不配置skip_words
print(dfa)
结果:
{'我': {'is_end': False, '爱': {'is_end': False, '你': {'is_end': True, '呀': {'is_end': True}}, '他': {'is_end': True, '呀': {'is_end': True}}, '她': {'is_end': True, '呀': {'is_end': True}, '啊': {'is_end': True}}}}}
然后调用match方法,输入内容进行敏感词匹配:
if __name__ == '__main__':
dfa = DFA(['我爱你', '我爱他', '我爱她', '我爱你呀', '我爱他呀', '我爱她呀', '我爱她啊'], ['\n', '\r\n', '\r'])
# print(dfa)
print(dfa.match('白菊我爱你呀哈哈哈'))
结果:
[{'start': 2, 'match': '我爱你'}, {'start': 2, 'match': '我爱你呀'}]
而对于一些敏感词,比如大傻X,可能是大傻B,大傻×,大傻...,那是不是可以通过一个通配符*来解决?
见代码:48 ~51行
48 if '*' in state: # 对于一些敏感词,比如大傻X,可能是大傻B,大傻×,大傻...,采用通配符*,一个*代表一个字符
49 state_list[index] = state['*']
50 state_char = state['*']
51 is_match = True
验证一下:
if __name__ == '__main__':
dfa = DFA(['大傻*'], [])
print(dfa)
print(dfa.match('大傻X安乐飞大傻B'))
结果:
{'大': {'is_end': False, '傻': {'is_end': False, '*': {'is_end': True}}}}
[{'start': 0, 'match': '大傻X'}, {'start': 6, 'match': '大傻B'}]
上列中如果输入的内容中,“大傻X安乐飞大傻B”写成“大%傻X安乐飞大&傻B”,看看是否能识别出敏感词呢?识别不出了!
if __name__ == '__main__':
dfa = DFA(['大傻*'], [])
print(dfa)
print(dfa.match('大%傻X安乐飞大&傻B'))
结果:
{'大': {'is_end': False, '傻': {'is_end': False, '*': {'is_end': True}}}}
[
诸如“,&,!,!,@,#,$,¥,*,^,%,?,?,<,>,《,》",这些特殊符号无实际意义,但是可以在敏感词中间插入而破坏敏感词的结构规避敏感词检查
进行无意义词配置,再进行敏感词检查,如下,可见对于被破坏的敏感词也能识别
if __name__ == '__main__':
dfa = DFA(['大傻*'], ['%', '&'])
print(dfa)
print(dfa.match('大%傻X安乐飞大&傻B'))
结果:
{'大': {'is_end': False, '傻': {'is_end': False, '*': {'is_end': True}}}}
[{'start': 0, 'match': '大%傻X'}, {'start': 7, 'match': '大&傻B'}]
DFA算法之内容敏感词过滤的更多相关文章
- Java实现敏感词过滤 - IKAnalyzer中文分词工具
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包. 官网: https://code.google.com/archive/p/ik-analyzer/ 本用例借助 I ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- 基于DFA算法、RegExp对象和vee-validate实现前端敏感词过滤
面临敏感词过滤的问题,最简单的方案就是对要检测的文本,遍历所有敏感词,逐个检测输入的文本是否包含指定的敏感词. 很明显上面这种实现方法的检测时间会随着敏感词库数量的增加而线性增加.系统会因此面临性能和 ...
- Java实现敏感词过滤 - DFA算法
Java实现DFA算法进行敏感词过滤 封装工具类如下: 使用前需对敏感词库进行初始化: SensitiveWordUtil.init(sensitiveWordSet); package cn.swf ...
- 敏感词过滤的算法原理之DFA算法
参考文档 http://blog.csdn.net/chenssy/article/details/26961957 敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有 ...
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- 超强敏感词过滤算法第二版 可以忽略大小写、全半角、简繁体、特殊符号、HTML标签干扰
上一篇 发一个高性能的敏感词过滤算法 可以忽略大小写.全半角.简繁体.特殊符号干扰 改进主要有几点: 用BitArray取代Dictionary用空间换时间 性能进一步提升 大概会增加词库的 6k* ...
- 浅析敏感词过滤算法(C++)
为了提高查找效率,这里将敏感词用树形结构存储,每个节点有一个map成员,其映射关系为一个string对应一个TreeNode. STL::map是按照operator<比较判断元素是否相同,以及 ...
- java实现文章敏感词过滤检测
SensitivewordFilter.java import java.util.HashSet; import java.util.Iterator; import java.util.Map; ...
随机推荐
- MATLAB批量打印输出600PPI的图像且图像不留空白
一 前言 最近收到审稿人的修改意见,其中有三条:一条为<RC: There were only five images evaluated in the experiment, and I re ...
- matplotlib字体
matplotlib官方文档 https://matplotlib.org/stable/gallery/index.html 使用以下代码查看 import matplotlib.pyplot as ...
- 使用git clone 报错curl56 errno 10054解决方法
使用git clone 报错curl56 errno 10054解决方法 ----------------版权声明:本文为CSDN博主「伽马射线爆」的原创文章,遵循CC 4.0 BY-SA版权协议,转 ...
- OpenSSL实现了5种信息摘要算法有哪些?
OpenSSL实现了5种信息摘要算法,分别是MD2.MD5.MDC2.SHA(SHA1)和RIPEMD.SHA算法事实上包括了SHA和SHA1两种信息摘要算法.此外,OpenSSL还实现了DSS标准中 ...
- Redis的安装与启动(一)
Redis是c语言开发的. 安装redis需要c语言的编译环境.如果没有gcc需要在线安装.yum install gcc-c++ 安装步骤: 第一步:redis的源码包上传到linux系统.--源码 ...
- Springmvc入门基础(六) ---拦截器应用demo
1.拦截器定义 Spring Web MVC 的处理器拦截器类似于Servlet 开发中的过滤器Filter,用于对处理器进行预处理和后处理. 2.拦截器demo demo需求: 拦截用户请求,判断用 ...
- Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法?
1.64 GB 内存的机器是非常理想的, 但是 32 GB 和 16 GB 机器也是很常见的.少于 8 GB 会适得其反. 2.如果你要在更快的 CPUs 和更多的核心之间选择,选择更多的核心更好.多 ...
- centos 7环境下安装rabbitmq
以 前在windows 7下面成功安装过rabbitmq,但是在windows 10下面安装失败,各种问题,各种解决方法都试过,还是不成功,最终放弃治疗. 后来经人指点,在linux下安装rabbit ...
- freeswitch对接WEBRTC的一个candidate问题
概述 近几年,WEBRTC的完善与成熟,使得网页上使用webrtc的应用越来越多. Freeswitch是一个开源的软交换平台,可以直接支持webrtc的对接方式. 最近在测试fs和webrtc的对接 ...
- 9_状态观测器设计_Linear Observer Design_Matlab_Simulink建模(上)