论文解读(MaskGAE)《MaskGAE: Masked Graph Modeling Meets Graph Autoencoders》
论文信息
论文标题:MaskGAE: Masked Graph Modeling Meets Graph Autoencoders
论文作者:Jintang Li, Ruofan Wu, Wangbin Sun, Liang Chen, Sheng Tian......
论文来源:2022,arXiv
论文地址:download
论文代码:download
1 Introduction
MAE 在图上的应用——2022 最潮的方法。
2 Related work and Motivation
2.1 GAE
GAEs采用了经典的编码器-解码器框架,旨在通过优化以下二进制交叉熵损失,从编码图的低维表示中进行解码:
$\mathcal{L}_{\mathrm{GAEs}}=-\left(\frac{1}{\left|\mathcal{E}^{+}\right|} \sum\limits _{(u, v) \in \mathcal{E}^{+}} \log h_{\omega}\left(z_{u}, z_{v}\right)+\frac{1}{\left|\mathcal{E}^{-}\right|} \sum\limits _{\left(u^{\prime}, v^{\prime}\right) \in \mathcal{E}^{-}} \log \left(1-h_{\omega}\left(z_{u^{\prime}}, z_{v^{\prime}}\right)\right)\right)$
其中,$\mathcal{z}$ 代表低维隐表示,$f_{\theta}$ 代表参数为 $\theta$ 的 GNN encoder,$h_{\omega}$ 代表参数为 $\omega$ 的 GNN decoder,$\mathcal{E}^{+}$ 代表 positive edges ,$\mathcal{E}^{-}$ 代表 negative edges 。
2.2 Motivation
按照互信息的思想:希望最大化 k-hop 节点对子图之间的一致性,但是伴随着 $K$ 值变大,过平滑的问题越发明显,此时子图大小对节点表示的学习不利。因此有:

分析了一堆废话................
后面呢,必然出现解决过平滑的策略。
Recall:解决过平湖的策略
- 残差;
- 谱图理论;
- 多尺度信息;
- 边删除;
3 Method:MaskGAE
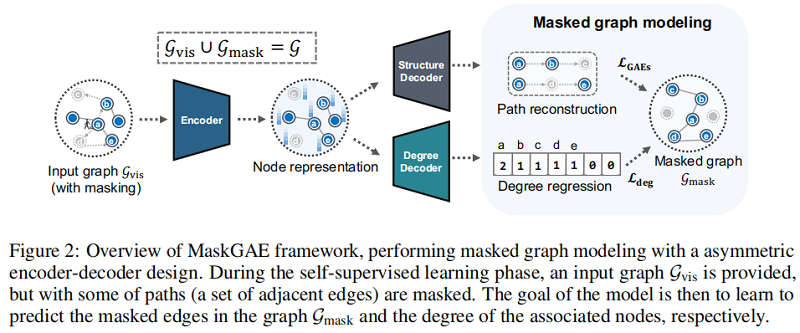
出发点:MGM
$\mathcal{G}_{\text {mask }} \cup \mathcal{G}_{\text {vis }}=\mathcal{G}$
$\mathcal{G}_{\text {mask }}= \left(\mathcal{E}_{\text {mask }}, \mathcal{V}\right)$
3.1 Masking strategy
Edge-wise random masking $(\mathcal{T}_{\text {edge }}$
$\mathcal{E}_{\text {mask }} \sim \operatorname{Bernoulli}(p)$
Path-wise random masking $(\mathcal{T}_{\text {path}}$
$\mathcal{E}_{\text {mask }} \sim \operatorname{Random} \operatorname{Walk}\left(\mathcal{R}, n_{\text {walk }}, l_{\text {walk }}\right)$
其中,$\mathcal{R} \subseteq \mathcal{V}$ 是从图中采样的一组根节点,$n_{\text {walk }}$ 为每个节点的行走次数,$l_{\text {walk }}$ 为行走长度。
在这里,我们遵循度分布,抽样了一个节点的子集(例如,50%),没有替换作为根节点 $\mathcal{R}$。这样的采样也可以防止图中存在的潜在的长尾偏差(即,更多的屏蔽边是那些属于高度节点的边)。
3.2 Encoder
- GCN Encoder
- SAGE Encoder
- GAT Encoder
3.2 Decoder
$h_{\omega}\left(z_{i}, z_{j}\right)=\operatorname{Sigmoid}\left(z_{i}^{\mathrm{T}} z_{j}\right)$
$h_{\omega}\left(z_{i}, z_{j}\right)=\operatorname{Sigmoid}\left(\operatorname{MLP}\left(z_{i} \circ z_{j}\right)\right)$
$g_{\phi}\left(z_{v}\right)=\operatorname{MLP}\left(z_{v}\right)$
3.3 Learning objective
损失函数包括:
- Reconstruction loss:计算的是掩码边 $\mathcal{E}^{+}=\mathcal{E}_{\text {mask }}$ 的重构损失;
- Regression loss:衡量的是节点度的预测与掩蔽图中原始节点度的匹配程度:
$\mathcal{L}_{\mathrm{deg}}=\frac{1}{|\mathcal{V}|} \sum\limits _{v \in \mathcal{V}}\left\|g_{\phi}\left(z_{v}\right)-\operatorname{deg}_{\text {mask }}(v)\right\|_{F}^{2}$
因此,总体损失为:
$\mathcal{L}=\mathcal{L}_{\mathrm{GAEs}}+\alpha \mathcal{L}_{\mathrm{deg}}$
4 Experiments
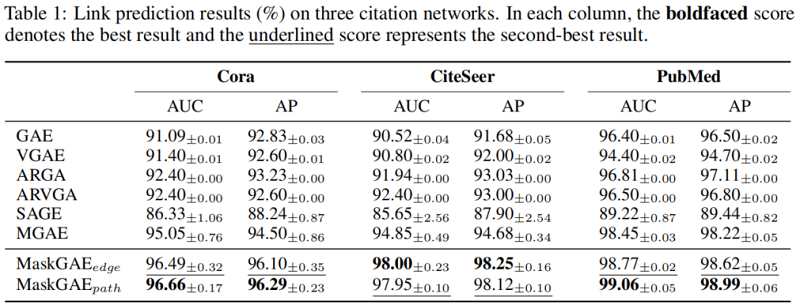
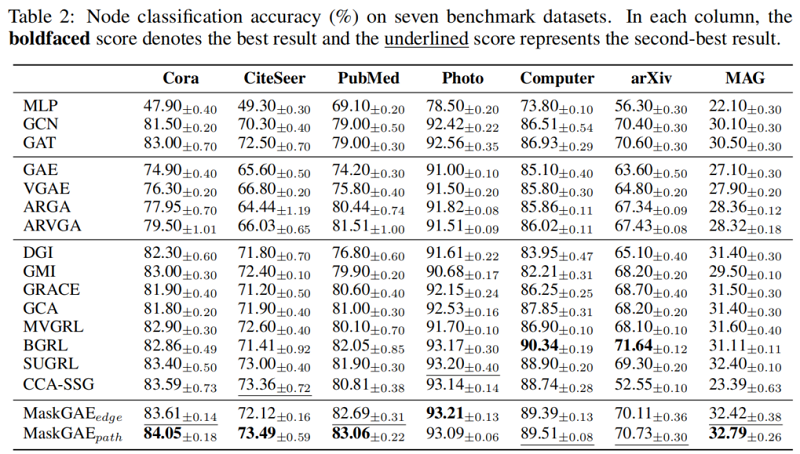
5 Conclusion
论文解读(MaskGAE)《MaskGAE: Masked Graph Modeling Meets Graph Autoencoders》的更多相关文章
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(GraRep)《GraRep: Learning Graph Representations with Global Structural Information》
论文题目:<GraRep: Learning Graph Representations with Global Structural Information>发表时间: CIKM论文作 ...
- 论文解读(MCGC)《Multi-view Contrastive Graph Clustering》
论文信息 论文标题:Multi-view Contrastive Graph Clustering论文作者:Erlin Pan.Zhao Kang论文来源:2021, NeurIPS论文地址:down ...
- 论文解读(CGC)《CGC: Contrastive Graph Clustering for Community Detection and Tracking》
论文信息 论文标题:CGC: Contrastive Graph Clustering for Community Detection and Tracking论文作者:Namyong Park, R ...
- 论文解读(GROC)《Towards Robust Graph Contrastive Learning》
论文信息 论文标题:Towards Robust Graph Contrastive Learning论文作者:Nikola Jovanović, Zhao Meng, Lukas Faber, Ro ...
- 论文解读(DAGNN)《Towards Deeper Graph Neural Networks》
论文信息 论文标题:Towards Deeper Graph Neural Networks论文作者:Meng Liu, Hongyang Gao, Shuiwang Ji论文来源:2020, KDD ...
- 论文解读(SCGC))《Simple Contrastive Graph Clustering》
论文信息 论文标题:Simple Contrastive Graph Clustering论文作者:Yue Liu, Xihong Yang, Sihang Zhou, Xinwang Liu论文来源 ...
- 论文解读(Geom-GCN)《Geom-GCN: Geometric Graph Convolutional Networks》
Paper Information Title:Geom-GCN: Geometric Graph Convolutional NetworksAuthors:Hongbin Pei, Bingzhe ...
随机推荐
- Blazor和Vue对比学习(基础1.5):双向绑定
这章我们来学习,现代前端框架中最精彩的一部分,双向绑定.除了掌握原生HTML标签的双向绑定使用,我们还要在一个自定义的组件上,手撸实现双向绑定.双向绑定,是前两章知识点的一个综合运用(父传子.子传父) ...
- Web安全学习笔记 SQL注入下
Web安全学习笔记 SQL注入下 繁枝插云欣 --ICML8 SQL注入小技巧 CheatSheet 预编译 参考文章 一点心得 一.SQL注入小技巧 1. 宽字节注入 一般程序员用gbk编码做开发的 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- C# .NET ML.NET 机器学习 图像分类
一. 准备工作 IDE是 VS2019.先下载好"resnet_v2_50_299.meta"这个文件,放入"C:\Users\jk\AppData\Local\Temp ...
- .net 获取IP地址的几种方式
1.获取服务器IP地址: 1) Local_Addr var Local_Addr = Request.ServerVariables.Get("Local_Addr").ToSt ...
- Python Selenium库
Selenium库 自动化测试工具,支持多种游览器 爬虫中主要用来解决JavaScript渲染的问题 安装Selenium pip3 install selenium 安装游览器驱动 下载驱动地址:h ...
- 支付宝开放平台--网页&移动应用(一)
前提是先在支付宝上签约自己需要的支付宝功能,然后支付宝开放平台才能设置你需要的功能 一:支付宝开放平台登录 登录进入支付宝开放平台 二:根据自己的需求创建应用(我是用的网页&移动应用) 三:点 ...
- Node.js精进(2)——异步编程
虽然 Node.js 是单线程的,但是在融合了libuv后,使其有能力非常简单地就构建出高性能和可扩展的网络应用程序. 下图是 Node.js 的简单架构图,基于 V8 和 libuv,其中 Node ...
- C#中常用的目录|文件|路径信息操作
更新记录 本文迁移自Panda666原博客,原发布时间:2021年5月16日. 说明 .NET的类库API设计的非常优秀,再加上文档docs.com写的非常优秀,写代码给人一种十分优雅的感觉. 获得当 ...
- css做旋转相册效果
css做旋转相册效果 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> &l ...